心法利器[51] | 长短句语义相似问题探索
工业界的很多应用都有在语义上衡量文本相似度的需求,我们将这类需求统称为“语义匹配”。
根据文本长度的不同,语义匹配可以细分为三类:
- 短文本-短文本语义匹配
- 短文本-长文本语义匹配
- 长文本-长文本语义匹配
短文本-短文本语义匹配
该类型在工业界的应用场景很广泛。如,在网页搜索中,需要度量用户查询(Query)和网页标题(web page title)的语义相关性;在Query查询中,需要度量 Query和其他 Query之间的相似度。
由于主题模型在短文本上的效果不太理想,在短文本-短文本匹配任务中 词向量的应用 比主题模型更为普遍。简单的任务可以使用Word2Vec这种浅层的神经网络模型训练出来的词向量。如,计算两个Query的相似度, q1 = “推荐好看的电影”与 q2 = “2016年好看的电影”。
- 通过词向量按位累加的方式,计算这两个Query的向量表示
- 利用余弦相似度(Cosine Similarity)计算两个向量的相似度。
对于较难的短文本-短文本匹配任务,考虑引入有监督信号并利用“DSSM”或“CLSM”这些更复杂的神经网络进行语义相关性的计算。
短文本-长文本语义匹配
无论长-长还是长-短,其实没什么太大差别,本质还是要解决长句信息冗余的问题。
这里介绍几个关键思路:
- 在计算相似度的时候,我们规避对短文本直接进行主题映射,而是根据长文本的主题分布(如 sentence LDA),计算该分布生成短文本的概率,作为他们之间的相似度。
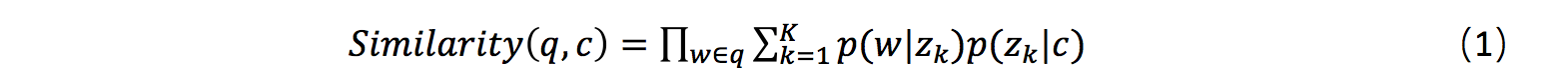
其中,q表示Query,c表示content, w表示q中的词, 表示第k个主题。
表示第k个主题。
- 其次,针对长-短这种情况,考虑使用单向句子相似度的方案,之前我提到的ctr-cqr(心法利器[18] | cqr&ctr:文本匹配的破城长矛)其实就是单向的相似度,短句对应的相似度偏高的一般都是可以认为相似的。
- 第三,模型层面的控制。长句的匹配核心需要考虑的是两句的关键信息是否相同,所以attention是非常关键的措施,这也是为什么attention机制为什么会受到关注的原因,尤其是交互式,能充分提取两个句子两者视角下的关键信息从而进行匹配,能更契合这种问题,早期abcnn之类的方案其实都有体现出这个思想出来。
- 第四,根据信息弥散情况对容忍度进行控制。在前面的分析汇总我们其实可以发现,句子越长,其实相似度会更倾向于下降,这个无可厚非,但既然如此,我们是可以设计一个机制,对语义相似度的阈值进行控制,随着句子长度的增加降低认为是相似的阈值,这种方式也能有一定收益。
- 第五,就是把多种和长度相关的因素构造成特征,用类似wide&deep的模式将语义信息和长度信息,甚至是单向句子相似度信息进行整合,构造出一个合体模型来处理,当然这样的构造方式,其实就已经是将语义相似度任务在向精排模型之类的方向过渡了。
cqr&ctr 方案介绍
搜索也好,检索式对话也好,文本是一个很难绕开的话题,虽然语义是一个重要因素,用语义相似度直接梭,但是用户的感知可不是如此,很多用户的感知更多是文本层面的相似要高于语义相似,或者说,遇到语义相似和文本相似的时候会更优先接受文本相似,毕竟文本使用户能直接看到的,当然语义相似度虽好,但是对于没有什么标注数据的情况,也是束手无策吧。
所以,即使语义相似度如火如荼地发展着,文本层面的匹配依旧是项目实践中不可避免的关注点。
cqr&ctr概念
cqr和ctr的概念还是比较清晰明确的。
给定query和title,现在计算cqr和ctr: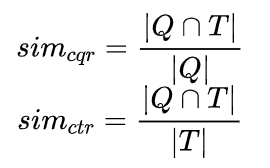
讲完了,就是这么简单,其实就是看两者交集占query的占比和占title的占比,就是对应的cqr和ctr。
当然,由于这种计算会把所有词的重要性考虑进去,例如“怎么做作业”分别和“怎样做作业”、“怎么做手机”,两个的相似度就一样了,此时就要考虑到给每个词加点权重,这样能更好地描述,这就是一个优化的实用版本,加权
给定query 对应的权重
对应的权重 和 title
和 title 对应权重
对应权重 ,现在计算cqr和ctr:
,现在计算cqr和ctr: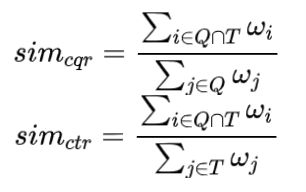
想到可能会有人问到权重怎么来,这里我就要把我的历史文章放出来了,之前是专门讲过词权重的问题的:NLP.TM[20] | 词权重问题
这个应该就是我自己平时用的版本了,而且屡试不爽。
而如果是要分析两个句子综合、无偏的相似度,只要相乘就好了: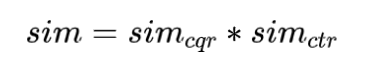
细品
