计算机视觉,自监督学习,预训练
简介
对比学习多用于计算机视觉领域,属于自监督学习,类似于NLP中的BERT/GPT做预训练模型。
自监督学习
自监督学习属于无监督学习范式的一种,特点是不需要人工标注的类别标签信息,直接利用数据本身作为监督信息,来学习样本数据的特征表达,并用于下游任务。
优势在于?
目前机器学习主流的方法大多是监督学习方法,这类方法依赖人工标注的标签,这会带来一些缺陷:
- 数据本身提供的信息远比稀疏的标签更加丰富,因此使用有监督学习方法训练模型需要大量的标签数据,并且得到的模型有时候是“脆弱”的。
- 有监督学习通过标签训练得到的模型往往只能学到一些任务特定的知识,而不能学习到一种通用的知识,因此有监督学习学到的特征表示难以迁移到其他任务。
而自监督学习能够很好地避免上面的问题,因为自监督学习直接使用数据本身来提供监督信息来指导学习。
自监督学习分类
自监督学习主要分为两类,生成学习与对比学习。
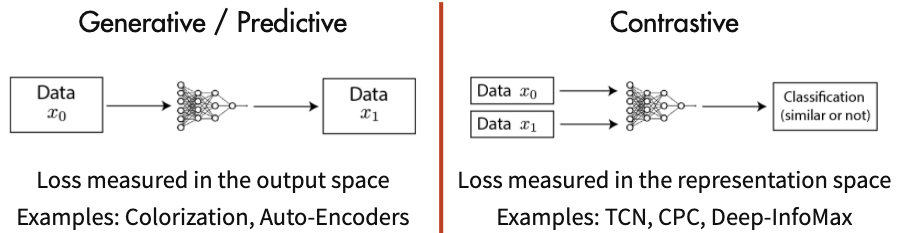
生成学习
生成学习主要有生成式对抗神经网络(GAN)与自编码器(AE)。
GAN通过生成器与判别器不断地对抗学习,生成器目的是让判别器无法判别输入是样本还是由生成器生成的,判别器目的则是区分输入是样本还是由生成器生成的。当二者达到均衡后,认为生成器已经学习到了样本的特征。
AE是一个输入和学习目标相同的神经网络:
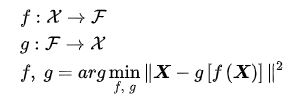
由于生成学习的损失是在输出空间中计算的,因此生成式学习比较关注像素级别的细节。
对比学习
对比学习是通过将数据分别与正例样本和负例样本在特征空间进行对比,来学习样本的特征表示。在特征空间区分正样本与负样本,及在特征空间,让正样本互相靠近,且正负样本相距尽可能的远。
对比学习的优势
相比于生成学习,对比学习只需要关注特征空间的区分性,而不需要过分关注像素细节。
Epstein在2016年做了一个实验:让受试者画出美元的图像,越详细越好,下图是受试者画出来的美元图像。
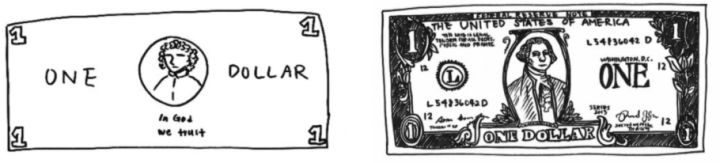
左图是受试者根据印象画出来的美元,右图则是让受试者照着美元画出来的。可以看到,左图画出来的美元图虽然不够详细,但已经充分具备一张美元的判别性信息,因此我们可以把它识别成美元。事实上,我们并不需要见到一张美元所有详细的信息,而仅仅通过一些关键的特征就可以识别出来。
因此,相比生成学习,对比学习不拘泥于像素细节,而是能够更好的理解抽象的语义信息。并且相对于生成学习更好优化。
方法
A Survey of Contrastive Self-Supervised Learning
核心思想:正样本距离拉近,正负样本间距离拉远。
方式:对一个正样本以及N个负样本进行学习,N越大越好。
优化问题:对一个正样本和N个负样本进行分类,交叉熵损失。
前置任务:图片增强处理(正样本)
大多数前置任务分为以下四类:
- 颜色变换
- 几何变换
- 基于上下文的任务
- 基于交叉模式的任务
具体取决于想干什么。
颜色变换

