图像识别,生成对抗网络,零次识别,开集识别
简介
文章基于**反事实生成框架**提出了一个GCM-CF二元分类器,用于**分类见过/未见过类别**,并将GCM-CF应用于零次识别(ZSL)与开集识别(OSR)中,取得了较好的效果。
GCM-CF分类器
过去未见类识别的问题
过去十年中,所有未见类识别方法都遵从一个假设:**训练中已见类的属性或特征可以被转移到测试的未见类中——即通过分解已见类中的属性或特征,以一定方式重组,可以构建出未见类。**但是这一假设在实践中几乎是无效的,因为模型再训练中只看到的类别,它将不可避免地迎合所看到的特异性,从而导致对看不见的世界的不切实际的想象。ZSL与OSR主要方法是基于生成,根据已见类生成的假想未见类**会自然的偏向见过的训练集,使得对于未见类别的想象**_**失真**_**了**,如下图所示。(文中**失真**例子:比如训练的时候见过大象的长鼻子,而去想象没见过的貘的长鼻子的时候,就会想象成大象的鼻子。)
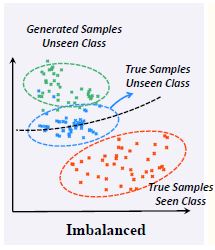
这种失真,导致见过和未见过类别的识别率的失衡:用绿色和红色样本学习的分类器(黑色虚线)牺牲了未见过类的recall来提高见过类的recall。
理论上,如果**每个属性都被分解**——即找到一组基向量,任何向量组合都是合理的,那么可以做到合理的见过/未见类识别,但这是不切实际的,因为不可能找到合适的监督。
反事实推理
简介:
反事实(counterfactual)是**对已有结果进行假设**,再推理,估计其中一项影响因素的发生概率。这是一个心理学中的概念,近年来在机器学习中广泛应用,指代与因果分析相关的广泛性技术。举一个典型的例子来描述反事实推理:_已知 Alice 在工作中没有得到晋升,已知她是一名女性,已知我们可以观察到的关于她的情况和表现的一切事情,那么,如果 Alice 是男性,她的晋升概率又会如何?_
在这个例子里,Alice是女性为既定的实事,那么问如果Alice是男性会如何,便是反事实推理。
这篇文章利用反事实推理,绕过全特征/属性分解。
方法的原理:
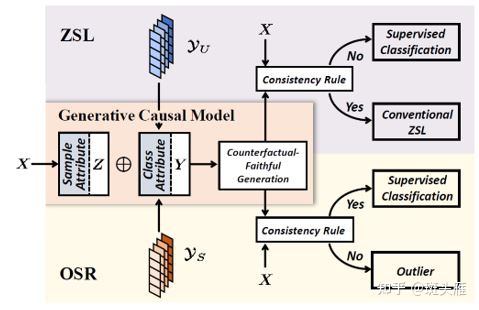
GCM-CF与先前的未见类识别方法一样是**基于生成模型**,通过结合**需要判断的样本的特征**与**已见类/未见类的类别特征**来生成假想图,通过对比假想图与待判断样本来完成已见类/未见类的分类。

下面结合示意图,介绍GCM-CF流程。
目的:
想判断样本x(事实,图中的狗)是已见类还是未见类。
步骤:
- 首先从样本x中提取一组与类别无关的特征Z=z(x)
例:Z=z(x)为图中所示的pose特征,走路,幼崽,正面图(这个特征只与图片中动物的pose有关,而与图片中动物的类别无关。这很重要,关系到生成图片的保真。) - 以ZSL为例,在ZSL中,有关于未见类的特征以及其特征的描述,可以简要写为已有未见类(反事实)的类别特征Y
例:Y为图中所示的类别特征,猫,羊,鸡 - 反事实推理,提问,如果样本x属于未见类,那么根据样本x的pose特征Z=z(x)与未见类类别特征Y,生成一组假想图X,会如何?
