先给出方法总结(主要参考自nlp中的实体关系抽取方法总结Q2-JayJay):
修改BIO 标签:比如B-city和 B-organization 组合为 B-city|organization
简单,改动小;但是导致标签稀疏,难以学习;
修改模型的Decoder
①token-level 的多标签分类:比如B-city(1)、B-organization(1)、其他(0)
②采用指针网络,转化为n个2元Sigmoid分类预测头指针和尾指针:比如针对 city,预测头(1 0 0 0),预测尾(0 1 0 0)
③转换成阅读理解问题:比如“[CLS]北京大学[SEP]提及的城市是啥”,类似 prompt的模板拼接;
④采用GlobalPointer,解决指针网络的Exposure Bias问题;对句子所有n-gram进行分类;
嵌套实体问题
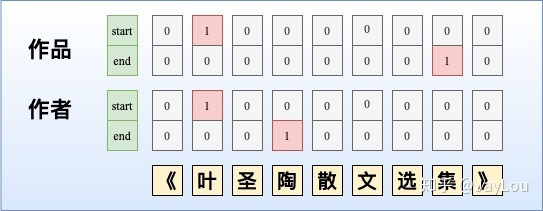
NER是一个比较常见的NLP任务,通常采用LSTM+CRF处理一些简单NER任务。NER还存在嵌套实体问题(实体重叠问题),实体嵌套是指在一句文本中出现的实体,存在某个较短实体完全包含在另外一个较长实体内部的情况,如「《叶圣陶散文选集》」中会出现两个实体「叶圣陶」和「叶圣陶散文选集」分别代表「作者」和「作品」两个实体。而传统做法由于每一个token只能属于一种Tag,无法解决这类问题。下面归纳了几种常见并易于理解的解决办法:
1、序列标注:SoftMax和CRF
命名实体识别本来属于基于字(token-level)的多分类问题,通常采用CNNs/RNNs/BERT+CRF处理这类问题,与SoftMax相比,CRF进了标签约束。但由于这种序列标注采取BILOU标注框架,每一个token只能属于一种,不能解决重叠实体问题,如图所示。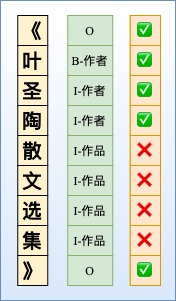
基于BILOU标注框架,下面列出2种改进方法解决实体重叠问题:
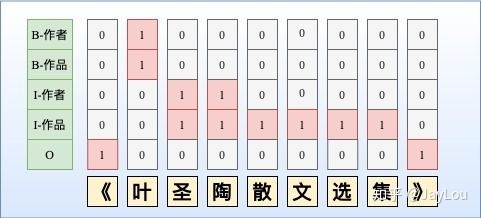
- 改进方法1:采取token-level 的多label分类,将SoftMax替换为Sigmoid,如图所示。当然这种方式可能会导致:1)label之间依赖关系的缺失,可采取后处理规则进行约束。2)学习难度较大
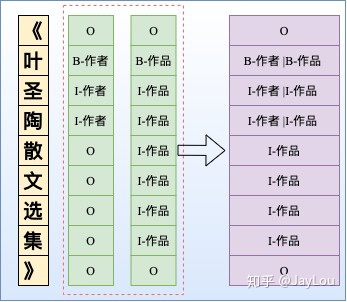
- 改进方法2:依然采用CRF,但设置多个标签层,对于每一个token给出其所有的label,然后将所有标签层合并。显然这可能会导致:1)增加label数量,导致label不平衡问题。2)指数级增加了标签3)对于多层嵌套,稀疏问题较为棘手
2、Span抽取:指针网络
指针网络(PointerNet)最早应用于MRC中,而MRC中通常根据1个question从passage中抽取1个答案片段,转化为2个n元SoftMax分类预测头指针和尾指针。对于NER可能会存在多个实体Span,因此需要转化为n个2元Sigmoid分类预测头指针和尾指针。
将指针网络应用于NER中,可以采取以下两种方式:
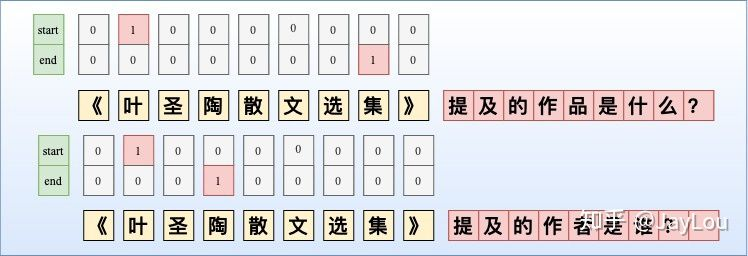
- 第一种:MRC-QA+单层指针网络。构建query问题指代所要抽取的实体类型,同时也引入了先验语义知识。对不同实体类型构建query,并采取指针标注,此外也构建了矩阵来判断span是否构成一个实体mention。如图所示,由于构建query问题已经指代了实体类型,所以使用单层指针网络即可;除了使用指针网络预测实体开始位置、结束位置外,还基于开始和结束位置对构成的所有实体Span预测实体概率。此外,这种方法也适合于给定事件类型下的事件主体抽取,可以将事件类型当作query,也可以将单层指针网络替换为CRF。
- 第二种:多层label指针网络。由于只使用单层指针网络时,无法抽取多类型的实体,我们可以构建多层指针网络,每一层都对应一个实体类型。
需要注意的是:
- MRC-QA会引入query进行实体类型编码,这会导致需要对愿文本重复编码输入,以构造不同的实体类型query,这会提升计算量。
- n个2元Sigmoid分类的指针网络,会导致样本Tag空间稀疏,同时收敛速度会较慢,特别是对于实体span长度较长的情况。
3、片段排列+分类
上述序列标注和Span抽取的方法都是停留在token-level进行NER,间接去提取span-level的特征。而基于片段排列的方式,显示的提取所有可能的片段排列,由于选择的每一个片段都是独立的,因此可以直接提取span-level的特征去解决重叠实体问题。
对于含T个token的文本,理论上共有 (T+1)/2种片段排列。如果文本过长,会产生大量的负样本,在实际中需要限制span长度并合理削减负样本。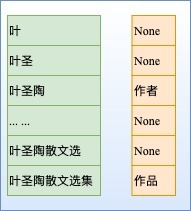
需要注意的是:
- 1)实体span的编码表示:在span范围内采取注意力机制与基于原始输入的LSTM编码进行交互。然后所有的实体span表示并行的喂入SoftMax进行实体分类。
-
4、Seq2Seq
ACL2019的一篇paper中采取Seq2Seq方法[3],encoder部分输入的原文tokens,而decoder部分采取hard attention方式one-by-one预测当前token所有可能的tag label,直至输出
(end of word) label,然后转入下一个token再进行解码。 参考
- 浅谈嵌套命名实体识别(Nested NER)

若有收获,就点个赞吧
0 人点赞
