- 1.引言
- 2.对比学习简介
- 3.对比学习在CV领域的应用
- SimCLR (2020 Feb)-Batch内负例">3.1 SimCLR (2020 Feb)-Batch内负例
- 3.2 Moco-Batch外负例
- 3.3 SwAV-对比聚类
- 3.4 非对称结构:模型不坍塌之谜
- 3.5 Decouple Contrastive Learning
- 4.对比学习在NLP领域的应用
- 5.对比学习的思考和疑问
- 6.大厂关于对比学习实践
- 7.对比学习个人实践
- 总结
- 参考
layout: post
title: 语义匹配前言:对比学习
subtitle: 语义匹配前言:对比学习
date: 2021-11-09
author: NSX
header-img: img/post-bg-ios9-web.jpg
catalog: true
tags:
- 对比学习
1.引言
近两年,对比学习(Contrastive Learning)在计算机视觉领域(CV)掀起了一波浪潮,MoCo[1]、SimCLR[2]、BYOL[3]、SimSiam[4]等基于对比学习思想的模型方法层出不穷,作为一种无监督表示学习方法,在CV的一些任务上的表现已经超过了有监督学习。同时,自然语言处理(NLP)领域近来也有了一些跟进的工作,例如ConSERT[5]、SimCSE[6]等模型利用对比学习思想进行句表示学习,在语义文本相似度匹配(STS)等任务上超过了SOTA。这篇笔记将带大家梳理一下对比学习的基本思想与方法,回顾一下CV领域对比学习的发展历程,并介绍几篇对比学习应用在NLP领域文本表示学习中的工作。
2.对比学习简介
2.1 基本思想
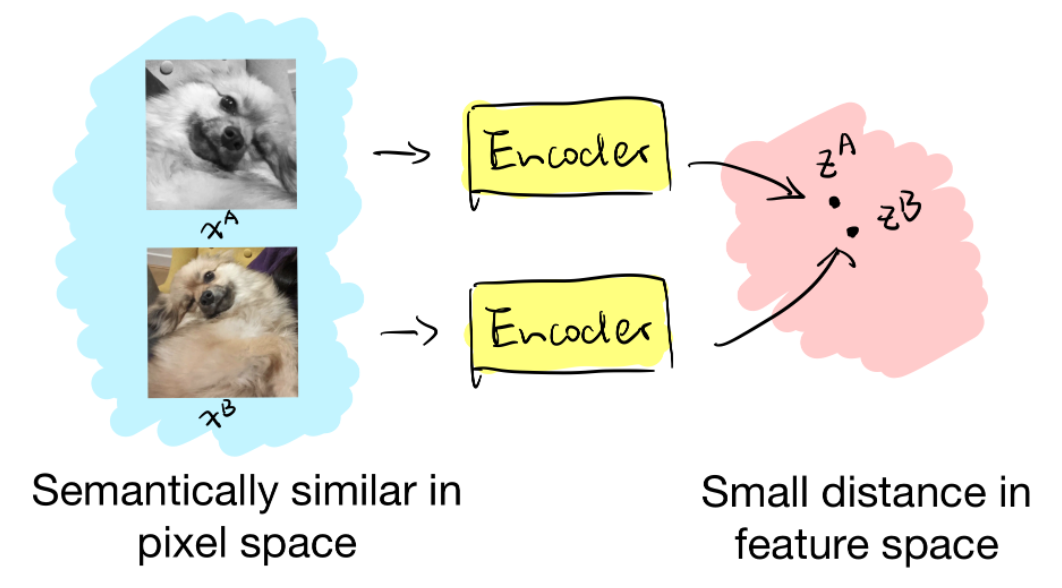
在介绍对比学习的具体方法之前,让我们先了解下什么是对比学习?对比学习它最大的技术源泉来自于度量学习(Metric Learning),你要看的话,会发现它的运作流程,基本就是度量学习的流程。什么意思呢?度量学习的优化目标就是说:比如我有正例和负例,它要将实体映射到一个空间里面去。它的目标是让正例在空间中近一些,负例在空间中远一些,这是度量学习的一个主体思想。其实对比学习从框架上来讲,基本就是度量学习上述思想。
另外一方面,对比学习的提出,包括这两年的兴起,我觉得很大的刺激因素是来自于BERT。因为我们知道BERT在NLP里面效果特别好,它是通过自监督的方式,在BERT预训练模型的时候,是把输入的句子随机扣掉一定比例的单词,然后让模型去准确地预测这些词。这是典型的自监督的模式,就是说不用人工来构造训练数据,可以根据一些规则自动构造训练数据。因为BERT效果特别好,我的理解是很多做图像领域的学者受到这件事的启发,所以就拿度量学习的框架再加上自监督学习的思路,来构造对比学习。所以说,你可以把对比学习理解为自监督版本的度量学习。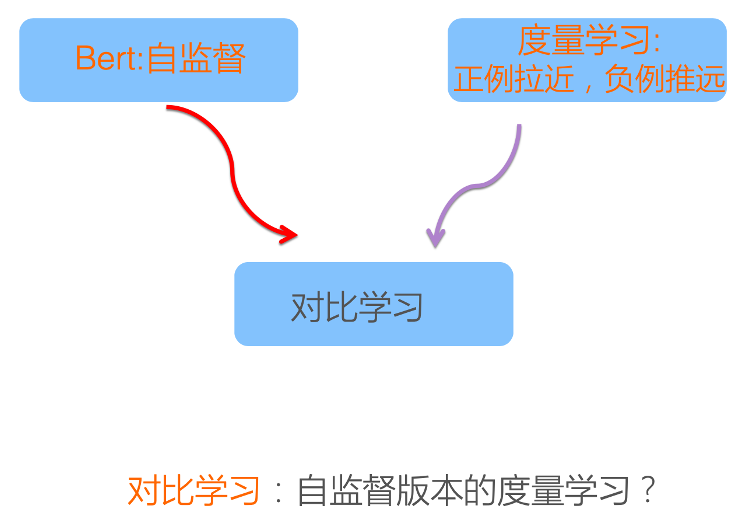
2.2 自监督学习分类
自监督可以分为两种类型:生成式自监督学习,判别式自监督学习。VAE和GAN是生成式自监督学习的两类典型方法,即它要求模型重建图像或者图像的一部分,这类型的任务难度相对比较高,要求像素级的重构,中间的图像编码必须包含很多细节信息。对比学习则是典型的判别式自监督学习,相对生成式自监督学习,对比学习的任务难度要低一些。
2.3 对比学习的指导原则以及构建模型的三个关键问题
目前,对比学习貌似处于“无明确定义、有指导原则”的状态,它的指导原则是:通过自动构造相似实例和不相似实例,要求习得一个表示学习模型,通过这个模型,使得相似的实例在投影空间中比较接近,而不相似的实例在投影空间中距离比较远。
明确了对比学习的指导原则,要构建对比学习模型就需要解决三个关键问题:第一个问题是:正例怎么构造?对于对比学习来说,原则上正例应该是自动构造出的,也就是自监督的方式构造的。负例怎么构造?一般来说负例好选,通常就是随机选的。第二个关键问题是Encoder映射函数,也即如何构造能够遵循上述指导原则的表示学习模型结构?第三个问题是Loss function怎么设计?即如何防止模型坍塌(Modal Collapse)。至于这个防止模型坍塌就是要让相似的实例在投影的空间中尽可能接近,不相似的尽可能远离。如果模型坍塌了,那么可能所有的实例都映射到了一个点,也就是一个常数。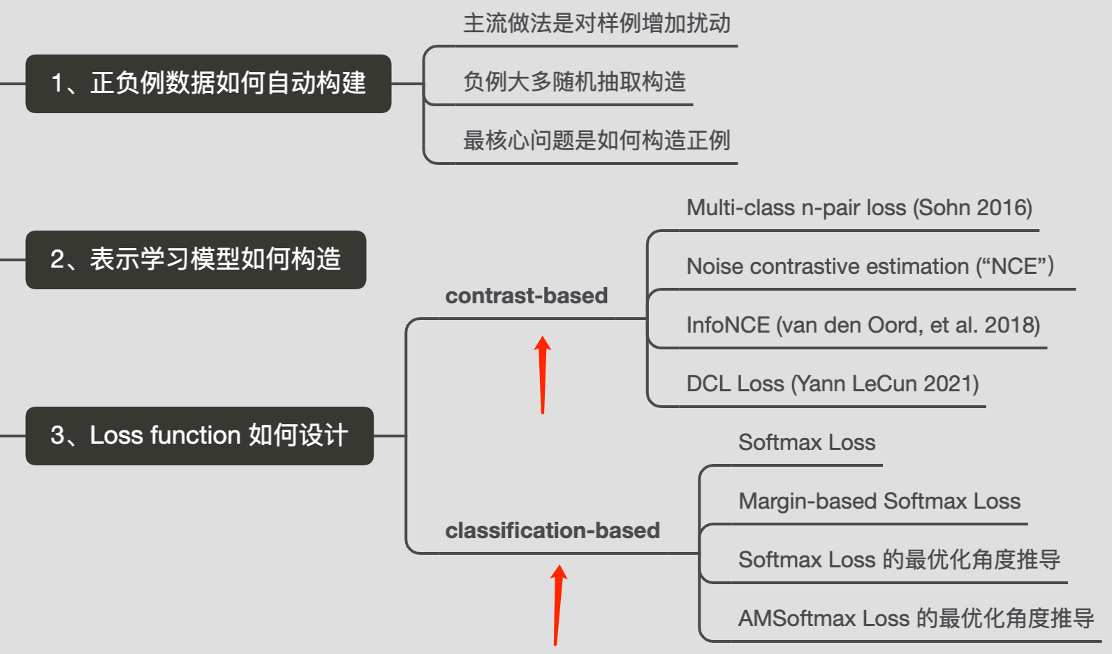
2.4 正负样例
回顾2.3节说到的对比学习最关键的是三个问题:正负样例、对比损失以及模型结构。模型结构将在第三章介绍具体工作时详解介绍,先来聊一聊正负样例和对比损失。
一般对比学习的负例大多可以通过随机抽取构造,所以对比学习中最核心的问题是如何构造正例。
- 数据增强:目前正例构造是对样例进行数据增强/扰动来得到更多正样本,而不是通过人工标注的数据(也就是有监督的方式)。正确有效的数据增强技术对于学习好的表征至关重要。比如SimCLR的实验表明,图片的随机裁剪和颜色失真是最有效的两种方式。而对于句子来说,删除或替换可能会导致语义的改变。
- 负样本构造:一般对比学习中使用in-batch negatives,将一个batch内的不相关数据看作负样本。
- 注意,使用大的batch size是许多对比学习方法成功的一个关键因素。当batch size足够大时,能够提供大量的负样本,使得模型学习更好表征来区别不同样本。
图像领域中的扰动大致可分为两类:空间/几何扰动和外观/色彩扰动。空间/几何扰动的方式包括但不限于图片翻转(flip)、图片旋转(rotation)、图片挖剪(cutout)、图片剪切并放大(crop and resize)。外观扰动包括但不限于色彩失真、加高斯噪声等,见图4的例子。