原图以及做了颜色处理的都是正样本。
几何变换

正样本包括:原图及其裁剪、旋转、翻转等。
基于上下文的任务

用于解决拼图问题,原图及其打乱后的图片为正样本。
基于交叉模式的任务

例,视图预测:anchor和它的正样本图片来自同时发生的视角下,它们在嵌入空间中应当尽可能地近,与来自时间线中其他位置的负样本图片尽可能地远。
架构
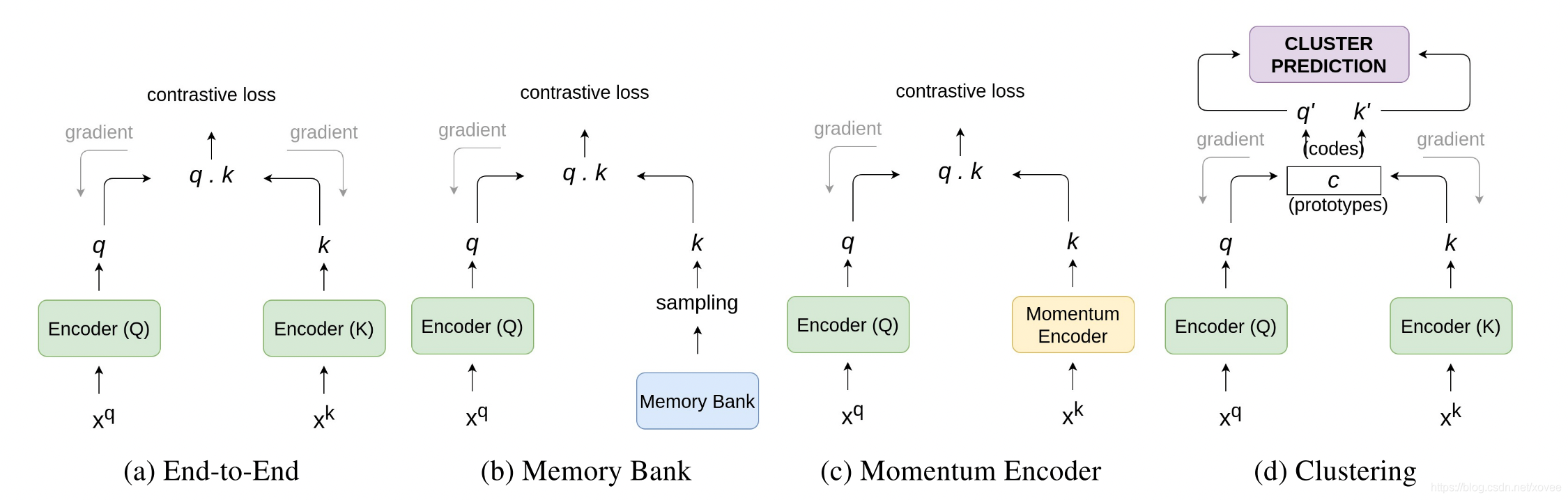
Encoder用于提取输入样本的特征,通常是ResNet。
x_q:代表某一图片(定义为P_q)的图像增强操作(旋转、平移、剪切等)后的一个矩阵;
x_k:代表多张图片(定义为P_K, 其中P_K包含P_q)的图像增强操作后的多个矩阵的矩阵集;
端到端
EncoderQ计算原图,EncoderK计算正负样本,计算contrastive loss并把误差传递回Encoder更新参数。输入一个batch之后,负样本的数量依赖batch size,batch size依赖GPU/TPU(Tensorflow里的张量处理器),大batch反向传播比较难搞。
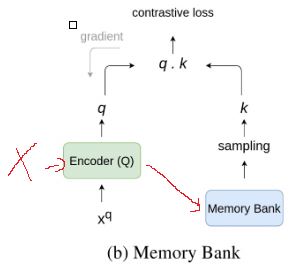
Memory Bank
解决负样本数量的问题。搞了一个Memory Bank存储特征,保存了所有图像x_k的特征k;针对每一张图像x_q在多轮训练时,每一轮训练,EncoderQ都会生成一次特征,从而更新Memory Bank中对应的k。比较时直接从Memory Bank中提取若干个k,由于k这边不需要反向传播所以k可以比较大。
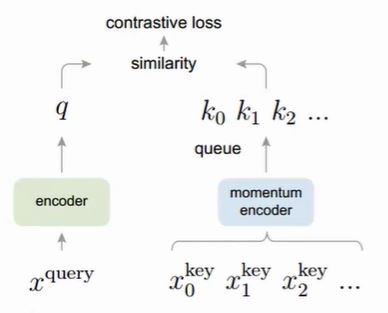
Momentum Encoder