可以看到,这个东西很简单,就是一个基于统计计算的工具,但是我依然想仔细讨论一下这个东西。
首先,有关相似度,其实我们很容易想到这个计算方法: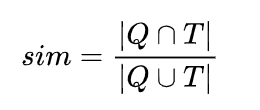
就是比较著名的jaccard相似度,当然还有一个更加出名的方法,那就是BM25(更为常见,此处就不赘述了)。但是我并没有选择,为什么呢,其实核心就是1个点:
query和title的长度信息。
jaccard距离虽然能比较综合、无偏向性地计算两者的相似度,但问题是,当query和title长度计算差距很大的时候,计算准确性就会受到影响,而分成两个指标,则能够充分表现两者的相似性,当然具体用哪种其实还是要看具体场景的,有的时候这种无偏向性对效果优化还是有用的,但是有的时候其实会影响最终效果。
来看个例子,query是“我昨天新买的手机,今天怎么就不能开机了”,title是“手机不能开机”,这里可以,ctr无疑就是1,当然cqr就比较低了,但是我们可以用ctr作为后续的排序特征或者过滤条件。
优缺点
感觉有些东西想说但是没说出来,直接总结一下这个方案的优缺点吧,以便大家进行方案选择吧,这个优点,是相对于常见的语义相似度模型而言的。
首先说优点:
- 能够体现文本层面的相似度,在一些领域下体验比较好。
- 性能比语义相似度模型好很多,所以是一个简单轻快的模型。
- 无监督,词权重的话用语料就可以训练了。
- 效果稳定可追踪。
当然,还是有缺点的。
- 文本层面的匹配无法体现语义,同义词、说法之类的无法体现。
- 对切词敏感,类似“充不进去电”和“充电”就完全匹配不上。
词权重计算问题
term weighting计算,其实就是给句子中每个词汇打分,体现他们的重要性,这种问题就被称为词权重问题。
无监督方法
首先最为简单的基线方法就是TF-IDF了,这个经典的词袋模型,哪怕是现在预训练模型称霸,仍有一席之地,就在于其简单而且效果还真的不错。引用刘知远教授在知乎中对TF-IDF的评价。
TFIDF是很强的baseline,具有较强的普适性,如果没有太多经验的话,可以实现该算法基本能应付大部分关键词抽取的场景了
所以不要嫌弃TF-IDF方法,做基线的效果真的挺不错的。至于有关TF-IDF的计算,下面提供两个比较简单的方案:
- jieba中本身就有关键词提取功能,具体可以去看TF-IDF的文档,无论是c++,还是python都有。
- sklearn中有在TfidfTransformer和TfidfVectorizer,可以自己使用语料训练。
当然的,说到TF-IDF,其实就会说到TextRank了,作为从PageRank迁移来的舶来品,且对语料依赖性不强,一直受到不少人的喜爱,jieba、HanNLP中都有集成,但是有一个比较多人诟病的问题在于计算复杂度比较高,结果提升相比tfidf虽有,但是时间代价比较大,这也导致TF-IDF被更多项目选择。
当然了,上述term-weighting的方法其实都是非常常规的,但这也正好是不可干预的,针对不同的问题其实是需要一些特异性干预措施的,下面给大家一些建议,大家可以参考。
首先,先说怎么干预,干预说白了就是去调整原始的term weighting计算,使其达到自己的预期,那么调整的手段,主要有两个:
- 加性调整。即满足某些条件下,给term weighting加减分数,这种调整往往给一些词汇结果带来质变。
- 乘性调整。即满足某些条件下,让term weighting乘一个数值,很容易可以看到乘以大于1的数其实就是在提升重要性,乘以小于1的数其实就是在降低重要性。
那么可以根据什么来做这些干预呢,下面给一些信息:
- 词性,非常重要的,在一般场景下,名词、动词等实词往往是关键词,语气词、疑问词、虚词则基本上不是关键词,因此我们可以给予调整,词性标注可以参考jieba。
- 实体识别。在有实体识别的帮助下,特定领域下上游会有实体识别计算,此时可以根据实体识别结果来给予提降权。这块的效果是最明显的,但也是最可遇不可求的,毕竟你上游不一定有实体识别。
- 位置。根据中文的语言特性,句子中的特殊位置往往有特定的重要性,一般地,句子靠前或者靠后位置往往跟个容易出关键词,可以通过指数衰减的方式进行提降权,在语言模型里面,其实也有position embedding的说法,可见其重要性。
- 左右熵等指标,结合TFIDF会有一些特别的效果。
- 上下文的信息。有时候上下文的词性、实体识别结果其实都会对本位点的预测有好处。
由于是无监督学习,加上调权是人工干预,无法探测大规模的结果,只能通过case分析,所以一般的操作是,针对少量case,例如100个,去分析和调整权重,结果调整好后,再用另一批少量样本,例如100个去做测试,查看召准。

若有收获,就点个赞吧
0 人点赞