自然语言领域的扰动也大致可分为两类:词级别(token-level)和表示级别(embedding-level)。词级别的扰动大致有句子剪裁(crop)、删除词/词块(span)、换序、同义词替换等。表示级别的扰动包括加高斯噪声、dropout等。见图5。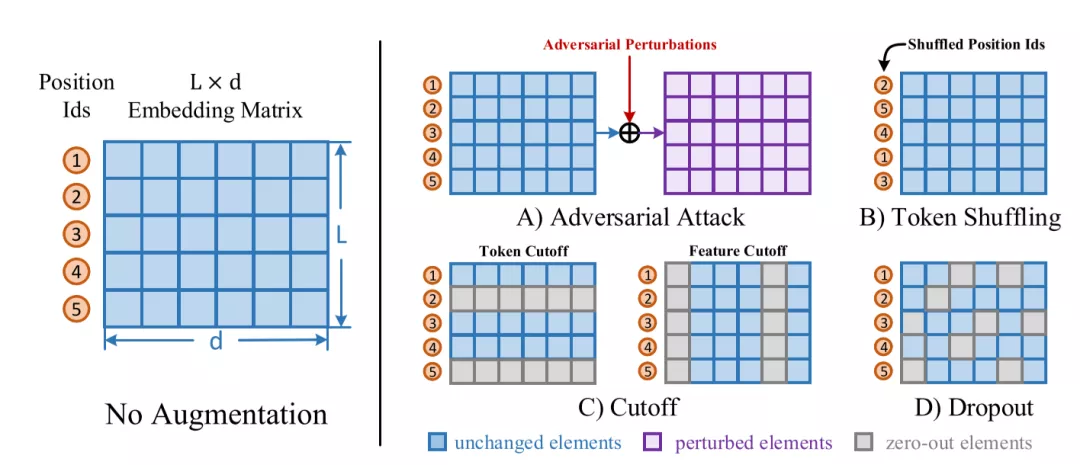
2.5 对比损失
在有了正负例之后,我们需要给模型信号,激励他们拉近正样例间的距离,拉远负样例间的距离,这就要通过设计对比损失来完成。给定一个样例 和它对应的正样例
以及负样例
(N可以为1,也可以很大),我们需要一个表示函数
,以及一个距离的度量函数
。表示函数即由我们定义的模型得到,至于度量函数,最简单的自然是欧几里得距离:
%3D%7C%7Cx_1%C2%B7x_2%7C%7C_2#card=math&code=D%28x_1%29%3D%7C%7Cx_1%C2%B7x_2%7C%7C_2&id=wRzxS)。不过在对比学习中一般会将表示归一化为长度为1的向量,故欧几里得距离与向量内积就相差一常数项,为计算方便,通常就用内积作为距离度量,即:
%3Dx_1%C2%B7x_2#card=math&code=D%28x_1%29%3Dx_1%C2%B7x_2&id=Pqqum),也可叫做余弦距离。有了这些准备工作,我们就可以定义对比损失。
- 原始对比损失
其实对比思想并不是近来才兴起,05、06年就有工作用对比思想做度量学习和数据降维。给定一个样例对 #card=math&code=%28x_1%2Cx_2%29&id=seBlo),我们有标签
,
代表样例对互为正例,
代表样例对互为负例。进而定义了对比损失:
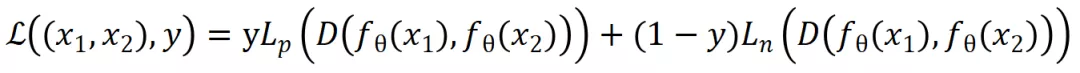
其中,#card=math&code=D%28%29&id=vtV1S) 为距离度量函数,
#card=math&code=L_p%28%29&id=uU5RA) 为一递增函数,
#card=math&code=L_n%28%29&id=WLepv) 为一递减函数。当互为正例时,距离越远损失越高;互为负例时,距离越近损失越高。文献[8]中,
%3D1%2F2x%5E2#card=math&code=L_p%28x%29%3D1%2F2x%5E2&id=OrKu5) ,
%3D1%2F2(max%5C%7B0%2Cm-x%5C%7D)%5E2#card=math&code=L_n%28x%29%3D1%2F2%28max%5C%7B0%2Cm-x%5C%7D%29%5E2&id=gtuSu) ;文献[11]中,
%3Dx%5E2#card=math&code=L_p%28x%29%3Dx%5E2&id=Uthp2) ,
%3D(max%5C%7B0%2Cm-x%5C%7D)%5E2#card=math&code=L_n%28x%29%3D%28max%5C%7B0%2Cm-x%5C%7D%29%5E2&id=lBNza),
是超参,控制负例的范围。用平方是因为他们的距离度量为欧几里得距离,平方可以规避开方操作。
%5E2%2B(1-y)(max(0%2Cm-D(%C2%B7)))%5E2%0A#card=math&code=L%3DyD%28%C2%B7%29%5E2%2B%281-y%29%28max%280%2Cm-D%28%C2%B7%29%29%29%5E2%0A&id=ukGGH)
- 三元组损失(triplet loss)
相信很多人对triplet loss 很熟悉了,最初是FaceNet[12]做人脸表示学习时提出的:给定一个三元组 #card=math&code=%28x%2Cx%5E%2B%2Cx%5E-%29&id=LMV6r),
被称做锚点(Anchor),
为正例,
为负例。triplet loss设计的初衷也是希望通过对比使得锚点与正例的距离更近,与负例更远,具体形式为:
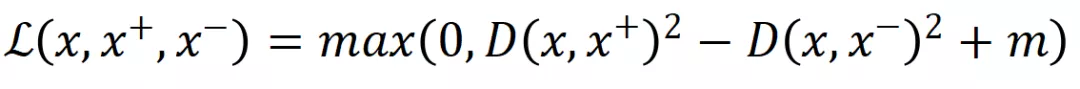
其中 #card=math&code=D%28%29&id=VQ61Y) 为欧几里得距离,
是用来控制正例负例距离间的偏离量,使模型不需要考虑优化过于简单的负例。论文还指出,挑选真正有挑战的负例对提升模型表现非常重要。
虽然triplet loss已经满足了对比学习的要求,但是他把一个样例限定在了一个三元组中,一个正例只与一个负例对比。实际操作中,对一个样例,我们能得到的负样例个数远远多于正样例,为了利用这些资源,近年来对比学习多用InfoNCE损失(还有其它类型的对比损失,这里只介绍主流做法)。
- N-pair Loss
N-pair Loss(Multi-Class N-pair loss)拓展了Triplet Loss,泛化到与多个负样本进行对比。
- NCE 损失
NCE(Noise Contrastive Estimation)全称是噪声对比估计,是估计统计模型参数的一种方法,主要通过学习数据分布和噪声分布之间的区别。
(NCE) 将概率估计问题(多分类)转化为二分类问题,判别给定样例是来源于原始分布还是噪声分布,用二分类的最大似然估计替代原始问题。核心思想是通过逻辑回归(logistic regression)对数据与噪声进行二分类,利用已知的噪声概率分布,来估计未知的经验概率分布。听起来好像跟对比学习没什么关系,但如果把噪音分布的样本想成负样例,那这个二元分类问题就可以理解为让模型对比正负样例作出区分进而学习到正样例(原始分布)的分布特征,这是不是就跟对比学习的思想很像了?
假设目标样本分布  ,采样的噪声分布
,采样的噪声分布  ,通过估计
,通过估计  来最终估计出
来最终估计出  的参数 θ ,并让这些数据的最大似然概率最大。最终的对数似然函数:(x 表示数据,y 表示噪声)
的参数 θ ,并让这些数据的最大似然概率最大。最终的对数似然函数:(x 表示数据,y 表示噪声)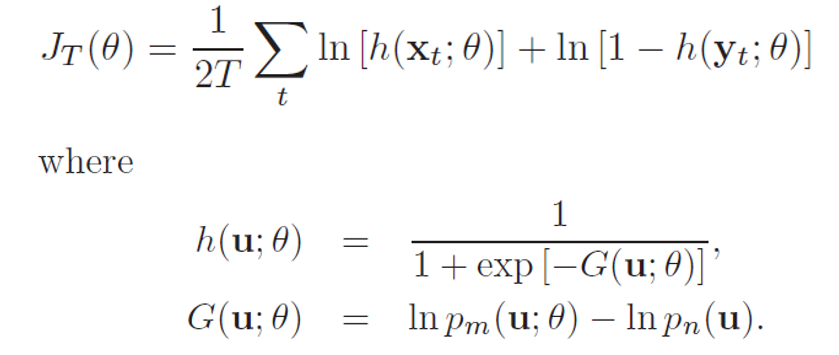
NCE 常被用于解决多分类问题下 softmax 分母归一化中类别太多计算量太大,难以求值的问题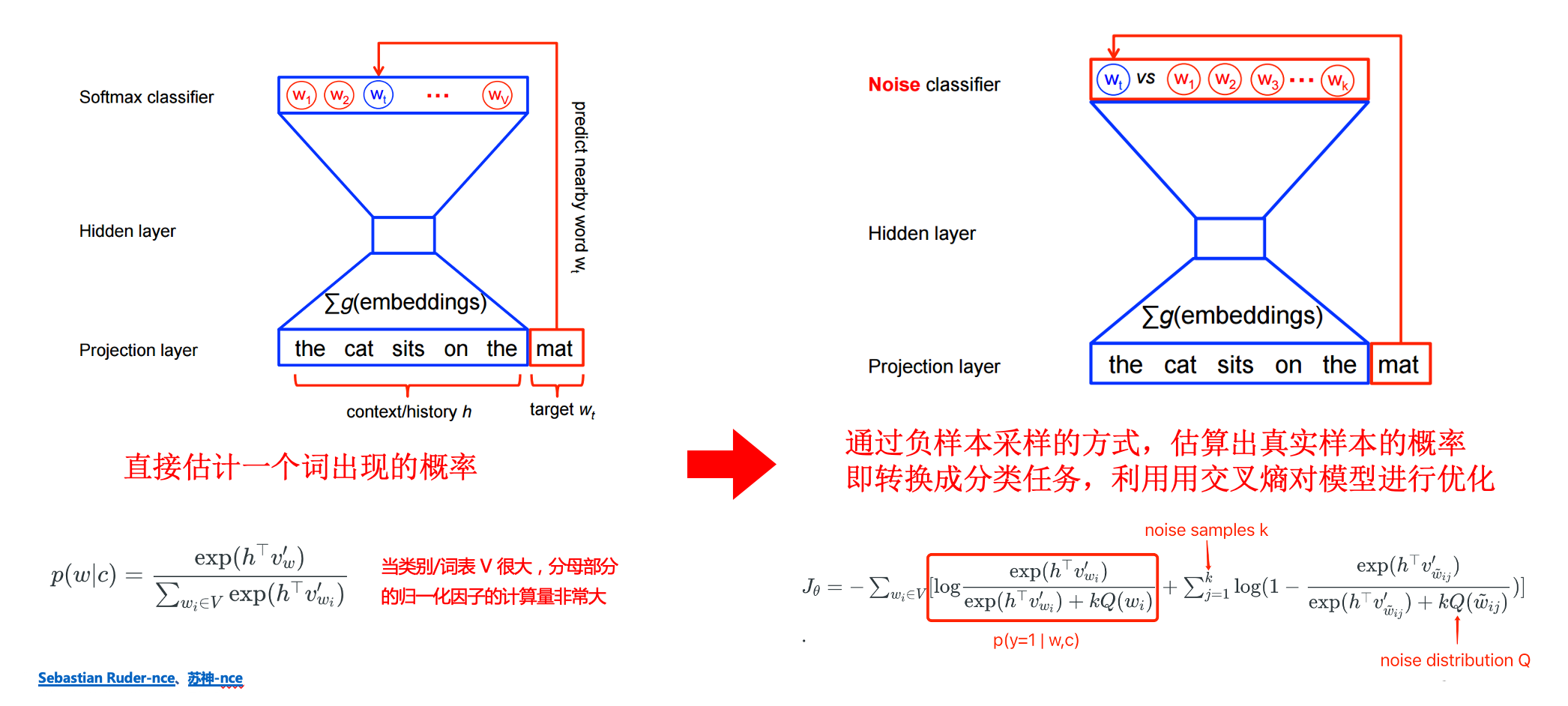
- InfoNCE损失
InfoNCE继承了NCE的基本思想,从一个新的分布引入负样例,构造了一个新的多元分类问题,并且证明了减小这个损失函数相当于增大互信息 (mutual information) 的下界,这也是名字infoNCE的由来。具体细节这里不再赘述,感兴趣的读者可以参考「这篇文章」,里面有比较清晰的介绍与推导。
我们直接看一下目前对比学习中常见的infoNCE loss形式:
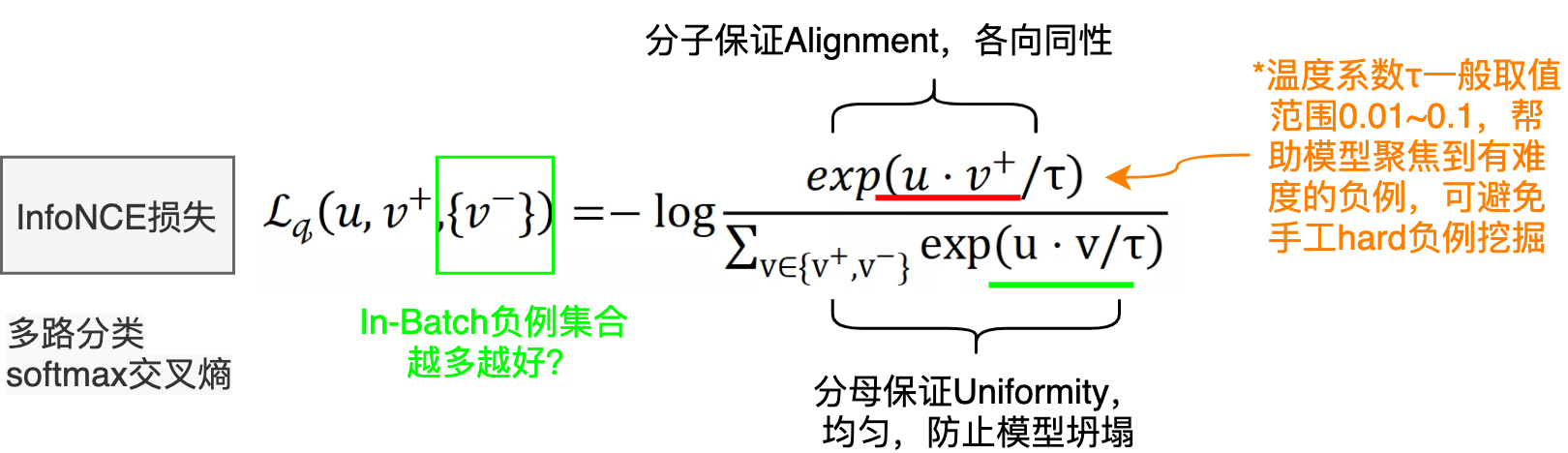
其中 、
、
分别为原样例、正样例、负样例归一化后的表示,
为温度超参。显而易见,infoNCE最后的形式就是多元分类任务常见的交叉熵损失(Cross Entropy Loss for N-way softmax classifier),使用分类交叉熵损失在一组负样本中识别正样本。因为表示已经归一化,据前所述,向量内积等价于向量间的距离度量。故由softmax的性质,上述损失就可以理解为,我们希望在拉近原样例与正样例距离的同时,拉远其与负样例间的距离,这正是对比学习的思想。
τ为softmax的温度超参,并不是原始InfoNCE损失的组成部分,它被引入的一个重要前提假设就是“不完全信任用户的点击标签”,意在控制模型对标签的信任程度,越小(趋向于0),则越信任,反之则越不信任。τ越小,softmax越接近真实的max函数,越大越接近一个均匀分布。因此,当很小时,只有难区分的负样例才会对损失函数产生影响,同时,对错分的样例(即与原样例距离比正样例与原样例距离近)有更大的惩罚。实验结果表明,对比学习对 很敏感。下文对比损失若不特意提及,则默认为infoNCE loss。
2.6 衡量标准
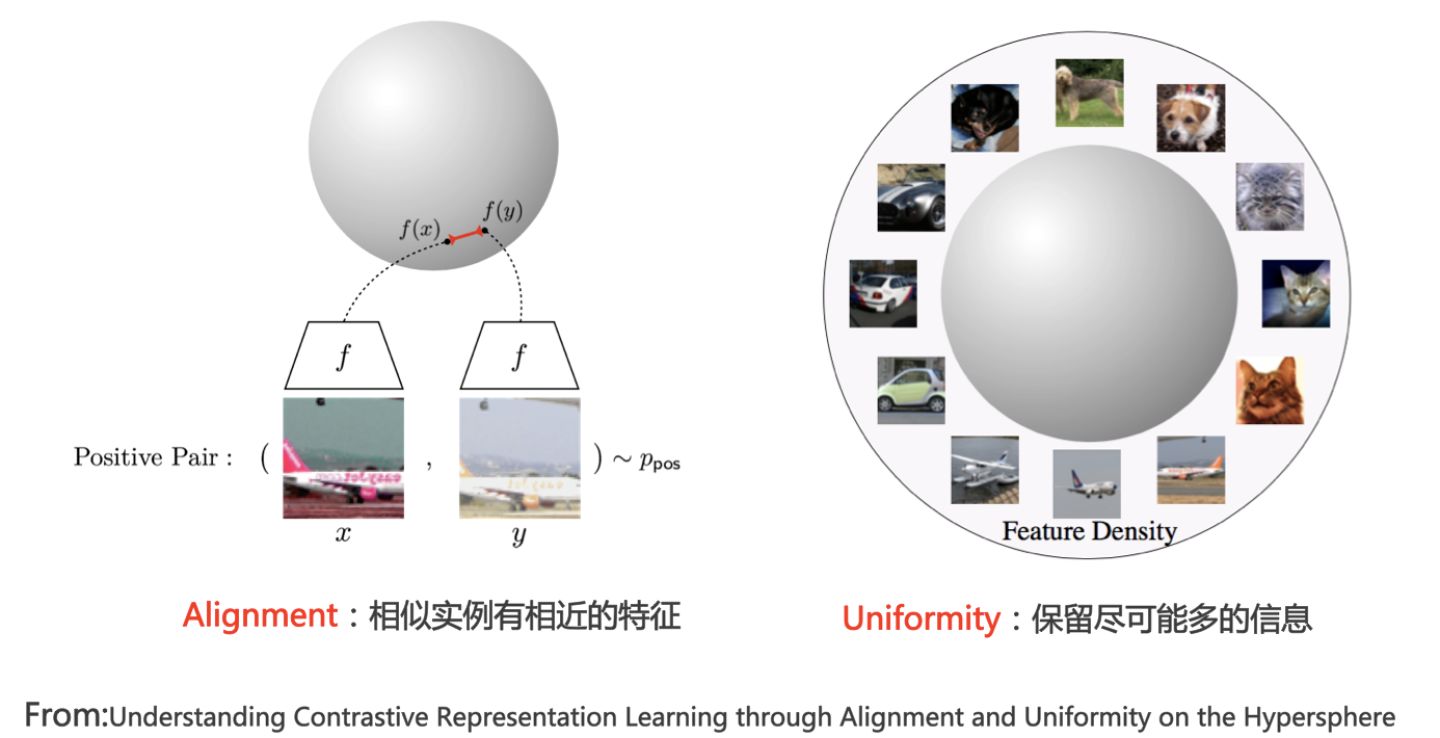
好的对比学习系统应该满足什么条件呢?或者说好的对比学习的效果如何?(可以参考上图所示论文)它应兼顾两个要素:Alignment和Uniformity。
Alignment代表我们希望对比学习把相似的正例在投影空间里面有相近的编码,一般来说,对比学习获得的表示向量会被投影到单位超球面上进行相互比较。如果模型的表示能力足够好,能够把相似的例子(比如带有相同类标号的数据)在超球面上聚集到较近区域,那么很容易使用线性分类器把某类和其它类区分开。
关键的是第二点,就是这个uniformity。Uniformity代表什么含义呢? Uniformity直观上来说就是:当所有实例映射到投影空间之后,我们希望它在投影空间内的分布是尽可能均匀的。这里有个点不好理解:为什么我们希望分布是均匀的呢?其实,追求分布均匀性不是Uniformity的目的,而是手段。追求分布的Uniformity实际想达成的是什么目标呢?它实际想达成的是:我们希望实例映射到投影空间后,在对应的Embedding包含的信息里,可以更多保留自己个性化的与众不同的信息。
那么,Embedding里能够保留更多个性化的信息,这又代表什么呢?举个例子,比如有两张图片,都是关于狗的,但是一张是在草地上跑的黑狗,一张是在水里游泳的白狗。如果在投影成Embedding后,模型能各自保留各自的个性化信息,那么两张图片在投影空间里面是有一定距离的,以此表征两者的不同。而这就代表了分布的均匀性,指的是在投影球面上比较均匀,而不会说因为都是关于狗的图片,而聚到球面的同一个点中去,那就会忽略掉很多个性化的信息。这就是说为什么Uniformity分布均匀代表了编码和投影函数f保留了更多的个性化信息。
Uniformity特性的极端反例,是所有数据映射到单位超球面同一个点上,这极度违背了Uniformity原则,因为这代表所有数据的信息都被丢掉了,体现为数据极度不均匀得分布到了超球面同一个点上。也就是说,所有数据经过特征表示映射过程  后,都收敛到了同一个常数解,一般将这种异常情况称为模型坍塌(Collapse)。
后,都收敛到了同一个常数解,一般将这种异常情况称为模型坍塌(Collapse)。
一个好的对比学习系统,要兼顾这两者。既要考虑Alignment,相似实例在投影空间里距离越近越好。也要考虑Uniformity,也就是不同实例在投影空间里面分布要均匀一些,让实例映射成embedding之后尽可能多的保留自己的个性化信息。
3.对比学习在CV领域的应用
这一章将介绍近几年图像领域对比学习有代表性的几篇工作。
3.1 SimCLR (2020 Feb)-Batch内负例
基于In-Batch负例的对比学习-SimCLR An incomplete and slightly outdated literature review on augmentation based self-supervise learning
作为Google的大作,SimCLR提出了一种简单的对比学习框架,通过对同一个图像进行增强,得到两个不同版本,随后通过编码器 对图像编码,再使用一个映射层
对图像编码,再使用一个映射层将其映射到特征空间,使用 infoNCE 损失进行训练
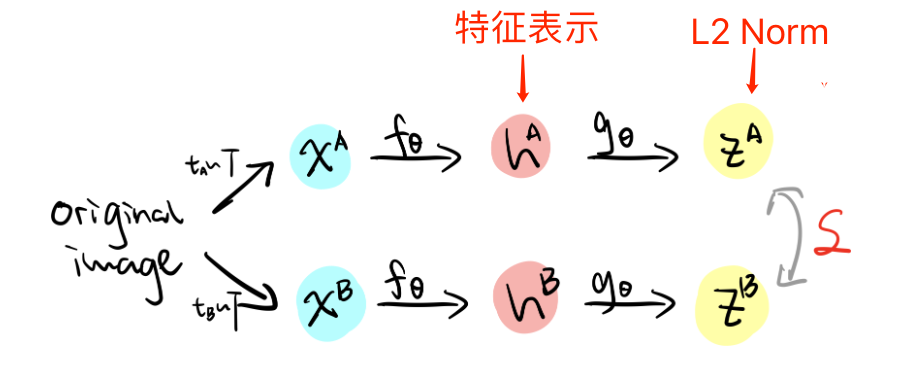
- 随机数据增强模块
本文使用了三种方法进行数据增强:随机裁剪和调整(裁剪后调整图像尺寸为原图大小)、随机色彩失真和随机高斯模糊。对于某张图片,我们从可能的增强操作集合 T 中,随机抽取两种分别作用在原始图像上,形成两张经过增强的新图像 ,两者互为正例;而负例使用 In-Batch Negatives
,两者互为正例;而负例使用 In-Batch Negatives
- 基编码器(base encoder)
SimCLR采用的是典型的双塔结构,其中基编码器定义为 ,其作用在于从增强后的数据集中提取表征向量
,其作用在于从增强后的数据集中提取表征向量  :
:

- 小型神经网络投影头(projection head)
非线性变换结构 Projector,这里以函数 代表,它的作用是将编码后的表征
代表,它的作用是将编码后的表征  映射到潜在特征空间中,本文使用的是一个两层 MLP [FC->BN->ReLU->FC],具体计算方法如下:
映射到潜在特征空间中,本文使用的是一个两层 MLP [FC->BN->ReLU->FC],具体计算方法如下:

- 对比损失
The model θ is learned through minimising the following infoNCE objective:
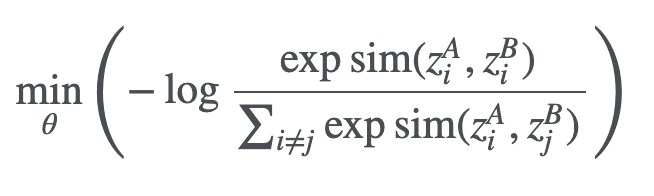
其中sim表示两个向量之间的余弦相似度,即  .
.
通过最小化上述 objective,我们最大化同一图像的两个视图view的表示之间的相似性,并最小化不同图像之间的相似性。
SimCLR 伪代码流程:

SimCLR怎么防止坍塌:
SimCLR本质上是通过引入负例来防止模型坍塌的
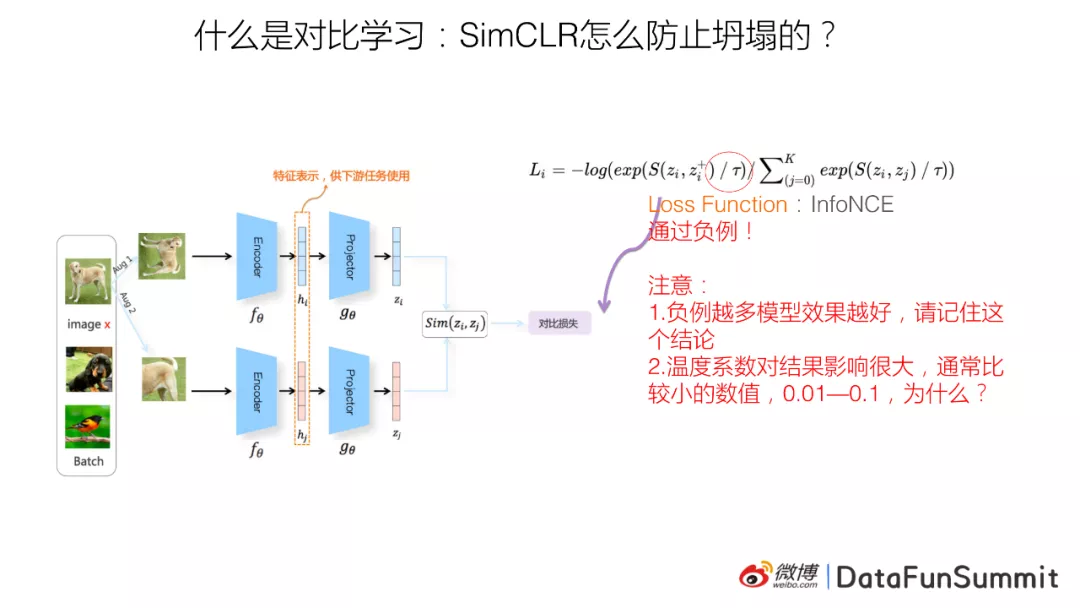
上图展示的InfoNCE损失函数。InfoNCE的分子  部分体现了Alignment这个要素,因为它期望正例在投影空间里面越近越好,也就是相似性越大越好。它防止坍塌是靠分母里的
部分体现了Alignment这个要素,因为它期望正例在投影空间里面越近越好,也就是相似性越大越好。它防止坍塌是靠分母里的  负例:也就是说,如果图片和负例越不相似,则相似性得分越低,代表投影空间里距离越远,则损失函数就越小。InfoNCE通过强迫图片和众多负例之间,在投影球面相互推开,以此实现分布的均匀性(防止模型坍塌),也就兼顾了Uniformity这一要素。所以你可以理解为SimCLR是通过随机负例来防止模型坍塌的。
负例:也就是说,如果图片和负例越不相似,则相似性得分越低,代表投影空间里距离越远,则损失函数就越小。InfoNCE通过强迫图片和众多负例之间,在投影球面相互推开,以此实现分布的均匀性(防止模型坍塌),也就兼顾了Uniformity这一要素。所以你可以理解为SimCLR是通过随机负例来防止模型坍塌的。
图像领域对比学习,目前有两个很明确的结论,是这样的:第一是:在Batch内随机选取负例,选取的负例数量越多,对比学习模型的效果越好;第二个是在InfoNCE的公式里有个τ,这个叫温度系数,温度系数对于对比学习模型效果的影响非常之大,你设置成不同的参数,可能效果会差百分之几十,一般来说,这个τ经验上应该取比较小的值,从0.01到0.1之间。问题是:将这个超参设大或设小,它是如何影响模型优化过程的呢?目前的研究结果表明,InfoNCE是个能够感知负例难度的损失函数,而之所以能做到这点,主要依赖超参。
什么是有难度的负例?什么是容易的负例呢?我们知道,对比学习里,对于某个数据  ,除了它的唯一的正例
,除了它的唯一的正例  外,所有其它数据都是负例。但是,这些负例,有些和
外,所有其它数据都是负例。但是,这些负例,有些和  比较像,有些则差异比较大,比如假设
比较像,有些则差异比较大,比如假设  是张关于狗的图片,那么另外一张狗的图片,或者一张狼的图片,就是有难度的负例,而如果是一张关于人的或者树的图片,则比较好和
是张关于狗的图片,那么另外一张狗的图片,或者一张狼的图片,就是有难度的负例,而如果是一张关于人的或者树的图片,则比较好和  区分开,是容易例子。如果经过
区分开,是容易例子。如果经过  将数据映射到单位超球面后,根据Alignment原则,一般来说,比较像的、有难度的负例在超球面上距离
将数据映射到单位超球面后,根据Alignment原则,一般来说,比较像的、有难度的负例在超球面上距离  比较近,而比较容易区分的负例,则在超球面上距离
比较近,而比较容易区分的负例,则在超球面上距离  比较远。所以说,对于例子
比较远。所以说,对于例子  来说,在超球面上距离
来说,在超球面上距离  越近,则这个负例越难和
越近,则这个负例越难和  区分,距离
区分,距离  越远,则这个负例越容易和
越远,则这个负例越容易和  区分。
区分。
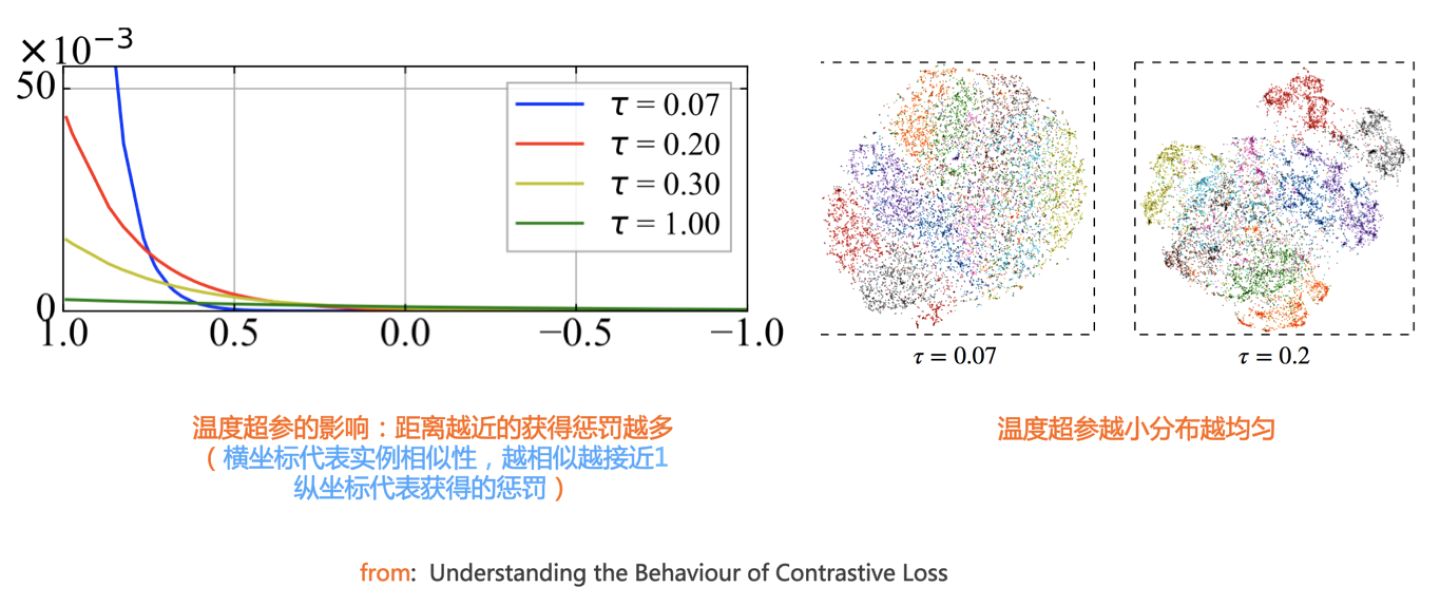
总体而言,温度参数  起到如下作用:温度参数会将模型更新的重点,聚焦到有难度的负例,并对它们做相应的惩罚,难度越大,也即是与
起到如下作用:温度参数会将模型更新的重点,聚焦到有难度的负例,并对它们做相应的惩罚,难度越大,也即是与  距离越近,则分配到的惩罚越多。所谓惩罚,就是在模型优化过程中,将这些负例从
距离越近,则分配到的惩罚越多。所谓惩罚,就是在模型优化过程中,将这些负例从  身边推开,是一种斥力。也就是说,距离
身边推开,是一种斥力。也就是说,距离  越近的负例,温度超参会赋予更多的排斥力,将它从
越近的负例,温度超参会赋予更多的排斥力,将它从  推远。而如果温度超参数
推远。而如果温度超参数  设置得越小,则InfoNCE分配惩罚项的范围越窄,更聚焦在距离
设置得越小,则InfoNCE分配惩罚项的范围越窄,更聚焦在距离  比较近的较小范围内的负例里。同时,这些被覆盖到的负例,因为数量减少了,所以,每个负例,会承担更大的斥力(参考上图左边子图)。极端情况下,假设温度系数趋近于0,那么InfoNCE基本退化为Triplet,也就是说,有效负例只会聚焦在距离
比较近的较小范围内的负例里。同时,这些被覆盖到的负例,因为数量减少了,所以,每个负例,会承担更大的斥力(参考上图左边子图)。极端情况下,假设温度系数趋近于0,那么InfoNCE基本退化为Triplet,也就是说,有效负例只会聚焦在距离  最近的一到两个最难的实例。从上述分析,可以看出:温度超参越小,则更倾向把超球面上的局部密集结构推开打散,使得超球面上的数据整体分布更均匀(参考上图右边子图)。
最近的一到两个最难的实例。从上述分析,可以看出:温度超参越小,则更倾向把超球面上的局部密集结构推开打散,使得超球面上的数据整体分布更均匀(参考上图右边子图)。
那么,是不是温度超参  设置的越小越好呢?因为这个数值越小,意味着超球面上的数据分布越均匀,越符合Uniformity原则。其实,并不是这样的。因为在对比学习这种场景下,对于某个数据
设置的越小越好呢?因为这个数值越小,意味着超球面上的数据分布越均匀,越符合Uniformity原则。其实,并不是这样的。因为在对比学习这种场景下,对于某个数据  ,只有一对正例
,只有一对正例  ,可能会发生如下的情形:距离
,可能会发生如下的情形:距离  比较近的所谓“负例”,其实本来应该是正例,比如
比较近的所谓“负例”,其实本来应该是正例,比如  是一张狗的照片,而
是一张狗的照片,而  其实也是一张狗的照片。只是因为对比学习是无监督的,我们没有先验知识知晓这一点,所以也会把这张狗的照片当作负例。而如果温度超参越小,则可能越会倾向把这些本来是潜在正例的数据在超球面上推远,而这并不是我们想要看到的。要想容忍这种误判,理论上应该把温度超参设置大一些。所以,温度超参需要在鼓励Uniformity和容忍这种误判之间找到一个平衡点,而调节这个参数大小,其实就是在寻找这两者的平衡点。
其实也是一张狗的照片。只是因为对比学习是无监督的,我们没有先验知识知晓这一点,所以也会把这张狗的照片当作负例。而如果温度超参越小,则可能越会倾向把这些本来是潜在正例的数据在超球面上推远,而这并不是我们想要看到的。要想容忍这种误判,理论上应该把温度超参设置大一些。所以,温度超参需要在鼓励Uniformity和容忍这种误判之间找到一个平衡点,而调节这个参数大小,其实就是在寻找这两者的平衡点。
3.2 Moco-Batch外负例
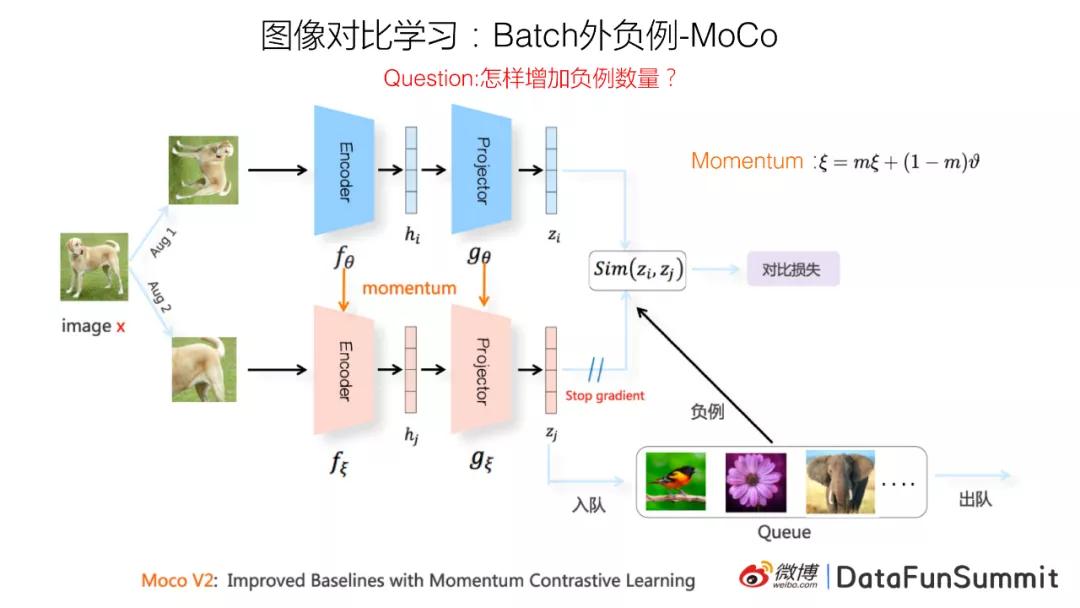
刚才讲的是SimCLR系统,现在介绍另外一个代表系统Moco(Facebook提出)。前面说过一个已有结论:负例用的越多,模型效果越好。我们知道SimCLR是在Batch里面随机选的负例。但是在Batch里采负例有现实问题:Batch size不能无限放大,因为batch size增大对计算资源要求比较高,所以总有个限度。现有结论是负例越多越好,但是batch size制约了负例的采样个数,我们希望能采取一些技术手段,能采样大量的负例,但是又不受Batch size大小限制的约束。MocoV2是典型的解决这种矛盾的例子,也就是说,我们如何能够解除batch size的约束,来大幅增加负例的数量。
上图是Moco V2的模型结构图。其实它和SimCLR的结构基本是类似的,只有一点小差异。它也是上下两个双塔结构,网络结构也由两个映射子结构组成,和SimCLR完全一样。下面这个分支结构本身是和上分支的网络结构是完全一样的。
上下两个分支的区别有两点:第一点是下分支的网络参数更新机制和上分支的更新机制不一样,采用动量更新机制;第二点是说Moco维护了一个负例队列。细节在这里不展开说了。它实际是想解决一个问题,就是负例受batch size大小制约的影响,怎么解决的呢?通过维护的负例队列来解决。也就是说下分支的正例通过下分支打成embedding,然后会把它放入队列里面(入队),在队列待了太久的会让它出队。Moco的负例采集方法和SimCLR一样,是随机抽取负例。但它不是在batch里面取,而是从负例队列里取。你可以在负例队列里面取任意大小的负例数量来作为模型的负例,这样就避免了负例大小受batch size的影响。这就是典型的Moco做对比学习的思路。Moco主要是两点:一个是下分支的动量更新,一个就是负例队列。这两点是比较新的。
- 代码流程

