摘要
神经网络越深,训练越困难。我们提出了一种减轻网络训练负担的残差学习框架,比现有网络本质上层次更深。我们根据层输入显式地将层重新表示为学习残差函数,而不是学习未定义函数。同时,我们提供了全面实验数据,这些数据证明残差网络更容易优化,并且可以从深度增加中大大提高精度。在ImageNet数据集上,残差网络的深度可达152层—是vgg网络的8倍深,但仍然具有较低的复杂性。这些残差网的集合在ImageNet上的误差率为3.57%。这个结果在ILSVRC 2015分类任务上赢得了第一名。我们也在CIFAR-10上分析了100层和1000层的残差网络。对于许多视觉识别任务而言,表示的深度是至关重要的。仅仅由于我们的表示非常深入,我们在coco目标检测数据集上得到了28%的相对改进。 深度残差网络是我们参加ILSVRC & COCO 2015 竞赛上所使用模型的基础,并且我们在ImageNet检测、ImageNet定位、COCO检测以及COCO分割上均获得了第一名的成绩。
深度网络训练难题
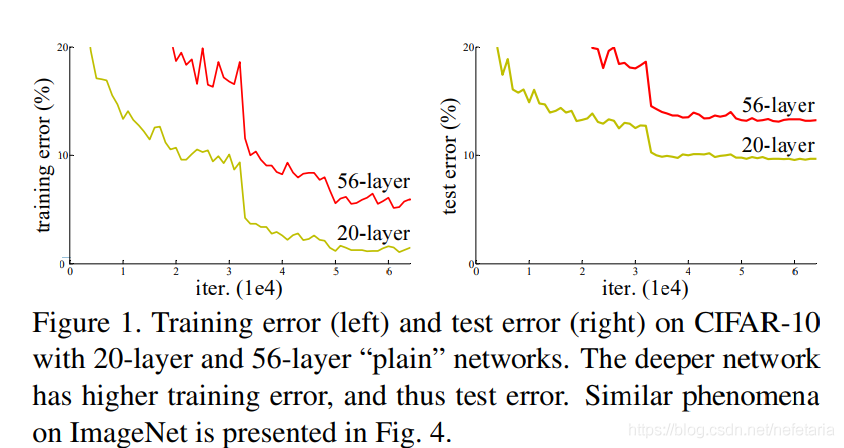
深度卷积神经网络随着深度的加深,获取到更丰富的特征,许多视觉识别任务选择使用非常深的网络模型。深度卷积神经网络实现中最大的障碍是梯度消失问题,梯度消失阻碍了收敛。当前的解决方法是标准化初始化和中间归一化层,应对数十层的深度神经网络有效果。但是当网络能够收敛时,该论文发现了另外一个问题,网络退化(degradation),随着模型的深度加深,学习能力增强,更深的模型不应当产生比它更浅的模型更高的错误率。而这个“退化”问题产生的原因归结于优化难题,当模型变复杂时,反向传播的随机梯度下降(SGD)的优化变得更加困难,导致了模型达不到好的学习效果。给出数据证实这一点:图1:在20层和56层纯网络的CIFAR-10上,训练误差(左)和测试误差(右)。网络越深,训练误差越大,测试误差越大。
残差深度学习
为了解决网络退化问题,该论文提出了深度残差学习框架。假设原来要学习的函数为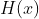 ,换一个角度来看,
,换一个角度来看, 可以理解为层输入
可以理解为层输入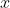 和残差函数
和残差函数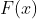 的加和,即