即,使用样本特征Z=z(x)与未见类类别特征Y生成了一组未见类假想图X - 显然,如果样本x属于未见类,那么在X中将有
 =x,反之则没有。
=x,反之则没有。
即,对比生成的假想图X与样本x来判断样本x是属于已见类还是未见类。
如果以OSR为例,由于**OSR没有未见类的标签**,所以**使用**_**已见类**_**的特征作为反事实特征Y**,结合输入样本x的特征Z=z(x)生成一组已见类图片,与样本x对比,判断样本x是否属于已见类,本质上原理没有区别,流程可以写为:
- 从样本x中提取一组与类别无关的特征Z=z(x)
- 获得已见类的类别特征Y
- 根据Z与Y,生成已见类的假想图X
- 对比样本x与假想图X,判断样本x属于已见类还是未见类
核心:
方法的核心在于生成样本的**保真**,用样本自己的  ,拼上不同的类别特征  ,然后用  生成  。这样生成的样本可以证明是"保真"(Counterfactual Faithful)的,也就是在样本空间里面,那么我们就能够用样本空间当中的量度去比较  和生成的  ,从而用consistency rule判断  是属于见过的还是没见过的类。
按文中所述,保真生成的充要条件是样本特征和类别特征之间解耦(disentangle),为此,文中添加了三个loss来实现:
 -VAE loss:这个loss要求encode得到的
-VAE loss:这个loss要求encode得到的  ,和样本自己的
,和样本自己的  ,可以重构样本
,可以重构样本  ,并且encode出来的
,并且encode出来的  要非常符合isotropic Gaussian分布。这样通过使 的分布和
要非常符合isotropic Gaussian分布。这样通过使 的分布和  无关实现解耦;
无关实现解耦;- Contrastive loss:反事实生成的样本中,
 只和自己类别特征生成的样本像,和其他类别特征生成的样本都远。这个避免了生成模型只用 里面的信息进行生成而忽略了 ,从而进一步的把 的信息从 里解耦;
只和自己类别特征生成的样本像,和其他类别特征生成的样本都远。这个避免了生成模型只用 里面的信息进行生成而忽略了 ,从而进一步的把 的信息从 里解耦; - GAN loss:这个loss直接要求反事实生成的样本被discriminator认为是真实的,通过充要条件,用保真来进一步解耦。
1,2通过使Z与Y不相关来达到保真,3从生成对抗网络的loss出发,直接使生成的样本保真。
与先前方法主要异同:
首先,均为基于生成的方法。
先前方法通过对已有样本的特征进行全特征分解,用这些特征或特征的组合Y,与一些随机噪声Z来生成,并对比。
GCM-CF则利用输入样本中与类别无关的特征Z+已有样本中的类别特征Y来生成,并对比。
举例来说,先前方法将已有的猫,羊,鸡样本分解为毛色,瞳色,瞳距,身高,体重等互相解耦的特征,然后用这些特征加上噪声生成假象未见类;而GCM-CF则用已有样本的“猫,羊,鸡”这种类别特征,但类别特征不一定互相解耦,例如猫与羊都是哺乳动物,类别特征加上与类别特征解耦的输入样本特征,生成假象未见类。即,输入样本特征间不一定互相解耦,已有样本的类别特征也不需要互相解耦,但输入样本的特征与已有的类别特征互相解耦。
GCM-CF作为已见类/未见类的二元分类器的优势在于其生成的假想图更加保真,从而判断更为准确。
具体任务中:
ZSL
在ZSL里面,使用未见过类别的attribute(图中  )生成反事实样本,然后用训练集的样本(见过的类)和生成的样本(未见过的类)训练一个线性分类器,对输入样本  进行分类。
若属于见过的类,使用在见过类的样本上面监督学习的分类器来分类;反之,就标注为未见过的类,然后用任何Conventional ZSL的算法对其分类。
OSR
在OSR里面,因为没有未见类别的信息,用见过类的one-hot label(图中  )作为  生成反事实样本,如果  和生成的样本在欧式距离下都很远,就认为  属于未见过的类,并标为“未知”,反之则用监督学习的分类器即可。
零次学习与开集识别
零次学习ZSL
ZSL希望模型能够对其从**没见过的类别进行分类**,让机器具有推理能力,实现真正的智能。其中**零次(Zero-shot)是指对于要分类的类别对象,一次也不学习**。
以识别斑马为例,ZSL需要