如果归纳一下,现在采用负例的方法主要有三个共识:第一,网络结构现在大家基本用的都是双塔结构。第二,映射函数一般由两部分组成,首先是Resnet,用来对图像编码,还有一个是projector。第三,在Moco v3和SimCLRv2 版本升级时都有体现,就是encoder越来越复杂。如果用Resnet它会越来越宽,越来越深,也可以用更复杂的transformer来做这件事。这三点应该说是目前用负例作对比学习的三个比较典型的特点。
3.3 SwAV-对比聚类
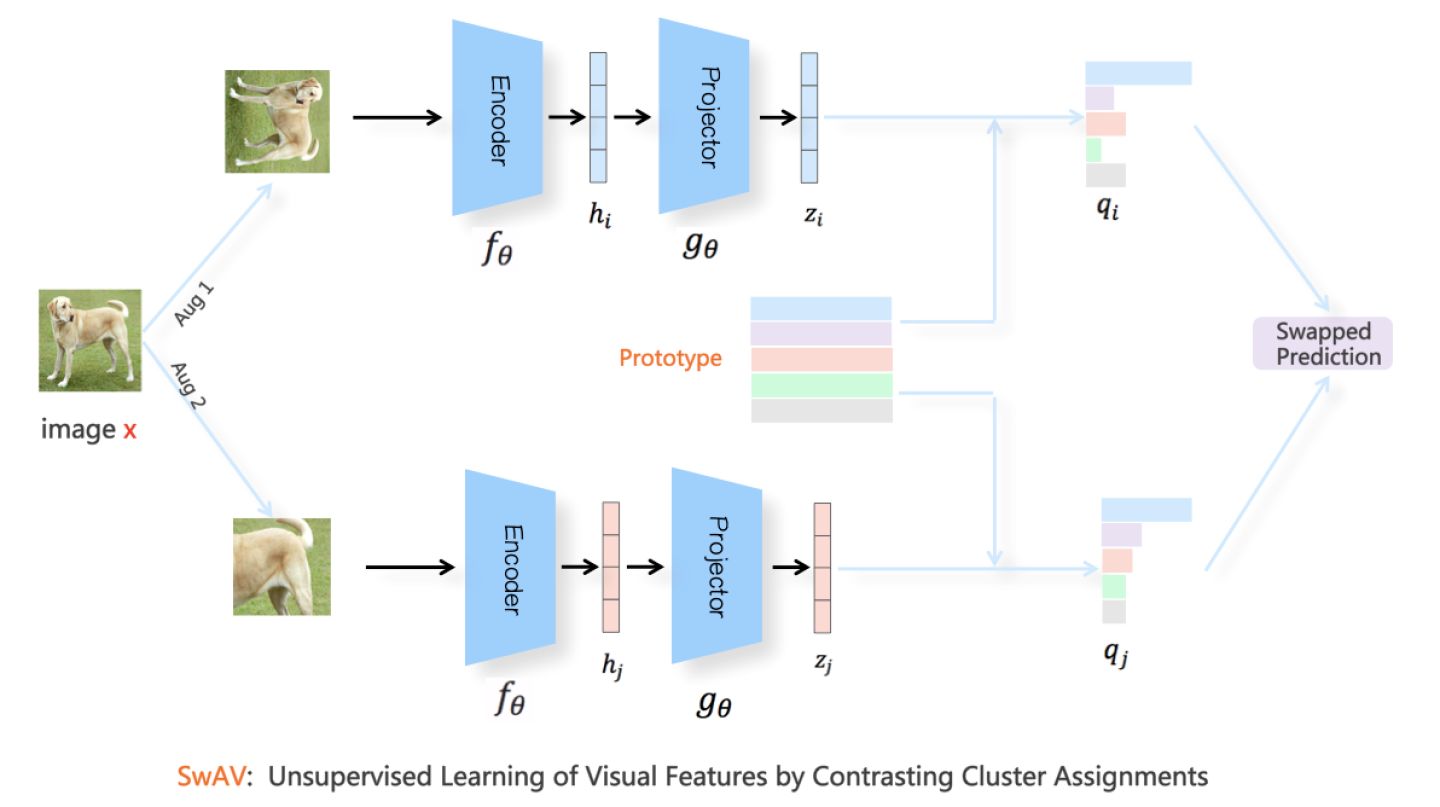
最后再介绍下SwAV,它是个典型的对比聚类的方法,SwAV是图像对比学习众多模型中效果最好的方法之一。关于正负例构造方法,SwAV和刚才提到的方法一样,这里不再多提。关于模型结构,SwAV的双塔结构和两个映射函数,和SimCLR等模型一样,是上下对称的。
SwAV的主要特点在这里:在模型训练过程中引入了聚类。我们以一个例子阐述其工作流程。对于Batch内某张图像  来说,假设其经过图像增强后,在Aug1和Aug2里的对应的增强后图像分别是
来说,假设其经过图像增强后,在Aug1和Aug2里的对应的增强后图像分别是  和
和  ,数据对
,数据对  互为正例。增强视图
互为正例。增强视图  走上分枝,经过
走上分枝,经过  投影到单位超球面中某点
投影到单位超球面中某点  ,增强视图
,增强视图  走下分枝,经过
走下分枝,经过  投影到单位超球面中某点
投影到单位超球面中某点  。之后,SwAV对Aug1和Aug2中的表示向量,根据Sinkhorn-Knopp算法,在线对Batch内数据进行聚类。假设走下分枝的
。之后,SwAV对Aug1和Aug2中的表示向量,根据Sinkhorn-Knopp算法,在线对Batch内数据进行聚类。假设走下分枝的  聚类到了
聚类到了  类,则SwAV要求表示学习模型根据
类,则SwAV要求表示学习模型根据  预测
预测  所在的类,也就是说,要将
所在的类,也就是说,要将  分到第
分到第  类,具体损失函数采用
类,具体损失函数采用  和Prototype中每个类中心向量的交叉熵:
和Prototype中每个类中心向量的交叉熵:

其中, ,
,  为第k个聚类的类中心向量,
为第k个聚类的类中心向量,  为温度超参数。
为温度超参数。
因为是对称结构,同样的,SwAV要求模型根据  预测
预测  所在的类,也就是说,要将
所在的类,也就是说,要将  分到第
分到第  类。所以,SwAV的总体损失函数是两个分枝损失之和:
类。所以,SwAV的总体损失函数是两个分枝损失之和:

这被称为Swapped Prediction。
SwAV也会面临模型坍塌的问题,具体表现形式为:Batch内所有实例都聚类到同一个类里。所以为了防止模型坍塌,SwAV对聚类增加了约束条件,要求Batch内实例比较均匀地聚类到不同的类别中。
这种对比聚类方法,看上去貌似只用了正例,未使用负例。但本质上,它与直接采用负例的对比学习模型,在防止模型坍塌方面作用机制是类似的,是一种隐形的负例。我们可以再仔细观察下它的损失函数,从中不难看出,在单位球面中,它要求某个投影点  向另外一个投影点
向另外一个投影点  所属的聚类中心靠近,这体现了Alignment原则;而分母中的投影点
所属的聚类中心靠近,这体现了Alignment原则;而分母中的投影点  所不属于的那些类中心,则充当了负例,它要求投影点
所不属于的那些类中心,则充当了负例,它要求投影点  在超球面上,和其它聚类中心越远越好,这体现了Uniformity属性,也是防止模型坍塌的关键。我们也可以换个角度,从聚类的角度来看SimCLR中的正例和负例,我们可以把SimCLR看成是:每两个正例组成了一个聚类中心。如果从这个角度看,其实SimCLR这种正负例方法,是种极端情况下的聚类模型。我们在上文说过,SimCLR这种模式,当温度超参设的比较小的时候,容易出现误判的负例,而聚类模型无疑在容忍负例误判方面,天然有很好的包容力,这也许是聚类方法效果好的原因之一。
在超球面上,和其它聚类中心越远越好,这体现了Uniformity属性,也是防止模型坍塌的关键。我们也可以换个角度,从聚类的角度来看SimCLR中的正例和负例,我们可以把SimCLR看成是:每两个正例组成了一个聚类中心。如果从这个角度看,其实SimCLR这种正负例方法,是种极端情况下的聚类模型。我们在上文说过,SimCLR这种模式,当温度超参设的比较小的时候,容易出现误判的负例,而聚类模型无疑在容忍负例误判方面,天然有很好的包容力,这也许是聚类方法效果好的原因之一。
3.4 非对称结构:模型不坍塌之谜
上文有述,在常见的基于负例的对比学习方法中,负例有着举足轻重的作用,它起到了将投影到超球体平面的各个实例对应的表示向量相互推开,使得图像对应的表示向量在超球体表面分布均匀的作用,以此来避免表示学习方法模型坍塌问题。尽管对比聚类方法看似没有明确使用负例,但如果深究,会发现仍然是负例在避免模型坍塌方面起作用。
那么,问题来了:并不是所有机构都有像谷歌一样的算力能够让batch-size=8192,用128核的TPU进行运算,同时越大的batch size,就有越大的可能包含错误负例(False Negative)…如果我们只使用正例,不使用负例来训练对比学习模型,这种思路是可行的吗?乍一看,这几乎是不可能的:假设只有正例,模型推动正例在表示空间内相互靠近。如果只有这一优化目标,很明显,理论上,模型会很快收敛到常数解,也就是所有数据会被映射到表示空间里同一个点上。就是说,很容易出现模型坍塌的结局。
但是,BYOL模型就是这么做的,关键是,它还做成功了,更关键的是,不仅做成功了,它还是目前效果最好的对比学习模型之一。那么,BYOL是怎么做到的呢?为什么它能够只用正例来训练对比学习模型,而不会出现模型崩塌的结局呢?
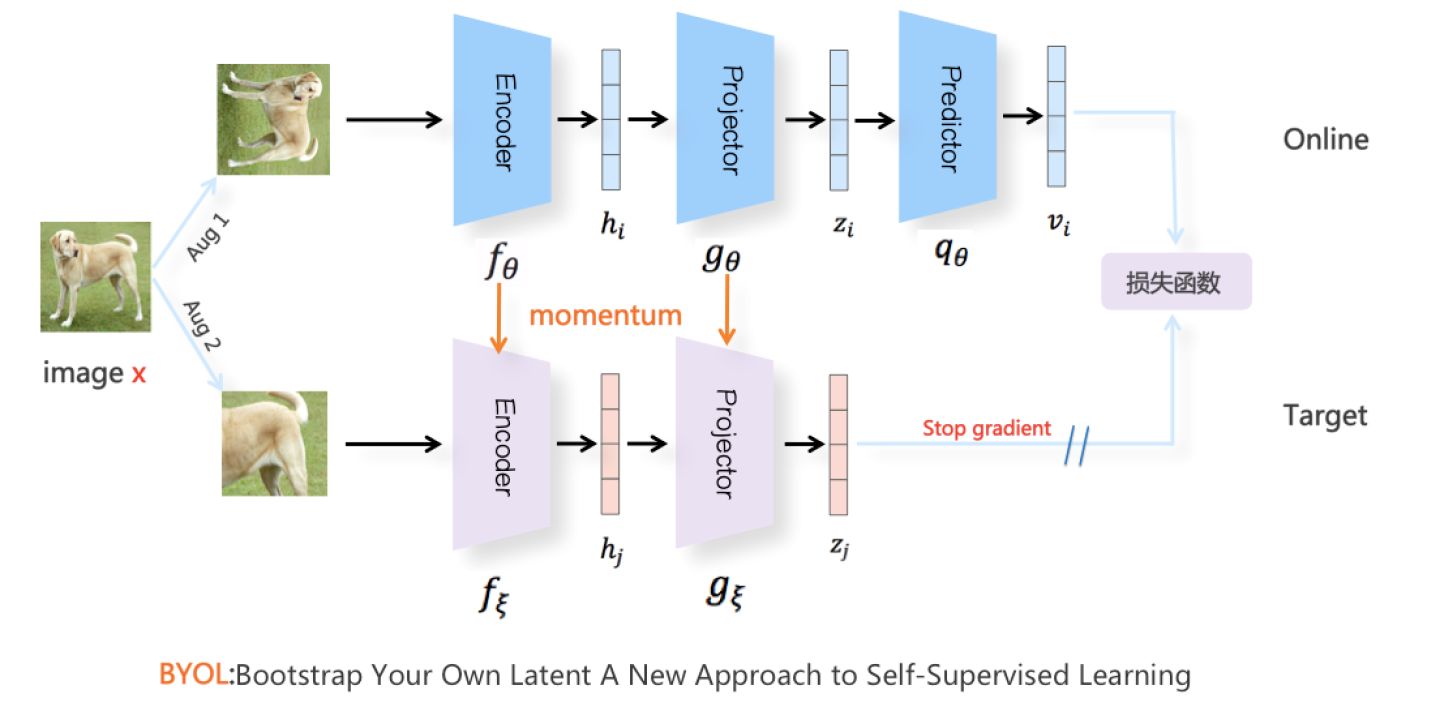
BYOL的模型结构如上图所示。对于Batch内任意图像,类似SimCRL采取随机图像增强,产生两组增强图像视图Aug1和Aug2,彼此互为正例,分别走上下两个模型分枝,上分枝被称为Online,下分枝被称为Target。Online分枝的Encoder和Projector和其它对比学习模型是一样的,但是,在Projector之后,新增了一个非线性变换模块Predictor,Predictor的结构和Projector类似([FC->BN->ReLU->FC]构成的MLP映射网络),产生表示向量  并对
并对  做L2正则化,将向量映射到单位超球面上。Target分枝结构类似Moco V2对应下分枝的动量更新结构,即由自有参数的Encoder和Projector构成,且模型参数不参与梯度更新,采用Online分枝对应结构参数的Moving Average动量更新方式。以此方式,产生增强图像Aug2的向量
做L2正则化,将向量映射到单位超球面上。Target分枝结构类似Moco V2对应下分枝的动量更新结构,即由自有参数的Encoder和Projector构成,且模型参数不参与梯度更新,采用Online分枝对应结构参数的Moving Average动量更新方式。以此方式,产生增强图像Aug2的向量  ,同样地,会对
,同样地,会对  做L2正则化操作,将表示向量映射到单位超球面上。但是,因为BYOL不用负例,所以并不需要维护Moco V2中的负例队列,下分枝只是对Aug2中的正例进行投影。
做L2正则化操作,将表示向量映射到单位超球面上。但是,因为BYOL不用负例,所以并不需要维护Moco V2中的负例队列,下分枝只是对Aug2中的正例进行投影。
对于BYOL来说,它的优化目标要求Online部分的正例,在表示空间中向Target侧对应的正例靠近,也即拉近两组图像增强正例之间的距离,对应Loss 函数为:

可见,经过改写,  也是Cosine相似性的一个变体,它的最小值对应两个表示向量的Cosine最大值,也即优化目标是在单位超球面上,正例之间的距离越近越好。由于online和Target分枝是不对称的,所以BYOL会交换两批增强图像,要求Aug2的图像也走一遍Online网络,并向Aug1图像对应的Target分枝表示向量靠近。也就是说,BYOL的损失函数为:
也是Cosine相似性的一个变体,它的最小值对应两个表示向量的Cosine最大值,也即优化目标是在单位超球面上,正例之间的距离越近越好。由于online和Target分枝是不对称的,所以BYOL会交换两批增强图像,要求Aug2的图像也走一遍Online网络,并向Aug1图像对应的Target分枝表示向量靠近。也就是说,BYOL的损失函数为:

我们知道,Moco V2在下分枝也采用了动量更新结构,如果我们把Moco V2的负例队列抛掉,并在它的上分枝加入类似BYOL的Predictor模块,则BYOL和Moco V2在结构上就保持一致。如果这么改动,两者的差异主要体现在损失函数带来的优化目标不一样:两者都试图将正例在表示空间拉近,但是Moco V2会在InfoNCE损失函数里用负例来防止模型坍塌,而BYOL对应的损失函数里,则没有对应的负例子项。
问题是:既然BYOL只用正例,它是如何防止模型坍塌的呢?背后的原因,目前仍然是未解之谜,不过对此也有些研究进展。BYOL的论文里首先指明了:之所以它没有坍塌到常数解,是由于online和Target两者结构的不对称造成的。具体而言,是动量更新的target结构和Online中的Predictor共同协作发生作用的。如果拿掉Predictor,或者把Target结构中的模型参数改成近乎实时和Online对应结构保持一致(就是说,每个Batch反向传播后,将Online部分最新的参数完全赋予给Target对应结构参数。或者理解为,动量更新公式中权重m取值为0),无论是哪种情况,模型都会发生坍塌。BYOL在论文里进一步实验,表明了最关键的因素在于新加入的Predictor结构:即使Target结构参数和Online部分保持一致,只要把Predictor部分的学习率调大,那么BYOL同样也不会坍塌。这说明Predictor的存在,是BYOL模型不坍塌的最关键因素,但是要配置大的学习率。此外,有其它研究[参考:Understanding self-supervised and contrastive learning with bootstrap your own latent (BYOL).]指出,Predictor中的BN在其中起到了主要原因,因为BN中采用的Batch内统计量,起到了类似负例的作用。但是很快,BYOL的作者在另外一篇文章里[参考:BYOL works even without batch statistics]对此进行了反驳,把Predictor中的BN替换成Group Norm+Weight standard,这样使得Predictor看不到Batch内的信息,同样可以达到采用BN类似的效果,这说明并非BN在起作用。
所以说,为何BYOL这种只用正例的对比学习模型不会发生期望中的模型坍塌,目前还未有定论,但是我们可以定位到主要由于Predictor结构的存在造成的。当然,说是模型结构的不对称带来的效果,原则上是没有问题的,因为这是一种相对粗略的说法。
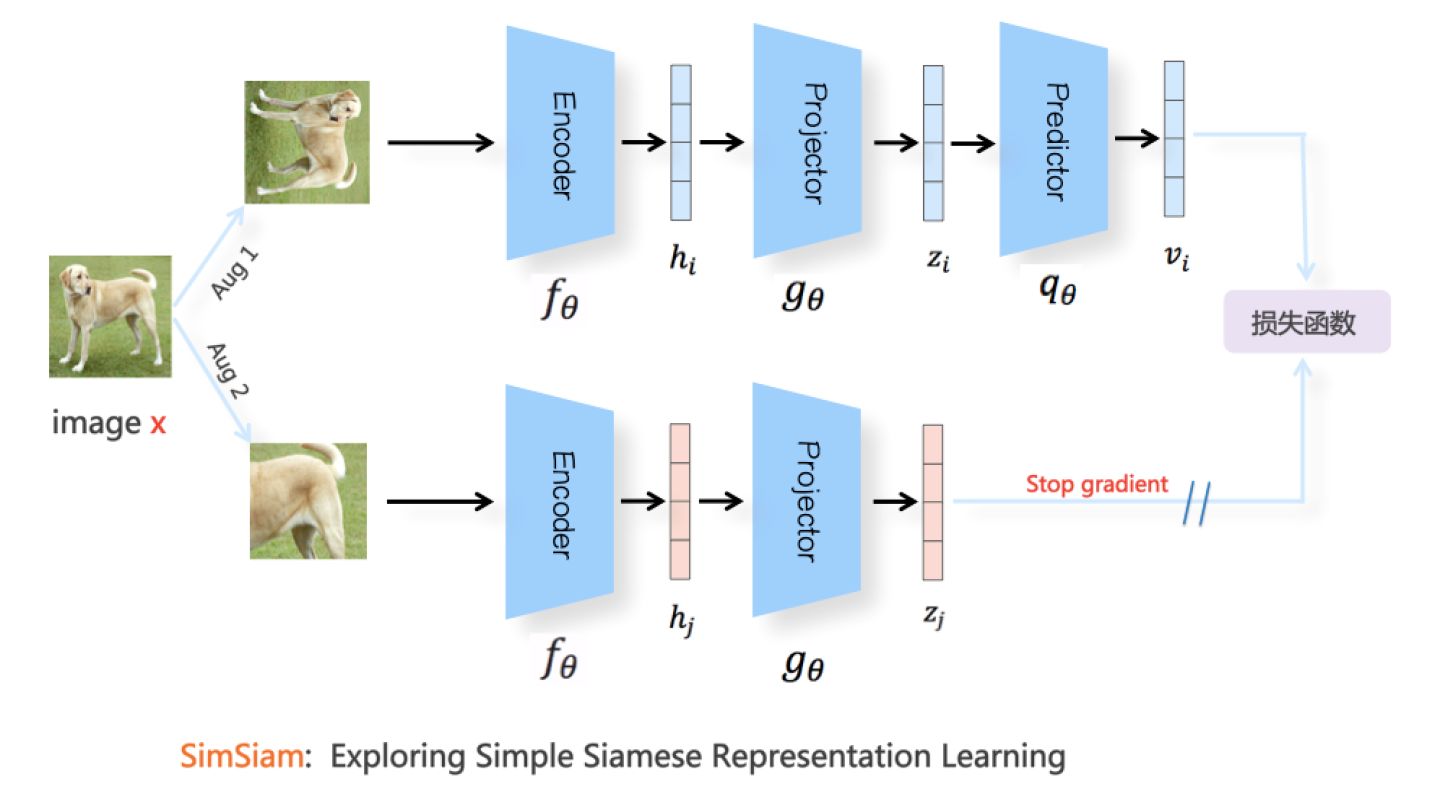
SimSiam进一步对BYOL进行了简化,我们可以大致将SimSiam看作是:把BYOL的动量更新机制移除,下分枝的Encoder及Projector和上分枝对应构件参数共享版本的BYOL(参考上图),类似前面介绍BYOL里说的Predictor加大学习率的版本。但是,从后续文献的实验对比来看,SimSiam效果是不及BYOL的,这说明动量更新机制尽管可能不是防止模型坍塌的关键因素,但是对于提升对比学习模型效果是很重要的。
3.5 Decouple Contrastive Learning

SimCLR对于模型效果的提升必须基于大Batch Size才会有效果。
而在近期,由 Yann Lecun 等人发表了一篇题为《Decouple Contrastive Learning》的论文,其中仔细分析了SimCLR和其他自监督学习模型所使用的InfoNCE损失函数,仅仅对InfoNCE的表达式进行了一处修改,就大大缓解了InfoNCE对于大Batch Size的需求问题,并在不同规模的Vision Benchmarks上均取得优于SimCLR的结果。
具体来说,通过将导数中的NPC乘数移除,作者推导出了下面的损失函数。在这个损失函数中,正负样本的耦合带来的梯度放缩被消去,作者将该损失称为Decoupled Contrastive Learning (DCL) Loss,即解耦对比损失函数: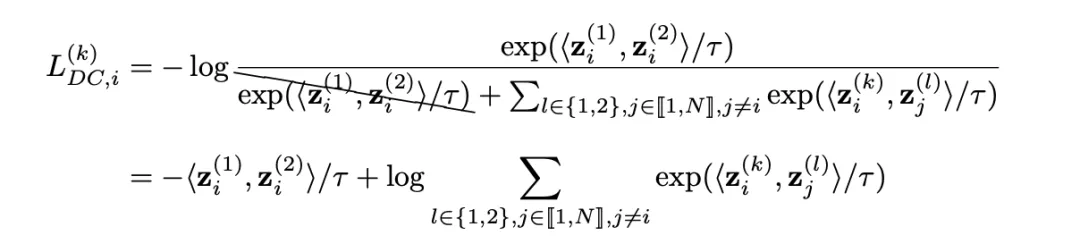
可见,Decoupled Constrive Learning中的损失直接去掉了SimCLR损失函数分母中两个正样本对之间的相似度,从而直接计算正样本对的相似度同所有负样本对相似度之和的比值。
总结来说,DCL损失仅在SimCLR所采用的损失函数基础上采取了一些小的改动,使得模型能够在训练过程中也不要求大Batch Size,同时对正负样本对进行解耦。在不同的Batch Size上,DCL损失的效果均优于SimCLR。同时,Batch Size越小,DCL损失提供的性能提升越大,这与先前的理论推导一致。
介绍了这么多对比学习在图像领域的工作,接下来我们一起看一下自然语言处理领域的对比学习工作,篇幅有限,这里主要介绍两篇对比学习做句子表示学习的文章。
4.对比学习在NLP领域的应用
4.0 Bert句向量不能直接用于相似度问题的分析
通常,我们使用Bert模型 [CLS] token的embedding向量或者最后几层的token embedding向量的平均来作为句子的sentence embedding。然而BERT的原生句子表示被证明是低质量的,甚至比不上Glove的结果。如下图所示,当应用BERT的句子表示到STS(semantic textual similarity)任务上时,几乎所有句子对都达到了0.6~1.0的相似度得分,这就是BERT的原生句子表示的坍塌问题(collapse issue),这意味着所有的句子都倾向于编码到一个较小的局部区域内,因此大多数的句子对都具有较高的相似度分数,即使是那些语义上完全无关的句子对。
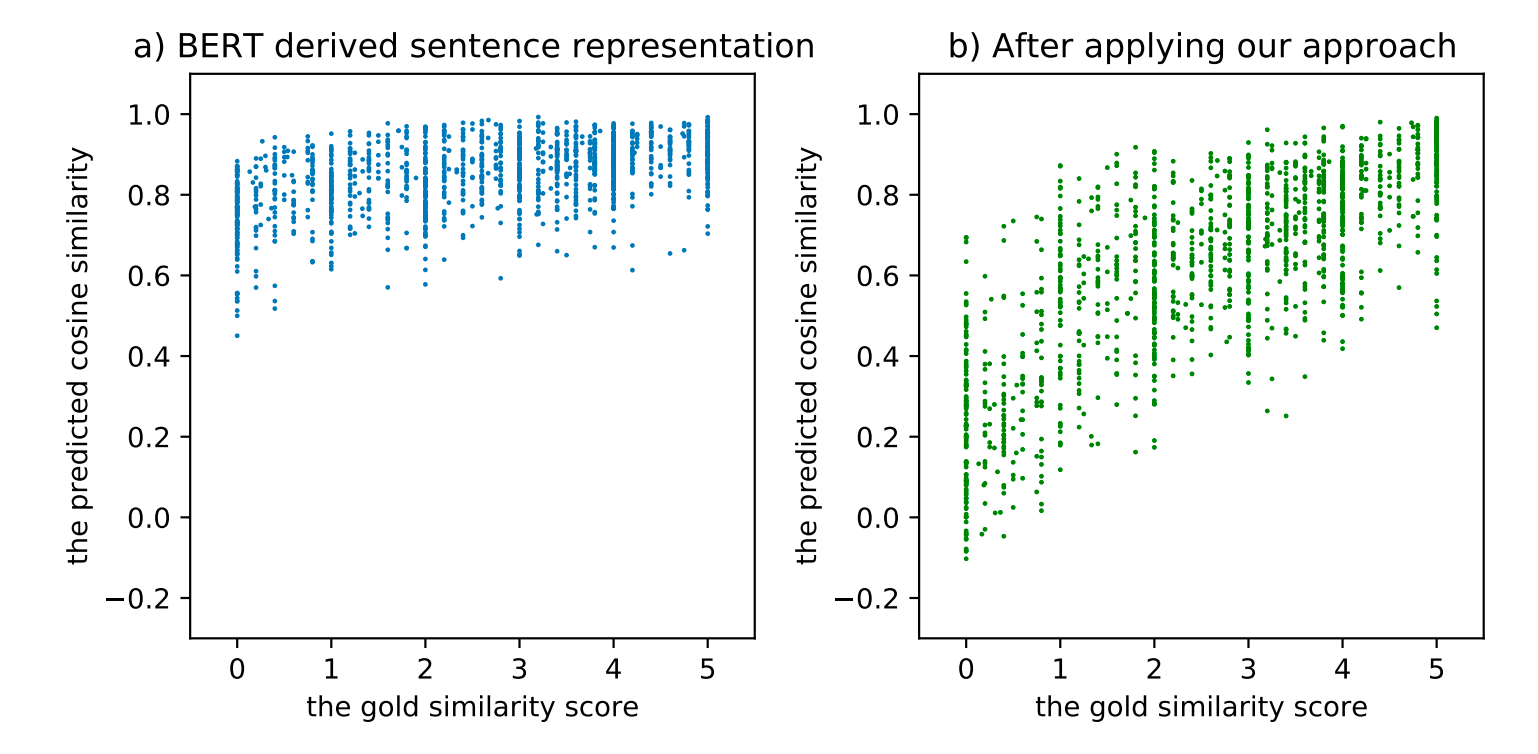
图1 左:BERT表示空间的坍缩问题(横坐标是人工标注的相似度分数,纵坐标是模型预测的余弦相似度);右:经过ConSERT方法Fine-tune之后
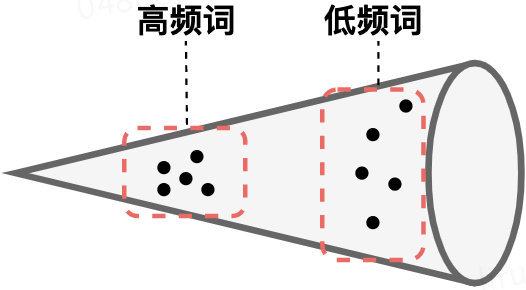
类似的现象在先前的研究中也有被观察到,研究人员发现BERT的词表示空间是「各向异性」的(即,用不同的方式去衡量它,他表现出不同的语义差别很大),高频词聚集到一起并且靠近坐标原点,而低频词则稀疏分散。当使用token embedding的平均作为句子表示时,高频词的就会起到主导地位,这就导致产生了对句子真实语义的偏置。也就是说,BERT句向量表示的坍缩和句子中的高频词有关。因此,在下游任务中直接应用BERT的原生句子表示是不合适的。
4.1 无监督句子表征学习
针对表示学习存在的各向异性/表示崩塌现象,对比学习并不是唯一解决该问题的研究方向,对BERT的后处理操作也是一种解决方法。
Bert-flow
BERT-flow 在文中详细总结并分析了以上两个问题之后,思想也比较直接,既然 BERT 出来的 embedding 向量存在各向异性,进而也产生了分布不均匀问题,那我就采用一个变换,将 BERT encode 的句子表达转换到一个各向同性且分布较均匀的空间。而标准的高斯分布刚好是一个各向同性的空间,且是一个凸函数,语义分布也更平滑均匀。
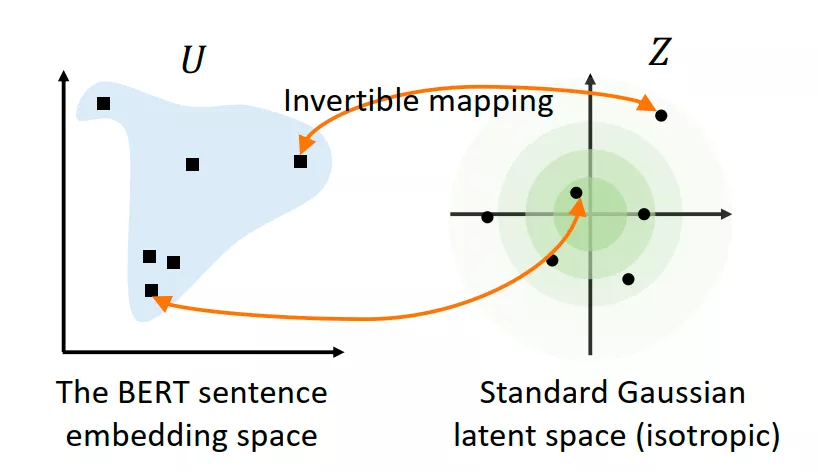
BERT-flow 采用一种流式可逆变换,记为: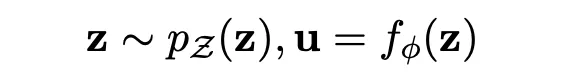
,其中 u 就是 BERT 空间向量(observe space),z 即是高斯空间向量(latent space), 则是一个可逆变换,这个变换也是模型需要学出来的。最后,通过无监督的方式 maximize 这个…优化目标,得到可逆的映射变换 f,这其实就是在 Bert pre-train model 后接了一个 flow 变换的模型,让其继续 pre-train,学出 flow 变换,从而完成向量空间的 transform。
小结:BERT-flow 完整分析了BERT 句子 embedding 里存在的向量各向异性及分布不均匀问题,并列出了完整的实验结果佐证了这一现象。同时提出了一种 flow 变换,将各向异性的 BERT 向量转换到一个标准的高斯分布空间,从而有效的提升了无监督领域的文本表达效果
Bert-Whitening
既然是要做一个向量的转换,那有没有简单一点的方法,直接校正句向量?BERT-whitening 提出通过一个白化的操作直接校正句向量的协方差矩阵,简单粗暴,也达到了与 BERT-flow 差不多的效果。此外,whitening技术还能够降低句子表征的维数,降低存储成本,加快模型检索速度。
方法很简单,思路也很直接,就是将现存的 BERT 向量空间分布记 #card=math&code=x_i-%28u%2C%5Csum%29&id=tBVKJ),其中均值为
,协方差
,进行白化操作,转换成
为单位阵的分布,也就是进行如下表达转换:
W#card=math&code=x_i%5E%60%3D%28x_i-u%29W&id=mw0jU)。所以问题就变成计算 BERT 向量分布的均值
,协方差
。

上图为步骤,把当前任务的语料,分别一句句地输入到预训练模型中得到各自的embedding,然后对embeddings做特征值分解,得到变换矩阵,然后存起来。应用时,输入新的句子,把它们输入预训练模型,得到句子embedding,再用存起来的变换矩阵u和W做变换,这时候得到的embedding就是标准正交基表示的embedding。
怎么求解均值
和协方差
,可以参考博客看完整推导:

小结:BERT-whitening 确实在 BERT-flow的基础上,更简单更直接的对原 BERT 向量进行空间分布转换,也达到 BERT-flow 差不多甚至更好的效果,加上作者的完整推导分享,思路也很清晰易懂,同时在 SVD 矩阵分解那一步,可以针对对角阵 Λ 进行一个降维操作,只保留特征值大的前 n 个维度,剔除冗余维度,这无疑在工程上应用节省了内存,也提升了性能。
上面说到,直接用BERT句向量做无监督语义相似度计算效果会很差,任意两个句子的BERT句向量的相似度都相当高,其中一个原因是向量分布的非线性和奇异性,BERT-flow通过normalizing flow将向量分布映射到规整的高斯分布上,更近一点的BERT-whitening对向量分布做了PCA降维消除冗余信息,但是标准化流的表达能力太差,而whitening操作又没法解决非线性的问题。因此研究转向了对比学习。基于对比学习(Contrastive Learning)的文本表示模型【为什么】能学到语义【相似】度?这篇文章说的挺好,梳理了对比学习应用于语义相似度任务的思路。
4.2 ConSERT
论文:《ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer》
下载链接:https://arxiv.org/abs/2105.11741
开源代码:https://github.com/yym6472/ConSERT
博客地址:ACL 2021|美团提出基于对比学习的文本表示模型,效果相比BERT-flow提升8%
为解决BERT原生句子表示的坍塌问题,美团NLP中心知识图谱团队提出了基于对比学习的句子表示迁移方法——ConSERT,模型结构非常简单,基本与SimCLR相同,只是把ResNet换成了Bert,并且去掉了映射头,见下图。

