论文链接:An end-to-end Generative Retrieval Method for Sponsored Search Engine
论文解读:https://zhuanlan.zhihu.com/p/107573798
背景
本文提出一种端到端的生成式检索方法,针对用户查询query,为商业搜索引擎生成「关键词」。生成式检索方式的优势在于省去了query改写、改写后query的检索、相关性模型等中间过程,从而避免累进误差;
但是生成式检索方法有以下几个挑战:
- 最大挑战在于解码过程的效率,标准的beam search过程难以满足工业级产品的需求;
- 生成bidword属于封闭集合,与标准的NMT不同;
- 作为主检索分支的辅助,生成式检索最好可以触发更多的未检索词。
技术方案
针对上述挑战,本文分别给出了相应的解决方案: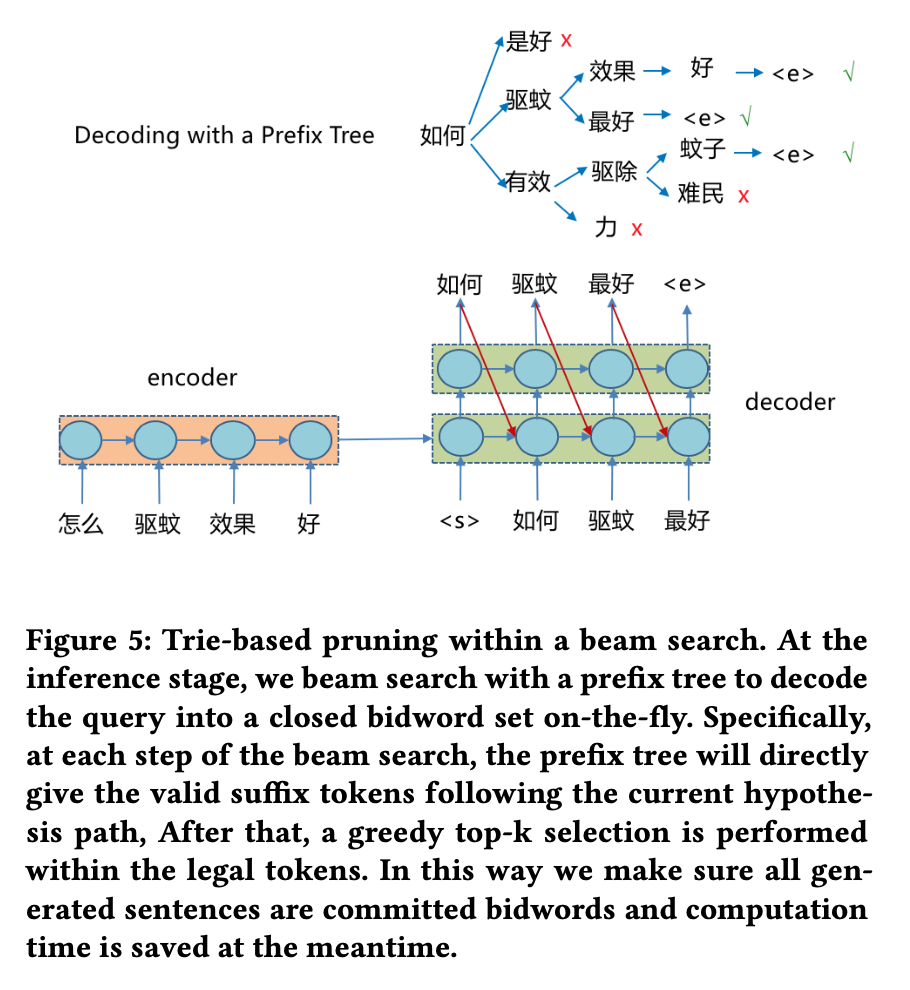
- 提出在beam search式采用基于Trie树的剪枝方法:将目标bidword词建立成Trie树结构,在decode过程中根据beam中的前项序列在Trie树中搜索候选的后项单词,只保留 suffix 中的有效后缀,其他 token 将被剪掉。这样可以大幅缩减搜索空间及计算开销,同时也解决了bidword属于封闭集合的问题。

- 提出自归一化(self-normalization)技术:在训练过程中,损失函数中显式加入正则项,使得softmax的分母项接近1,这样在预测的时候,即可省去对softmax分母项的计算,极大降低了计算开销(提速20倍)。
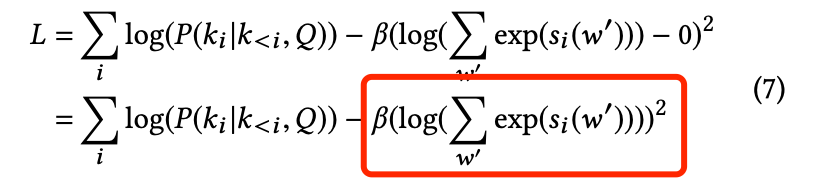
- 为了让生成式模型能够生成更多的未检索词,在训练过程中不采用广告点击log(“query-keyword”点击对),这是因为这样训练出的模型与现有线上模型能力一致;而是采用搜索的自然点击log(“query-title”点击对),这样训练出的模型能够生成更多样化的词汇。
Full Algorithm

实验
(1)训练数据集
采用搜索的自然点击log(“query-title”点击对)数据,从Baidu一个月内用户点击log中进行采样,得到7.49亿“query-title” pair。词表大小42000。
(2)主要实现细节
模型学习采用Adam优化,参数采用Xavier初始化。初始学习率为0.0005,batch size为128。隐向量维度为512。
- 采用在线-离线结合的架构:对于频繁query,采用离线模型事先计算好,模型结构复杂;对于非频繁query,采用在线模型,模型结构简单。其中,离线模型采用一个4层的LSTM encoder和一个4层的LSTM decoder(带attention);在线模型采用单层GRU encoder和单层带attention的GRU decoder。
自归一化和基于Trie树的剪枝技术在离线和在线模型处理时均使用。
(3)主要实验结果
解码效率(计算时间开销)提升20倍左右,beam size在40-100时,由baseline的443-1125ms,可以降低到25-32ms。
- 相关性评估结果(人工标注评测)显示,生成的关键词的质量提升明显,Good (+6.6%),Fair (+3.1%),Bad (-20.7%)。

若有收获,就点个赞吧
0 人点赞