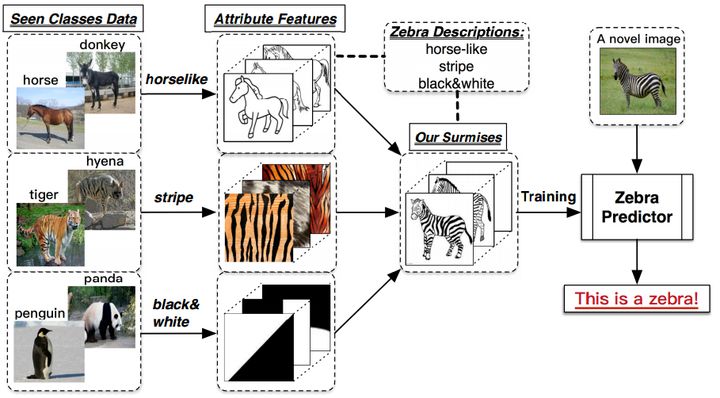
- 训练集数据
 及其标签
及其标签  ,包含了模型需要学习的类别(马、老虎和熊猫),这里和传统的监督学习中的定义一致——从训练集中学习特征,例:horselike,stripe,black&white;
,包含了模型需要学习的类别(马、老虎和熊猫),这里和传统的监督学习中的定义一致——从训练集中学习特征,例:horselike,stripe,black&white; - 测试集数据
 及其标签
及其标签  ,包含了模型需要辨识的类别(斑马),这里和传统的监督学习中也定义一致——需要告诉模型斑马叫斑马;
,包含了模型需要辨识的类别(斑马),这里和传统的监督学习中也定义一致——需要告诉模型斑马叫斑马; - 训练集类别的描述
 ,以及测试集类别的描述
,以及测试集类别的描述  ;我们将每一个类别
;我们将每一个类别  ,都表示成一个语义向量
,都表示成一个语义向量  的形式,而这个语义向量的每一个维度都表示一种高级的属性,比如”黑白色”、“有尾巴”、“有羽毛”等等,当这个类别包含这种属性时,那在其维度上被设置为非零值。对于一个数据集来说,语义向量的维度是固定的,它包含了能够较充分描述数据集中类别的属性。——需要告诉模型斑马的特征描述,即斑马=马身+条纹+黑白色,然后模型可以通过已经学习到的特征(马身,条纹,黑白色)来识别从未见过的斑马。
的形式,而这个语义向量的每一个维度都表示一种高级的属性,比如”黑白色”、“有尾巴”、“有羽毛”等等,当这个类别包含这种属性时,那在其维度上被设置为非零值。对于一个数据集来说,语义向量的维度是固定的,它包含了能够较充分描述数据集中类别的属性。——需要告诉模型斑马的特征描述,即斑马=马身+条纹+黑白色,然后模型可以通过已经学习到的特征(马身,条纹,黑白色)来识别从未见过的斑马。
在ZSL中,我们希望利用 和 来训练模型,而模型能够具有识别 的能力,因此模型需要知道所有类别的描述 和 。
总结来说,ZSL通过已有信息学习特征,当给出需要识别的未见类的特征描述后,即便模型从未见过该类别,也可以对该类别进行识别。
开集识别OSR
闭集分类问题(closed-set problem),即测试和训练的每个类别都有具体的标签,不包含未知的类别(unknown category or unseen category)。
如著名的MNIST和ImageNet数据集,里面包含的每个类别为确定的。以MNIST(字符分类)为例,里面包含了0~9的数字类别,测试时也是0~9的类别,并不包含如字母A~Z等的未知类别,闭集分类问题即:区分这10个类别
开集分类问题(open-set problem),不仅仅包含0~9的数字类别,还包含其他如A~Z等等的未知类别,但是这些未知的类别并没有标签,分类器无法知道这些未知类别里面图像的具体类别,如:是否是A。这些许许多多的不同类别图像共同构成了一个类别:未知类别,在检测里面我们叫做背景类别(background),而开集分类问题即:区分这10个类别且拒绝其他未知类别。
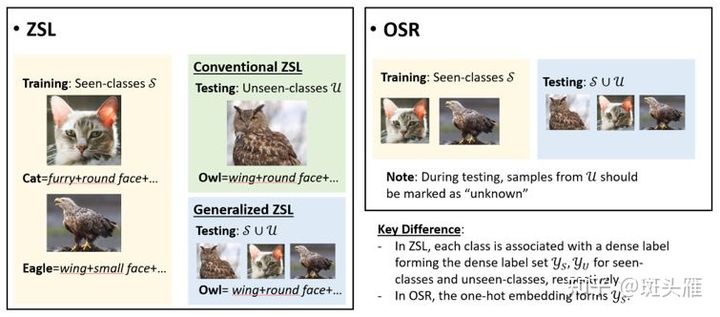
ZSL与OSR的差异:
- 未见类标签有无
- 最终目的不同:识别未见类与拒绝未知类别
小结
这篇文章介绍的工作通过在零次识别与开机识别中引入GCM-CF分类器,降低了**见过和未见过类别识别率的失衡**。其核心思想是**通过解耦表示**disentangled representation,把难以实现的所有**factor full disentangle**(先前方法),放宽成为两组概念(样本特征和类别特征)之间的**group disentangle**。
参考文献
因果推理初探(7)——反事实(上) - 知乎 (zhihu.com)
(转)零次学习(Zero-Shot Learning)入门_一路向北-CSDN博客
真实世界中的开集识别问题(Open-Set Recognition Problem)u010165147的博客-CSDN博客开集识别
[2103.00887] Counterfactual Zero-Shot and Open-Set Visual Recognition (arxiv.org)

若有收获,就点个赞吧
0 人点赞