的加和,即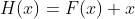 ,这两种表达的效果相同,但是优化的难度却并不相同,作者假设F(x)的优化 会比H(x)简单的多。在极端情况下,如果一个恒等映射是最优的,那么将残差置为零比通过一堆非线性层来拟合恒等映射更容易。图2中是一个残差构建模块(building block),通过shortcut connection将这个block的输入和输出进行一个element-wise的加叠,这个简单的加法并不会给网络增加额外的参数和计算量,同时却可以大大增加模型的训练速度、提高训练效果,并且当模型的层数加深时,这个简单的结构能够很好的解决退化问题。
,这两种表达的效果相同,但是优化的难度却并不相同,作者假设F(x)的优化 会比H(x)简单的多。在极端情况下,如果一个恒等映射是最优的,那么将残差置为零比通过一堆非线性层来拟合恒等映射更容易。图2中是一个残差构建模块(building block),通过shortcut connection将这个block的输入和输出进行一个element-wise的加叠,这个简单的加法并不会给网络增加额外的参数和计算量,同时却可以大大增加模型的训练速度、提高训练效果,并且当模型的层数加深时,这个简单的结构能够很好的解决退化问题。
 我们对每几个层叠的层次采用残差学习。使得这些层学习的是需要拟合函数的残差,而不是原函数,并形成如Fig.2所示的building block结构;当输入、输出通道数相同时,我们自然可以如此直接使用X进行相加。而当它们之间的通道数目不同时,我们就需要考虑建立一种有效的identity mapping函数从而可以使得处理后的输入X与输出Y的通道数目相同。
我们对每几个层叠的层次采用残差学习。使得这些层学习的是需要拟合函数的残差,而不是原函数,并形成如Fig.2所示的building block结构;当输入、输出通道数相同时,我们自然可以如此直接使用X进行相加。而当它们之间的通道数目不同时,我们就需要考虑建立一种有效的identity mapping函数从而可以使得处理后的输入X与输出Y的通道数目相同。
网络结构
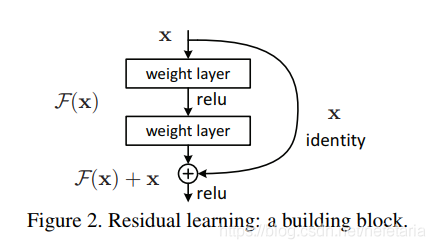
作者用三种网络结构在Imagenet上进行对比实验,证实了深度残差网络的性能。如下图左边为VGG19模型(196亿个FLOPs),中间为34层的plain网络(36亿个FLOPs),以这两个网络的性能作为对比,测试34层残差网络(36亿个FLOPs)的性能。图中虚线所表示的shortcuts增加了维度。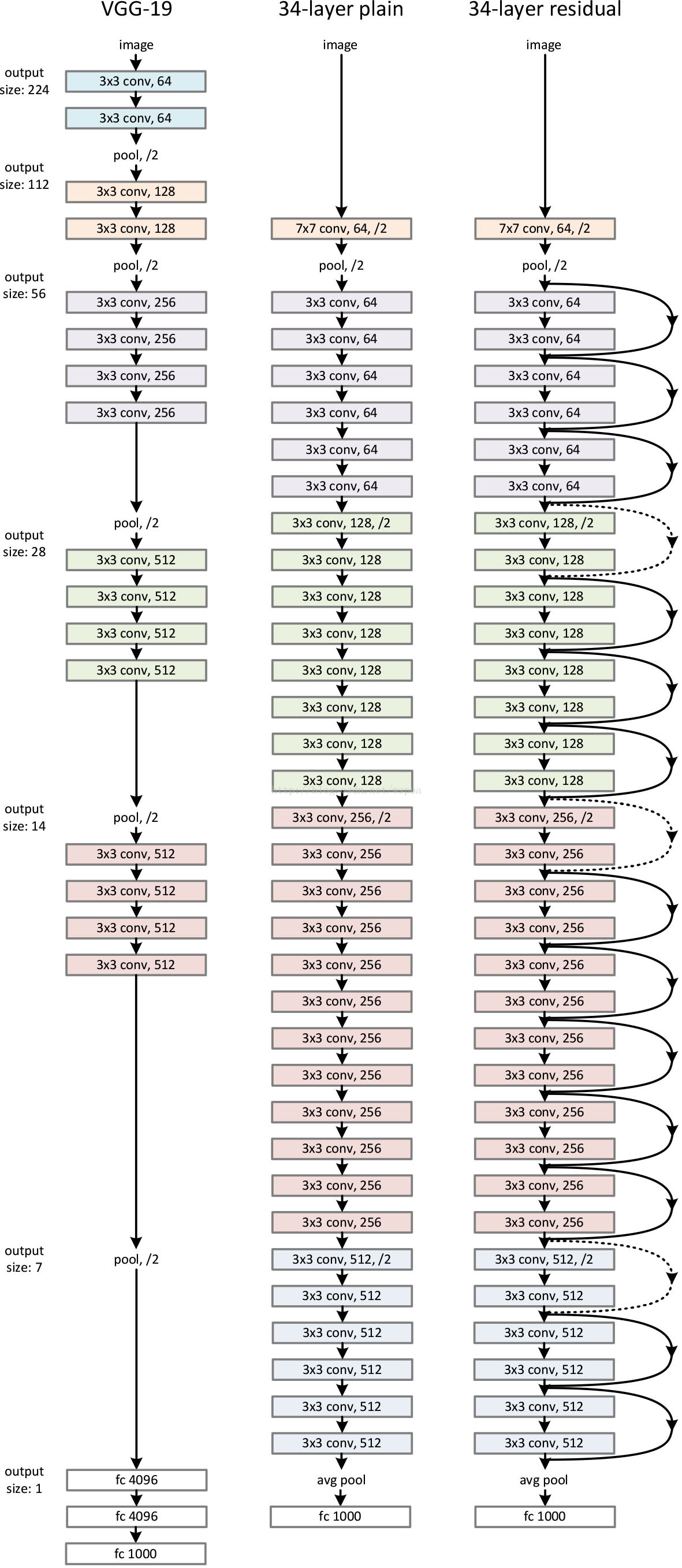