对于Memory bank,随着训练过程的不断进行,EncoderQ的参数在不断更新,这导致Memory bank中的负样本特征差别过大,有的是刚更新的,有的是用很久以前的参数生成的特征,不利于对比学习。Momentum Encoder与Encoder结构相同,参数不同,通过引入了一个动量项让Memory bank中特征差异变小。
另外Momentum Encoder采用队列形式代替Memory Bank的字典形式,太久不更新的特征会被踢掉,例如一开始队列中k0,k1….k5000,通过Momentum Encoder添加k5001的时候,k0会被挤掉。
Clustering Feature Representations
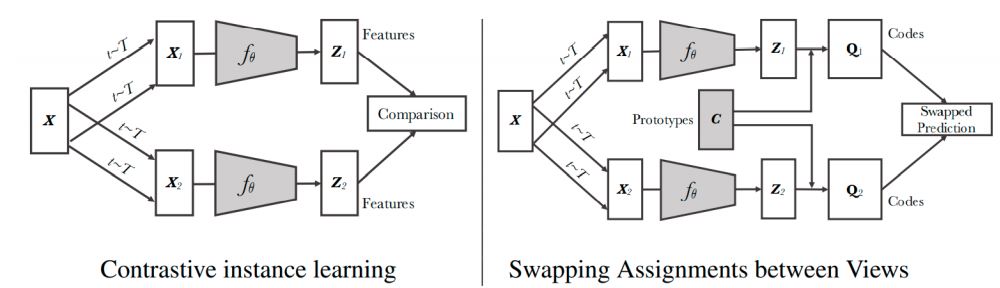
传统对比学习让正负样本距离拉远,并且在传统对比学习中(基于实例的对比学习,instance-based contrastive approach),每个样本被认为是一类,这一会导致本属于一类的样本被拉远,举例来说就是正样本是猫,负样本batch中也有猫的图,但二者距离依旧会被拉远。
图片来自Unsupervised learning of visual features by contrasting cluster assignments,一个图(x)的两个增强样本(x1,x2)对应的特征(z1,z2)分别与Prototypes集c匹配得到(Q1,Q2),loss计算如下:
L(z1,z2)=l(z1,q2)+l(z2,q1)
思想是如果z1,z2两个特征捕捉到相同的信息,那么其中一个特征的code应该可以用另一个特征预测。
训练
两种渠道:

锚点距离正样本距离小,负样本距离大/锚点与正样本相似度大,负样本相似度小。
相似度方法
通常使用cosine相似度
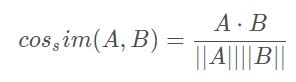
Noise Contrastive Estimation (NCE) 函数定义为:
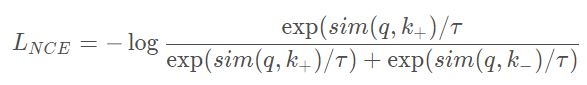
其中q是原样本,k+是正样本,k-是负样本,τ 是超参数,被称为温度系数。sim()可以是任何相似度函数,一般来说是cosine相似度。
通常,一个正样本对应多个负样本,NCE改写为InfoNCE:
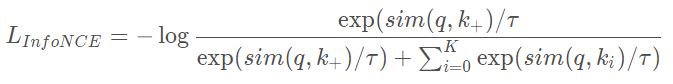
距离方法
特征空间中,锚点与正样本特征的欧几里得距离小,与负样本特征的欧几里得距离大。
假定正负样本与锚点均由一个弹簧连接,正样本的弹簧0势能点距离为0,负样本弹簧0势能点距离为m,让弹簧的弹性势能最小。
对于正样本,有

对于负样本,有
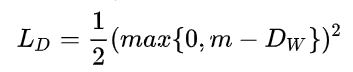
Dw为锚点与样本特征的欧氏距离,这个max函数在这里表示如果负样本距离锚点距离超过m也ok。
然后获得损失函数:

Y为0代表正样本,Y为1代表负样本,W是网络权重。
简化版方法,Triplet Loss:
三元组: 锚点,正样本,负样本
锚点,正样本,负样本
三元组总体距离可以表示为:
不需要正样本无限拉近于0,只需要正负样本距离大于α即可。
实际上,从距离出发与从相似度出发是互通的:

k=1的infoNCE,也就是NCE泰勒展开保留一阶项得到了Triplet Loss。
其他
下游任务
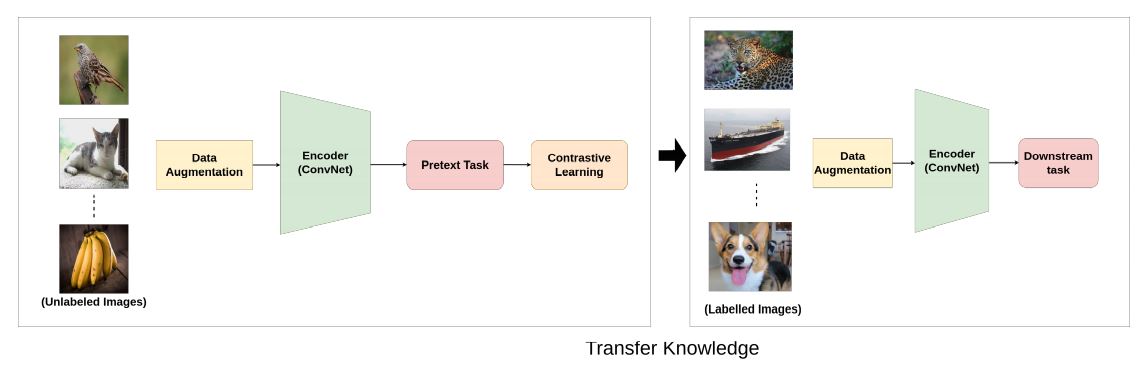
一般来说,计算机视觉的自监督训练包括两个任务:
- 前置任务
- 下游任务
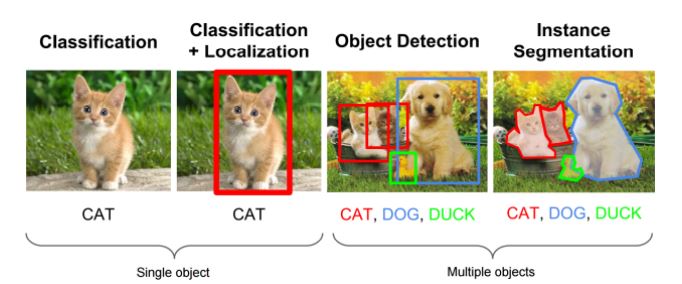
下游任务诸如分类,定位,实体探测,实体分割
前置任务+下游任务整体流程如下:
NLP中的对比学习应用
- infoXLM,cross-lingual pre-training
- Cert,language understanding
- DeCLUTR,textual representations learning
参考文献
[1912.01991] Self-Supervised Learning of Pretext-Invariant Representations (arxiv.org)
[2011.00362] A Survey on Contrastive Self-supervised Learning (arxiv.org)
CVPR2020-MoCo-无监督对比学习论文解读 - 知乎 (zhihu.com)
Self-Supervised Learning—PIRL(自监督学习—预任务不变表征学习) - 知乎 (zhihu.com)
对比学习(Contrastive Learning)综述 - 知乎 (zhihu.com)
MOCO(基于动量比对的非监督式视觉表征学习) - 知乎 (zhihu.com)
Unsupervised learning of visual features by contrasting cluster assignments

若有收获,就点个赞吧
0 人点赞