ConSERT主要包含三个部分:
- 一个数据增强模块(详见后文),作用于Embedding层,为同一个句子生成两个不同的增强版本(View)。
- 一个共享的BERT编码器,为输入的句子生成句向量。
- 一个对比损失层,用于在一个Batch的样本中计算对比损失,采用和SimCLR一致的NT-Xent损失对模型进行Fine-tune,实验中温度超参取0.1
训练时,先从数据集D中采样一个Batch的文本,设Batch size为N。通过数据增强模块,每一个样本都通过两种预设的数据增强方法生成两个版本,得到总共2N条样本。这2N条样本均会通过共享的BERT编码器进行编码,然后通过一个平均池化层,得到2N个句向量。我们采用和SimCLR一致的NT-Xent损失对模型进行Fine-tune: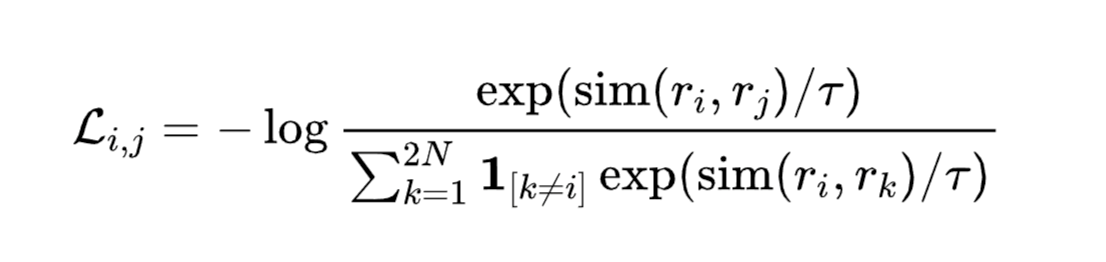
这里的sim()函数为余弦相似度函数;r表示对应的句向量;τ表示temperature,是一个超参数,实验中取0.1。该损失从直观上理解,是让Batch内的每个样本都找到其对应的另一个增强版本,而Batch内的其他2N−2个样本将充当负样本。优化的结果就是让同一个样本的两个增强版本在表示空间中具有尽可能大的一致性,同时和其他的Batch内负样本相距尽可能远。
数据增强方法
ConSERT考虑了在Embedding层隐式生成增强样本的方法,如上图所示:
- 对抗攻击(Adversarial Attack):这一方法通过梯度反传生成对抗扰动,将该扰动加到原本的Embedding矩阵上,就能得到增强后的样本。由于生成对抗扰动需要梯度反传,因此这一数据增强方法仅适用于有监督训练的场景。
- 打乱词序(Token Shuffling):这一方法扰乱输入样本的词序。由于Transformer结构没有“位置”的概念,模型对Token位置的感知全靠Embedding中的Position Ids得到。因此在实现上,我们只需要将Position Ids进行Shuffle即可。
- 裁剪(Cutoff):又可以进一步分为两种:
- Token Cutoff:随机选取Token,将对应Token的Embedding整行置为零。
- Feature Cutoff:随机选取Embedding的Feature,将选取的Feature维度整列置为零。
- Dropout:Embedding中的每一个元素都以一定概率置为零,与Cutoff不同的是,该方法并没有按行或者按列的约束。
除了无监督训练以外,作者还提出了几种进一步融合监督信号的策略:
- 联合训练(joint):在NLI数据集上,通过权重联合训练监督与无监督目标
- 先有监督再无监督(sup-unsup):先使用有监督损失训练模型,再使用无监督的方法进行表示迁移。
- 联合训练再无监督(joint-unsup):先使用联合损失训练模型,再使用无监督的方法进行表示迁移。
无监督实验结果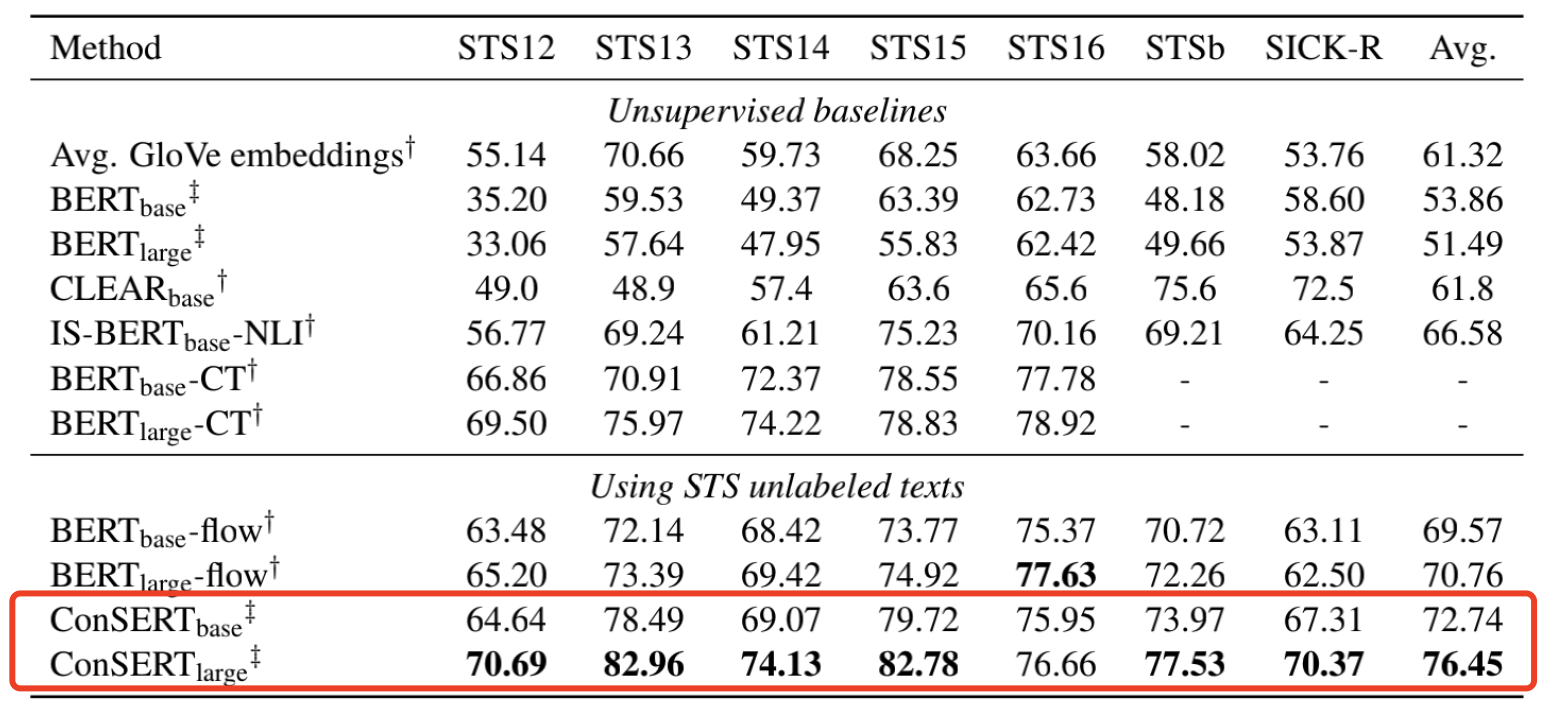
在无监督实验中,我们直接基于预训练的BERT在无标注的STS数据上进行Fine-tune。结果显示,我们的方法在完全一致的设置下大幅度超过之前的SOTA—BERT-flow,达到了8%的相对性能提升。
有监督实验结果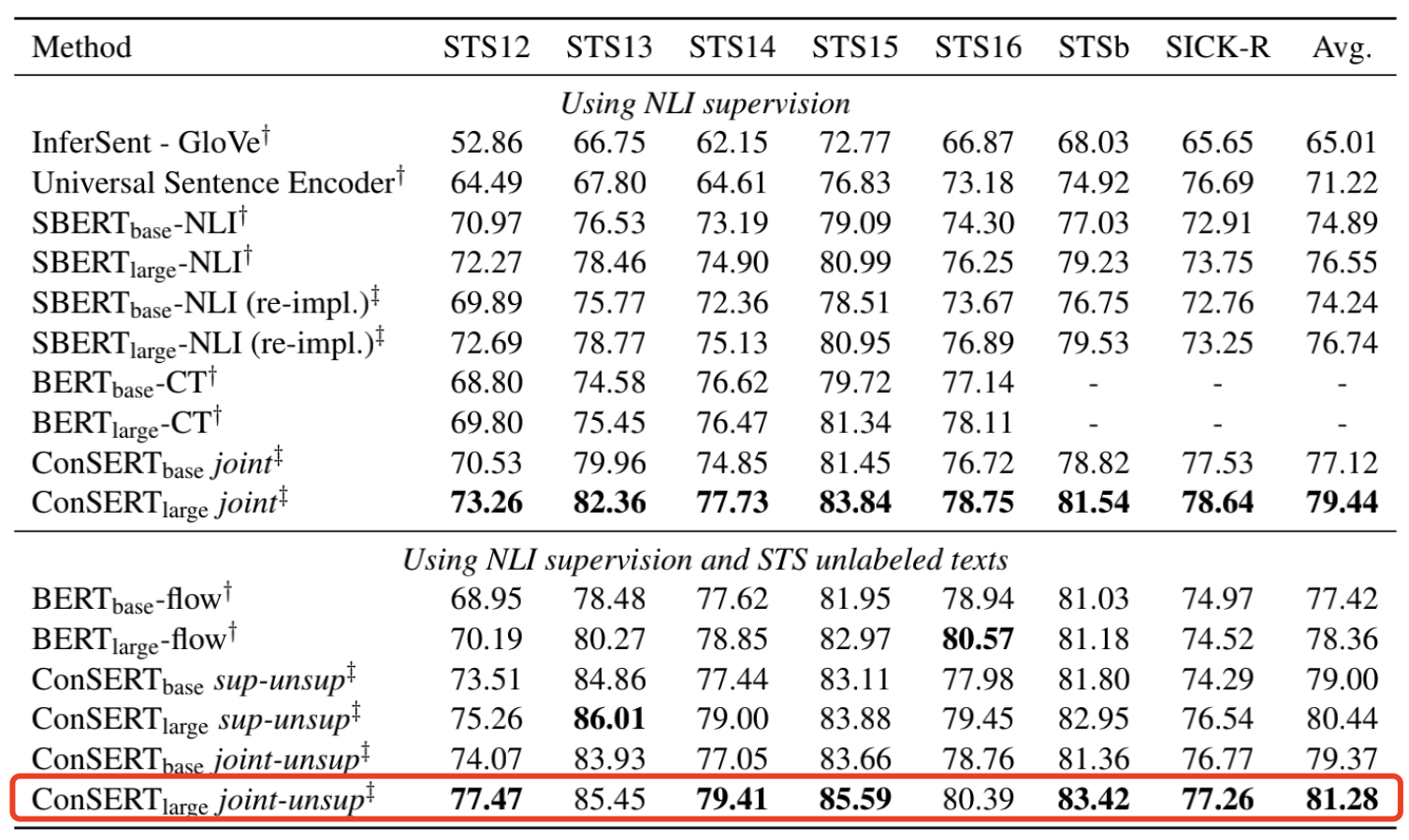
在有监督实验中,我们额外使用了来自SNLI和MNLI的训练数据,使用上面提到的融合额外监督信号的三种方法进行了实验。实验结果显示,我们的方法在“仅使用NLI有标注数据”和“使用NLI有标注数据 + STS无标注数据”的两种实验设置下均超过了基线。在三种融合监督信号的实验设置中,我们发现joint-unsup方法取得了最好的效果。
不同的数据增强方法分析
就单种数据增强方法而言,Token Shuffle > Token Cutoff >> Feature Cutoff ≈ Dropout >> None。温度超参τ值在0.08到0.12之间时会得到最优结果。不同Batch size下模型的表现相差不大。
4.3 SimCSE
论文:SimCSE: Simple Contrastive Learning of Sentence Embeddings
论文地址:https://arxiv.org/abs/2104.08821
论文代码:https://github.com/princeton-nlp/SimCSE
博客讲解:①中文任务还是SOTA吗?我们给SimCSE补充了一些实验、 ②SimCSE loss理解、③NLP与对比学习的巧妙融合,简单暴力效果显著!
SimCSE 是陈丹琦组的文章,有点重剑无锋,大巧不工的意思。SimCSE 在模型结构和对比损失上,与ConSERT基本相同,只是把映射头又加上了,最大创新点是采用简单的 dropout 正例构造方法+对比学习在STS任务就达到了SOTA!
SimCSE 分为无监督与有监督版本,但基本思想上没有什么区别,只是在正负样本数据构造上不同。
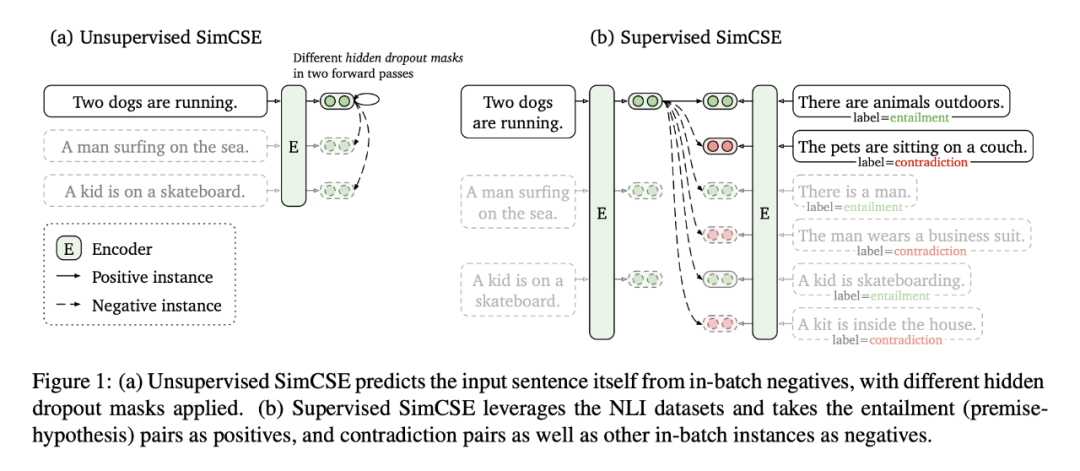
无监督版本上,就是将一个句子输入 encoder 两次,由于在标准的 Transformer 中,dropout mask是随机生成的,所以将同一个样本分两次输入到同一个编码器中,可以获得两次不同 dropout masks 下的句子向量  ,
, 表示一次随机的 dropout mask。给定一个包含 N 个句子的 batch 输入,对于句子 i,使用 BERT 预训练模型通过随机 dropout mask 编码两次得到的相似样本对作为正例 ,batch 内除句子 i 的其他样本 embedding 作为负例,训练的目标函数为:
表示一次随机的 dropout mask。给定一个包含 N 个句子的 batch 输入,对于句子 i,使用 BERT 预训练模型通过随机 dropout mask 编码两次得到的相似样本对作为正例 ,batch 内除句子 i 的其他样本 embedding 作为负例,训练的目标函数为:
其中 为温度超参,sim 表示余弦相似度:
 。在实际训练时,根据上面的对比学习目标函数,微调 BERT/RoBERTa 的模型参数。
。在实际训练时,根据上面的对比学习目标函数,微调 BERT/RoBERTa 的模型参数。

第一行是无监督的SimCSE,sample指的是对数据集采样训练,采样大小为134k,而full使用整个数据集作为训练集,图中的分数为斯皮尔曼相关系数 。而最后一栏中使用entailment作为正例,以contradiction作为hard neg,这也是有监督模型的最终模型。
有监督版本上,因为有监督数据了,就不是重复输入一个文本两次。选取文本蕴涵任务对应的数据集,有三个标签,entailment(蕴涵),neutral(中立),contradiction(相反),
有监督对比学习最终选择了利用文本蕴涵任务 NLI (SNLI+MNLI) 数据集,与无监督方法类似,将每一个premise和与其相对的entailment作为正样本对;负例包括两部分,第一部分是 batch 内其他样本作为负例,第二部分是 premise 对应的contradiction 作为 hard negatives。
loss 上与无监督是一致的,只是数据构造上的区别。训练目标函数为(infoNCE loss):