实验结果
图4中我们可看出,左侧是plain模型随着层数增加存在明显的退化显现,右侧是resnet模型有效的避免了退化问题并且resnet比plain收敛速度快。
进一步优化
为了减少实际运算的时间成本,作者将原来的残差学习结构改为瓶颈结构(bottleneck),如图5。通过在首尾使用1x1 conv来巧妙地缩减或扩张feature map维度,得我们的3x3 conv的filters数目不受外界即上一层输入的影响,自然它的输出也不会影响到下一层module。这两种结构的时间复杂度相似。此时投影法映射带来的参数成为不可忽略的部分(因为输入维度的增大),所以要使用zero padding的恒等映射。bottleneck替换原本ResNet的残差学习结构buliding block,网络深度得以增加。如表1中,生成了ResNet-50,ResNet-101,ResNet-152. 随着深度增加,因为解决了退化问题,性能不断提升。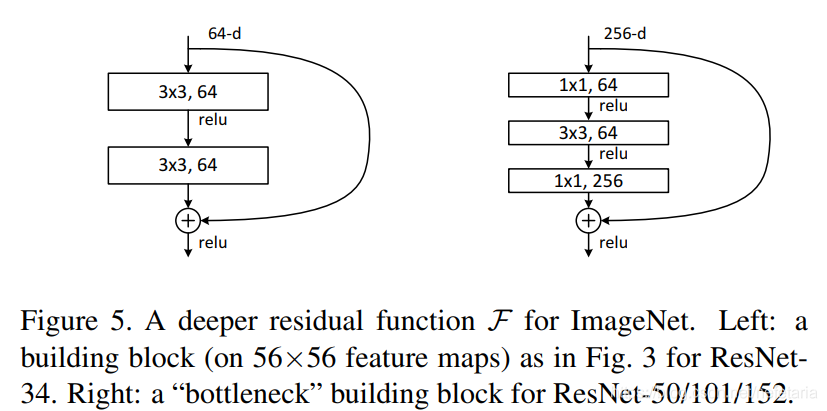
与先进方法对比
在表4中,我们与之前最好的单一模型结果进行了比较。我们的基础34层ResNet已经达到了非常有竞争力的精度。我们的152层ResNet的单一模型top-5验证误差为4.49%。这个单一模型的结果优于之前所有的集合结果(表5)。我们将6个不同深度的模型组合成一个整体(提交时只有两个152层模型)。这导致测试集的top-5错误率为3.57%(表5)。该参赛作品在2015年ILSVRC中获得了第一名。
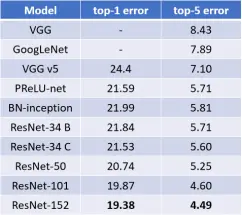
Table 4. Error rates (%) of single-model results on the ImageNet validation set (except † reported on the test set).
图4. ImageNet验证集上单个模型训练结果的错误率(%)(测试集上报告的†除外)
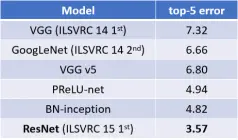
Table 5. Error rates (%) of ensembles. The top-5 error is on the test set of ImageNet and reported by the test server.
图5. 集合的错误率(%)。top-5错误率出现在ImageNet的测试集上,并由测试服务器报告。

若有收获,就点个赞吧
0 人点赞