- 作者对比了在不同数据集上进行训练后在STS-B上的验证表现,并且实验结果表明引入hard neg能提高模型的效果, spearman 相关系数从84.9提升到了86.2。并且对于有多个contradiction的premise,作者只随机抽取了一个作为hard neg,使用多个hard neg对结果并没有提升。
实验结果:
下表展示了无监督 SimCSE 和 有监督 SimCSE 模型在多个英文 STS 数据集上的效果: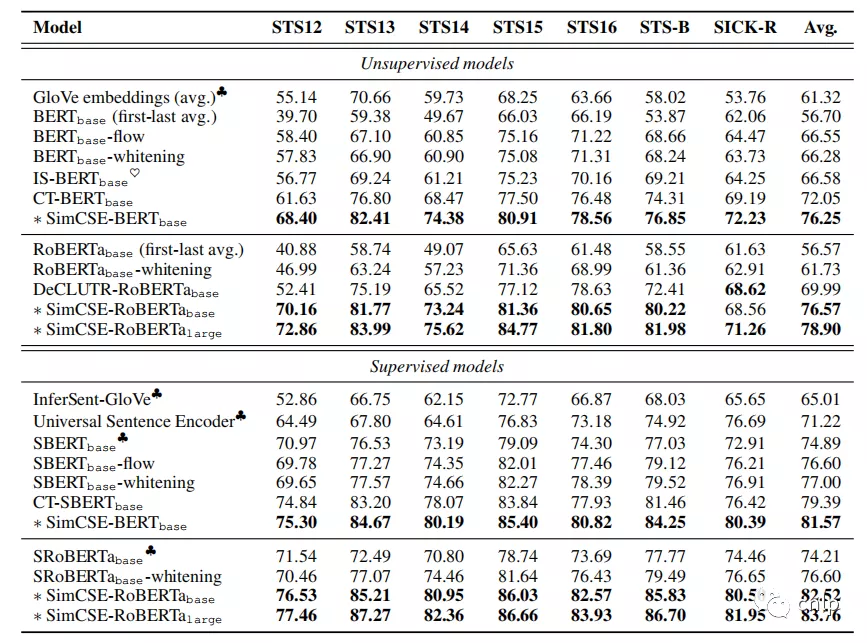 可以看出,在 7 个 STS 数据集上,无监督 SimCSE 比之前 state-of-the-art 的无监督方法效果提升显著。当加入 NLI 数据集进行监督训练时,SimCSE 模型的效果进一步得到提升,SimCSE-BERT-base 的平均 spearman 相关系数达到 0.8157,SimCSE-RoBERTa-large 的平均 spearman 相关系数达到 0.8376。
可以看出,在 7 个 STS 数据集上,无监督 SimCSE 比之前 state-of-the-art 的无监督方法效果提升显著。当加入 NLI 数据集进行监督训练时,SimCSE 模型的效果进一步得到提升,SimCSE-BERT-base 的平均 spearman 相关系数达到 0.8157,SimCSE-RoBERTa-large 的平均 spearman 相关系数达到 0.8376。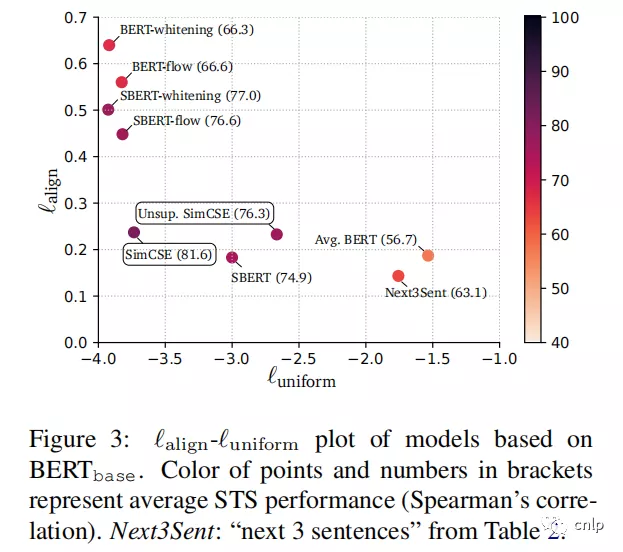
上图为基于 BERT-base 的不同模型的可视化,模型效果越接近左下角越好。圆点的数字代表不同模型在多个 STS 数据集上的平均 spearman 相关系数。
小结:SimCSE 方法上大道至简,在解决像 BERT 这种 Transformer结构出来的 embedding 的各向异性及分布不均匀问题上,提出了一个更简单易行的方案,在有监督及无监督任务上都达到了 SOTA,证明了通过 dropout 构造的样本进行对比学习有效性可行性。
4.4 ESimCSE
ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
ESimCSE是对上述SimCSE构建正负样本方法的改进,主要出发点如下:
- 句子的长度信息通常会被编码,因此无监督的SimCSE中的每个正对长度是相同的。故用这些正对训练的无监督SimCSE 往往会认为长度相同或相似的句子在语义上更相似。
- Momentum Contrast(动量对比)最早是在MoCo提出,是一种能够有效的扩展负例对并同时缓解内存限制的一种方法。ESimCSE借鉴了这一思想来扩展负例。
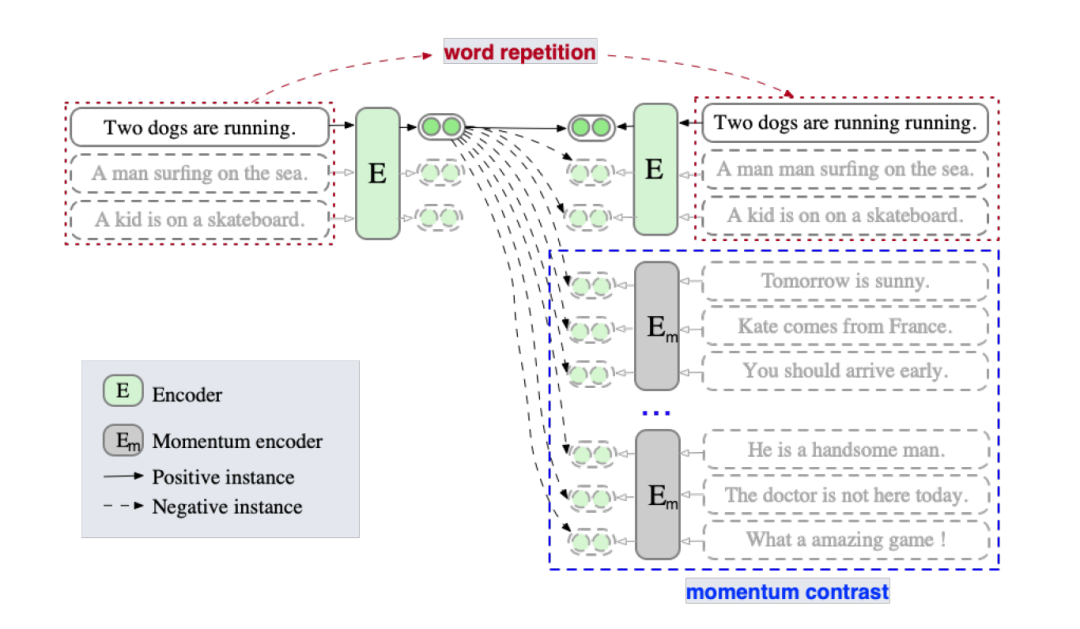
- 正例:作者先探究了句子对的长度差对SimCSE的影响,当长度差大于3时无监督SimCSE模型的效果大幅度降低。为了降低句子长度差异的影响,作者尝试了随机插入、随机删除和词重复三种方法构建正例,发现前两者导致语义相似度下降明显,而词重复可以保持较高的相似度,同时缓解了句子长度带来的问题。故使用word repetition进行正例构造。
- 负例:① in-batch negatives ② 动量更新队列中的样本
损失函数如下(infoNCE loss):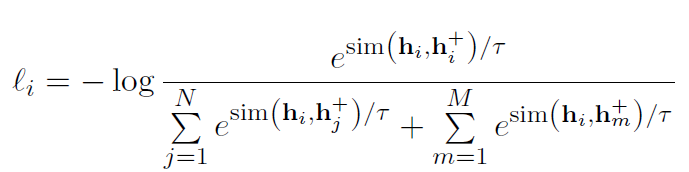
实验表明,ESimCSE整体效果优于无监督的SimCSE,在语义文本相似性(STS)任务上效果优于BERTbase版的SimCSE 2%。
4.5 R-Drop
SimCSE通过简单的“Dropout两次”来构造正样本进行对比学习,达到了无监督语义相似度任务的全面SOTA。SimCSE 利用Dropout本身的随机性,让同一个样本通过得到的结果视为正样本对,而batch内的所有其他样本视为负样本,然后就是通过infoNCE loss来缩小正样本的距离、拉大负样本的距离了。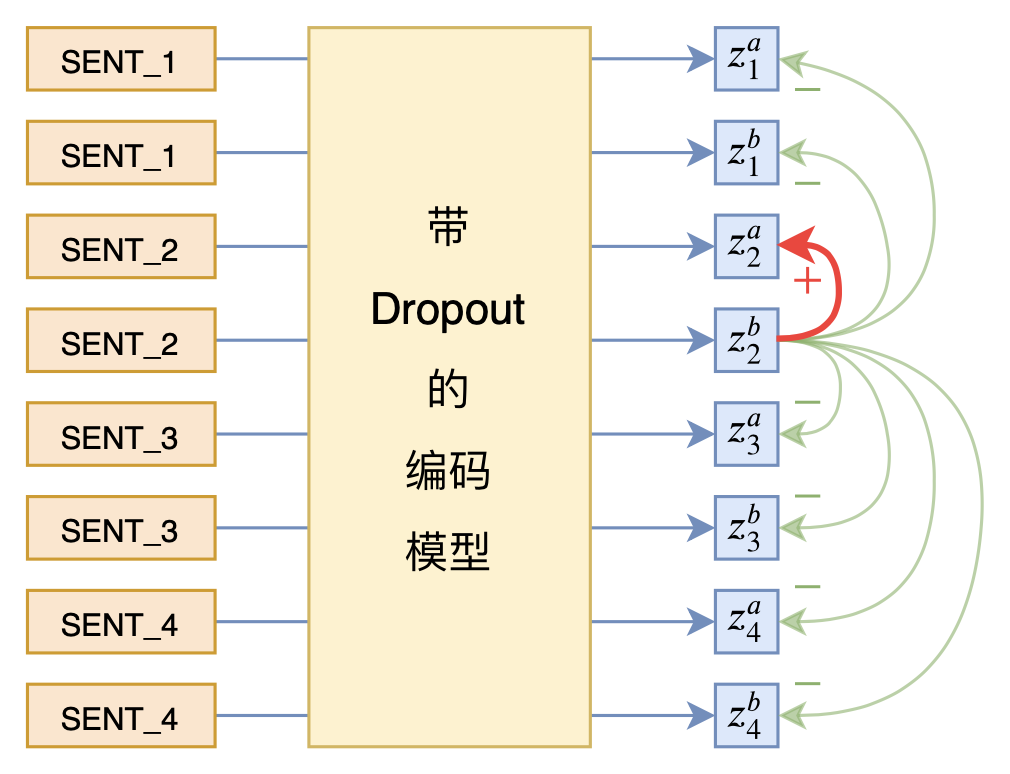
SimCSE示意图
而 R-Drop(Regularized Dropout) 将“Dropout两次”的思想用到了有监督任务中,每个实验结果几乎都取得了明显的提升。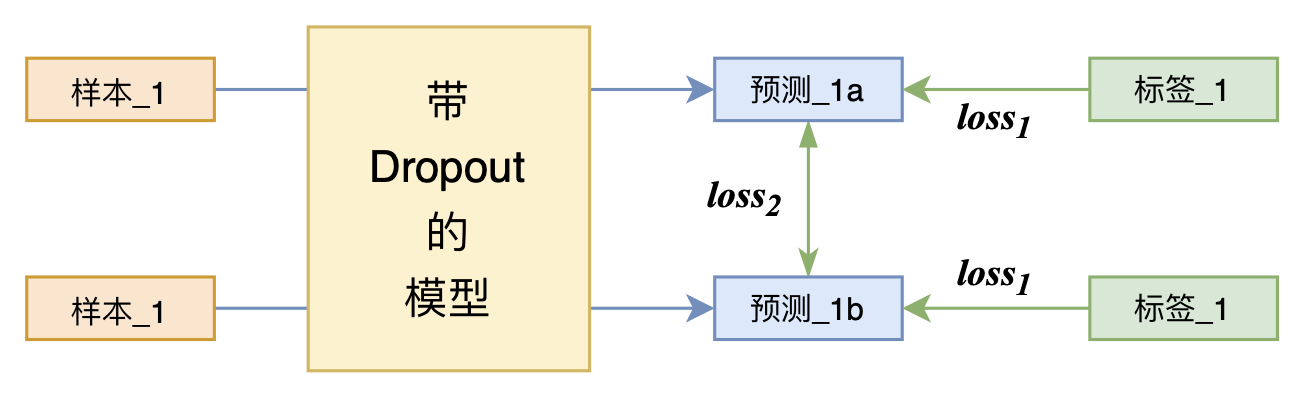
R-Drop示意图

在苏神的R-Drop具体实现中,
- sentiment_ssl.py采用半监督训练。先采样一个batch的标签数据,正常CE训练,然后采样一个batch的无标签数据,KL训练,两者交替训练;
- iflytek.py是有监督训练,二者同时训练;
4.6 Supervised Contrastive Learning
- 文章借鉴并改进self-supervised learning的方法来解supervised 的问题。相较于传统的cross entropy损失函数提升了一个点。并且模型更加robustness和stable。
- 文章主要的创新点在于利用已有的label信息来将自监督的损失函数(如公式1所示)改造成支持multiple positives 和 multiple negatives(如公式2所示)。
 (公式1)
(公式1) (公式2)
(公式2) - 作者通过梯度计算的角度说明了文中提出的loss可以更好地关注于 hard positives and negatives,从而获得更好的效果。
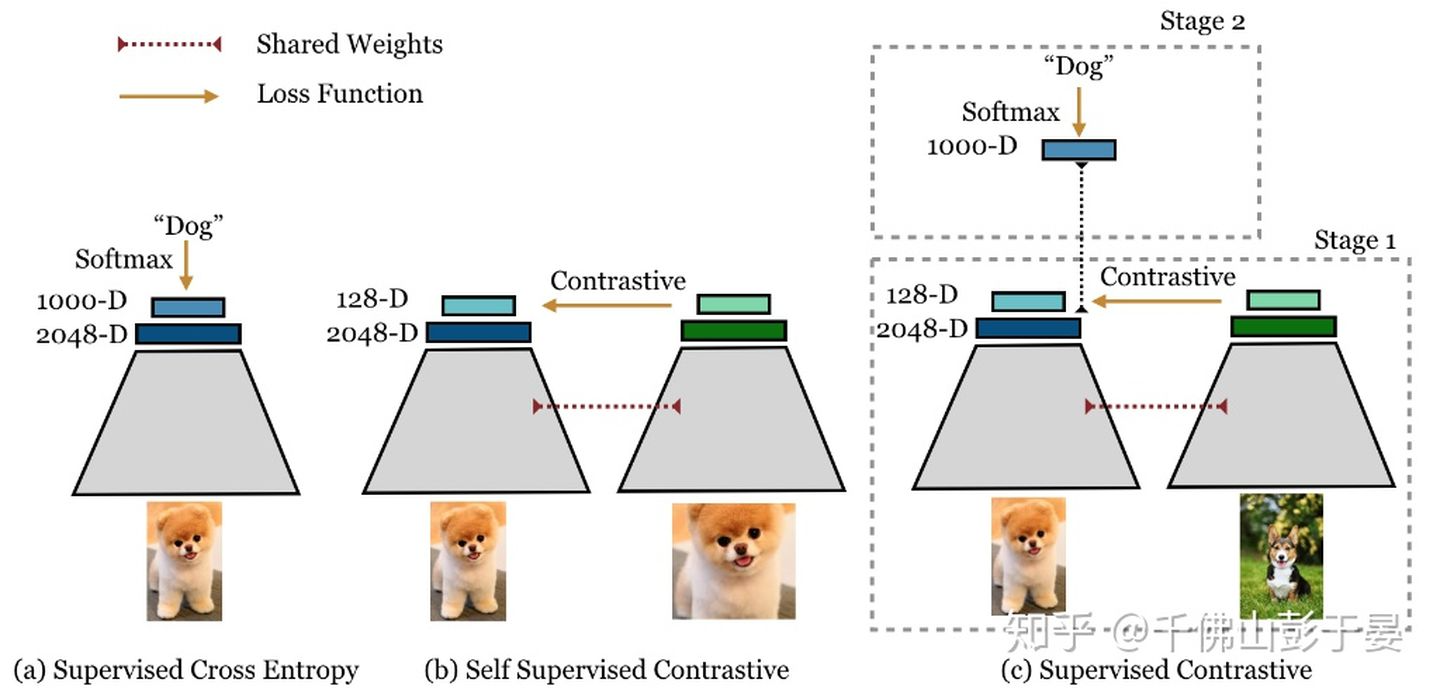
Figure 1: Cross entropy, self-supervised contrastive loss and supervised contrastive loss.
- 如图1所示,对每一幅图像使用两种随机的不同的augmentations,这样就有了2N幅图像作为一个batch。Supervised Contrastive的训练过程包括以下两步:
- 首先,随机sample训练样本,使用文中提出的Supervised Contrastive Learning训练;
- 第二步,固定representation部分的参数,使用cross-entropy训练分类器部分。(如果只需要获取embedding,不需要做分类的话,不需要执行这一步。)
- 实验效果
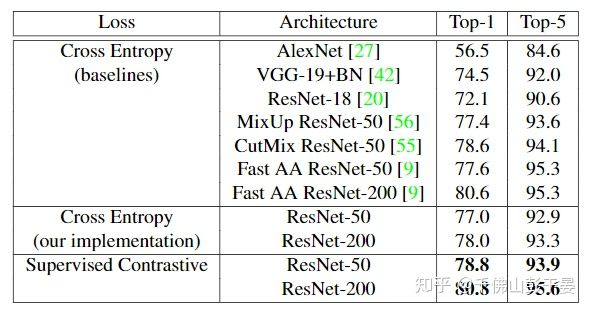
Table 2: Top-1/Top-5 accuracy results on ImageNet on ResNet-50 and ResNet-200 with AutoAugment being used as the augmentation for Supervised Contrastive learning.
- 大力出奇迹的参数设置:batch size设置为8192,训练了700个epoch。作者指出每一步的训练要比cross entropy慢50%。当然,作者也说明减小 batch size和epoch不会掉太多点。
4.7 DiffCSE
论文标题:DiffCSE:Difference-based Contrastive Learning for SentenceEmbeddings 论文来源:NAACL 2022 main conference
作者的方法很简单,将SimCSE中标准的对比学习目标域与基于sentence embeddings的差异预测目标结合。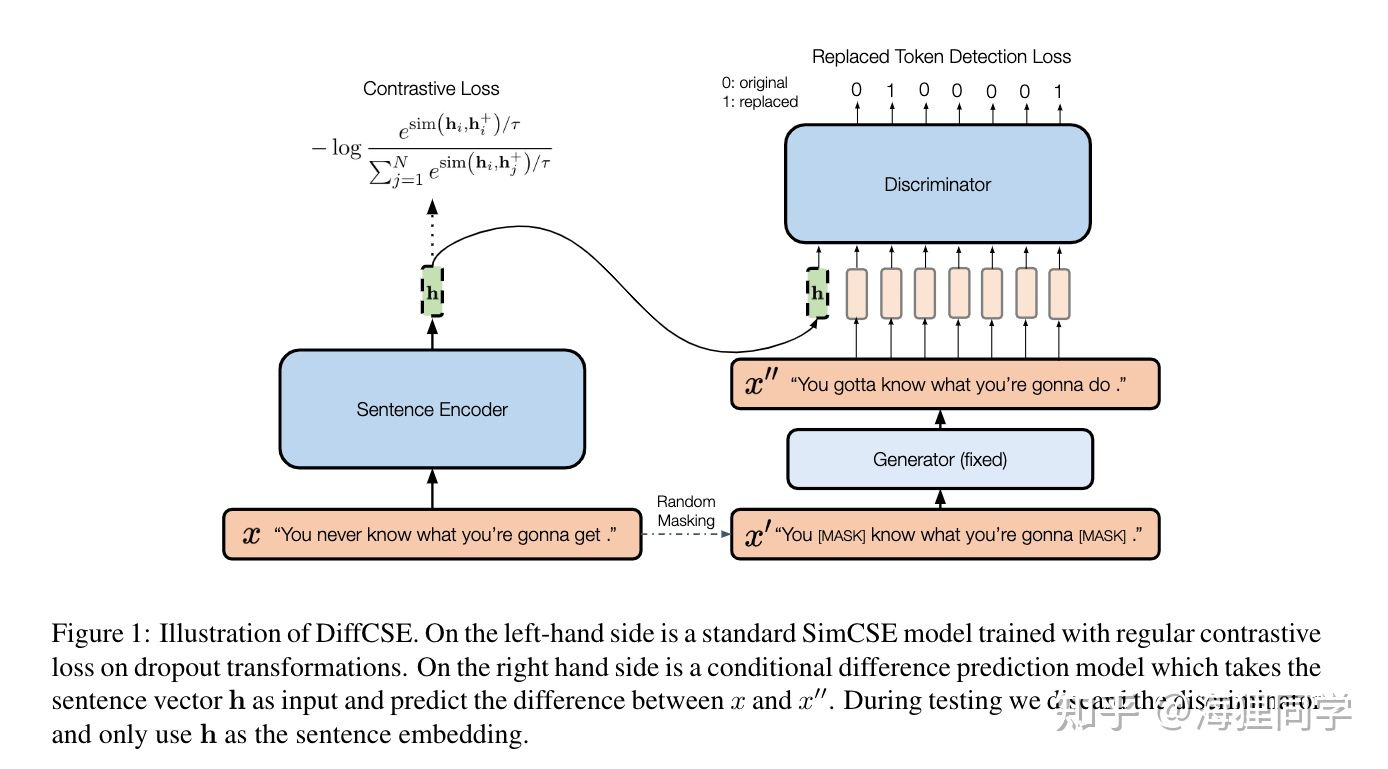
上图的左边即为SimCSE的训练目标: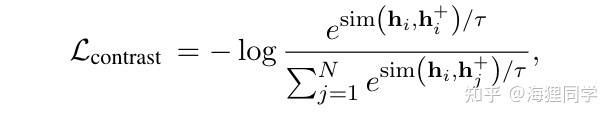
上图的右边ELECTRA中差异预测训练目标的conditional版本。包括generator和discriminator.
对于给定的长度为T的句子x, 在x上进行随机的mask以获得  , 使用预训练好的MLM模型作为generator来恢复mask tokens,得到
, 使用预训练好的MLM模型作为generator来恢复mask tokens,得到  ,使用discriminator来进行替换的token检测的任务(RTD),对于句子中的每一个token,模型需要预测该token是否被替换。
,使用discriminator来进行替换的token检测的任务(RTD),对于句子中的每一个token,模型需要预测该token是否被替换。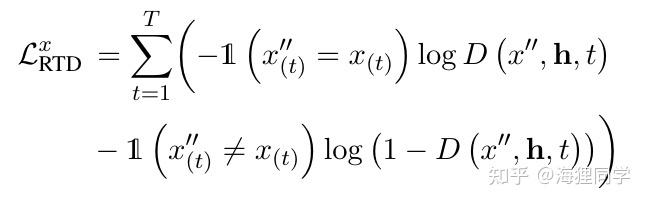
最终的训练目标:
训练过程中固定generator的参数,而优化sentence encoder和discriminator. Discriminator的梯度会反向传播到sentence encoder上,使得sentence encoder能够包含句子x的完整意思,从而使Discriminator能够区分x和  的细微区别。
的细微区别。
实验结果:
下表展示了无监督 DiffCSE 模型在多个英文 STS 数据集上的效果: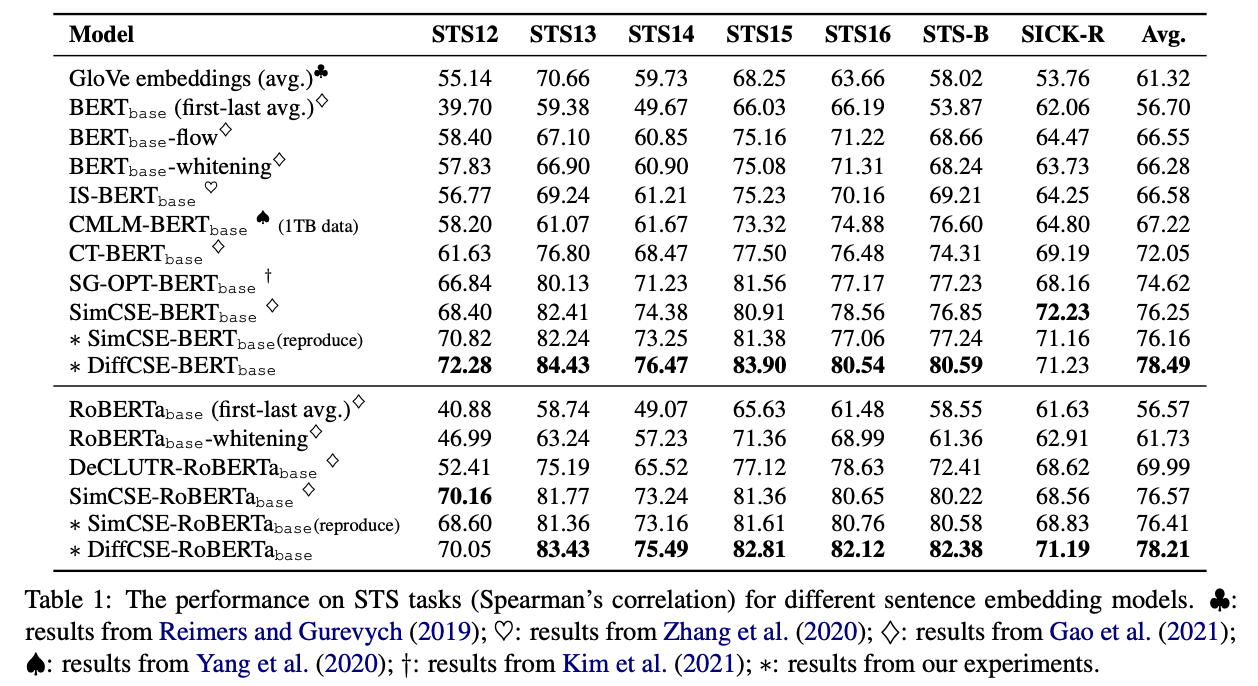
5.对比学习的思考和疑问
- 向量化召回,属于Supervised Learning,无论是U2I, U2U, I2I, 哪两个向量应该是相似的(正例)是根据用户反馈(标注)得到的。
- 因此,在召回算法中,正样本从来就不是问题。大家从来不为找不到正样本而发愁,反而要考虑如何严格正样本的定义,将一些用户意愿较弱的信号(i.e., 噪声)从正样本中删除出去,顺便降低一下样本量,节省训练时间。
- 召回的主要研究目标是负样本,如何构建easy/hard negative,降低Sample Selection Bias。
- 对比学习,属于Self-Supervised Learning (SSL)的一种实现方式,产生的背景是为了解决”标注少或无标注“的问题。
- 我之前说“召回是负样本的艺术”,那么CL更注重的应该是如何构建正样本。
- Data Augmentation是CL的核心,研究如何将一条样本经过变化,构建出与其相似的变体。
- Data Augmentation在CV领域比较成熟了(翻转、旋转、缩放、裁剪、移位等)。而推荐场景下,数据由大量高维稀疏ID组成,特征之间又相互关联,如何变化才能构建出合情合理的相似正样本,仍然是一个值得研究的课题。
1、对比学习 vs. 度量学习 vs. 表征学习
表征学习的目的是对复杂的原始数据化繁为简,把原始数据的无效的或者冗余的信息剔除,把有效信息进行提炼,形成特征(feature)。特征提取可以人为地手工处理,也可以借助特定的算法自动提取。Roughly Speaking, 前者为特征工程,后者为表征学习(Representation Learning)。
而度量学习 (Deep metric learning) 是把这个representation的学习看作是 distance calculation 的一部分了,因此是一种implicit representation learning。学习好的representation不是最终的目的?最终目的而是为了度量相似的物体离得近,不相似的离得远?
- 度量学习多为二元组或三元组的形式,如常见的Siamese network和Triplet network
- Hard Negative 的挖掘对度量学习的最终效果有较大的影响
- metric learning提出了这么多数学上优雅的loss function
对比学习属于度量学习,本质都是去拉近相似的样本,推开不相似的样本,从而学习一个具有极强表达能力的表征空间。但是对比学习是无监督或者自监督学习方法,而度量学习一般为有监督学习方法。而且对比学习在 loss 设计时,为单正例多负例的形式,因为是无监督,数据是充足的,也就可以找到无穷的负例,但如何构造有效正例才是重点。
2、对比学习中一般选择一个 batch 中的所有其他样本作为负例,那如果负例中有很相似的样本怎么办?
答:加大 batch size,以降低 batch 训练中采样到伪负例的概率,减少它的影响
3、infoNCE loss 如何去理解,和 CE loss有什么区别?
答:infoNCE loss 全称 info Noise Contrastive Estimation loss,对于一个 batch 中的样本 i,它的 loss 为: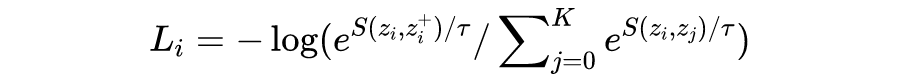
CE loss,Cross Entropy loss: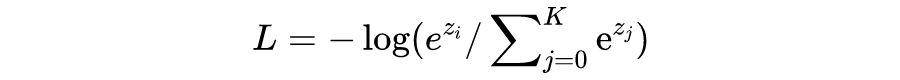
看的出来,info NCE loss 和在一定条件下简化后的 CE loss 是非常相似的,但有一个区别要注意的是:infoNCE loss 中的 K 是 batch 的大小,是可变的,是第 i 个样本要和 batch 中的每个样本计算相似度,而 batch 里的每一个样本都会如此计算,因此上面公式只是样本 i 的 loss。CE loss 中的 K 是分类类别数的大小,任务确定时是不变的,i 位置对应标签为 1 的位置。
4、对比学习的 infoNCE loss 中的温度常数的作用是什么?
答:温度系数的作用是调节对困难样本的关注程度:越小的温度系数越关注于将本样本和最相似的困难样本分开,去得到更均匀的表示。然而困难样本往往是与本样本相似程度较高的,很多困难负样本其实是潜在的正样本,过分强迫与困难样本分开会破坏学到的潜在语义结构,因此,温度系数不能过小。
考虑两个极端情况,温度系数趋向于 0 时,对比损失退化为只关注最困难的负样本的损失函数;当温度系数趋向于无穷大时,对比损失对所有负样本都一视同仁,失去了困难样本关注的特性。
5、SimCSE 中的 dropout mask 指的是什么,dropout rate 的大小影响的是什么?
答:SimCSE 中的 dropout mask,对于 BERT 模型本身,是一种网络模型的随机,是对网络参数 W 的 mask,起到防止过拟合的作用。
而 SimCSE 巧妙的把它作为了一种 noise,起到数据增强的作用,因为同一句话,经过带 dropout 的模型两次,得到的句向量是不一样的,但是因为是相同的句子输入,最后句向量的语义期望是相同的,因此作为正例对,让模型去拉近它们之间的距离。
6、对比学习 和 一般的预训练 如何结合起来使用?
由于对比学习是对相对空间中的向量表示,单纯地运算相对关系算力要求很高【Batch size 巨大】【SimCLR暴力美学证明可以纯算,但一般做不起】,一般作为其他模型绝对空间相对准确后的对任务的相对微调。
比如说,Bert能使空间词向量绝对空间的位置,相对准确,但是针对某些任务,它的聚类效果不够好,我们使用对比学习调整它们间的相对关系,从而适应我们的任务。
7、对比学习 和 下游任务 怎么结合?
两者联合训练 还是 分阶段训练?从现在的实验来看,先与下游任务进行有监督的联合训练(CL+任务),然后再在下游任务上无监督的训练(CL),效果最好。
6.大厂关于对比学习实践
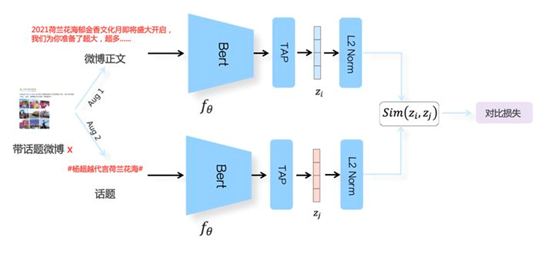
微博在自然语言处理场景中利用对比学习构建了CD-TOM模型(Contrastive Document-Topic Model)。将同一微博中的<文档,话题>数据对作为训练数据通过对比学习构建表示学习模型,将微博正文和话题映射到同一表示空间中,从而使得语义相近的正文和话题距离拉近,语义不相近的距离拉远。通过这种方式可以获得微博正文和话题的高质量embedding用于下游任务中。CD-TOM模型结构如下图所示:
用对比学习解释经验做法:(张俊林总结的非常好)
做召回有三个做法:in-batch负例,要带温度超参,embedding要做Norm。因为是经验做法,现在并没有人给出解释,为什么要这么做。如果把目前的召回模型看做是对比学习的一种变体,你就可以用对比学习的理论来解释这三种做法背后的道理。
- ① 双塔模型随机负例的作用是什么
- ② 温度超参的作用是什么
- ③ Embedding为什么要做Norm
7.对比学习个人实践

总结
本文粗略的介绍了一下对比学习的思想与方法,以及一系列在图像、文本上的工作。对比学习在语义表示学习上的能力有目共睹,但还有一些问题,比如在自然语言领域,复杂的数据增强方式反而不如简单的dropout,这有没有可能是由于自然语言对扰动语义鲁棒性不强导致的呢?同时,CV领域的对比学习已经可以不用负例,那在NLP领域是不是也会有相似的发展轨迹呢?让我们拭目以待!


参考
赛尔笔记 | 对比学习√
对比学习(Contrastive Learning):研究进展精要 | 张俊林
张俊林:从对比学习视角,重新审视推荐系统的召回粗排模型√
对比学习(Contrastive Learning)综述
从对比学习(Contrastive Learning)到对比聚类(Contrastive Clustering)
ACL 2021|美团提出基于对比学习的文本表示模型,效果相比BERT-flow提升8%√
进入BERT时代,向量语义检索我们关注什么-丁香园
文本表达进击:从BERT-flow到BERT-whitening、SimCSE√
有关对比学习的综述,看看这个挺好的:https://zhuanlan.zhihu.com/p/346686467
而有关NLP的对比学习,可以看看这篇文章:https://zhuanlan.zhihu.com/p/334732028
美团的ConSert:https://mp.weixin.qq.com/s/C4KaIXO9Lp8tlqhS3b0VCw
2021最新对比学习(Contrastive Learning)在各大顶会上的经典必读论文解读
基于对比学习(Contrastive Learning)的文本表示模型为什么能学到语义相似度?
业界总结 | 如何改进双塔模型,才能更好的提升你的算法效果?
对比学习(Contrastive Learning):研究进展精要 | 张俊林
利用Contrastive Learning对抗数据噪声:对比学习在微博场景的实践 | 张俊林
谈一谈对比学习-哈工大 SCIR-介绍了一下对比学习的思想与方法,以及一系列在图像、文本上的工作
🍑Contrastive Representation Learning-Lil’Log
对比学习在NLP和多模态领域的应用

若有收获,就点个赞吧
0 人点赞
