人工通用智能;神经网络;机器学习 ;深度学习 ;强化学习 ;元学习 ;度量学习;终身学习 ;快速学习 ;迁移学习;灾难遗忘
AGI
什么是AGI
能够达到以下水平的人工智能,即称之为人工通用智能AGI(Artifical General Intelligence):
- 存在不确定性因素时进行推理,使用策略,解决问题,制定决策的能力;
- 知识表示的能力,包括常识性知识的表示能力;
- 规划能力;
- 学习能力;
- 使用自然语言进行交流沟通的能力;
- 将上述能力整合起来实现既定目标的能力。
为什么AGI?
人类社会自动化,创造更高的价值。
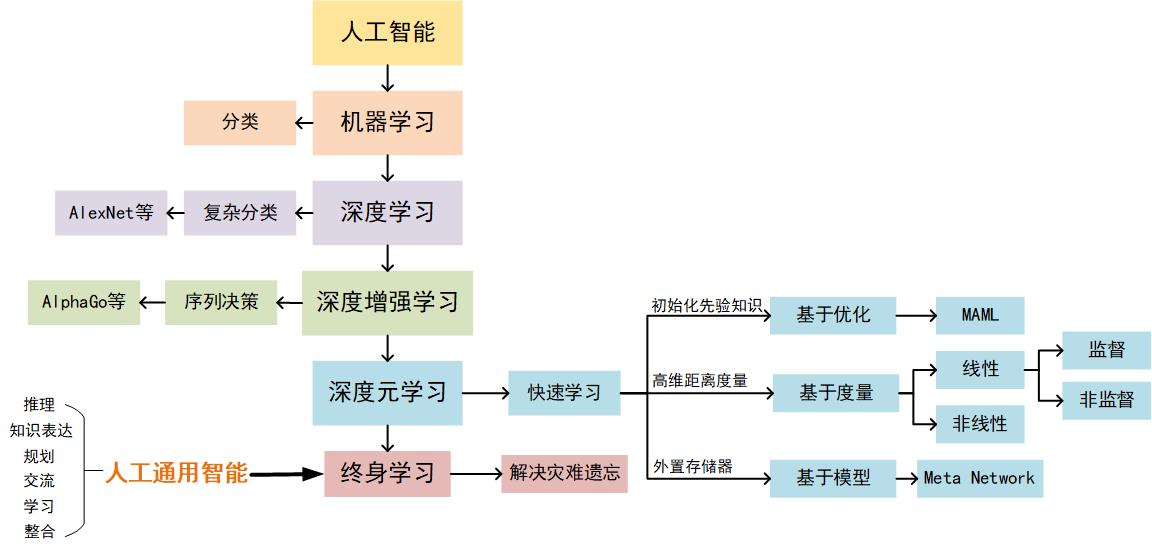
AGI发展历程
AGI作为人工智能领域一个中长期目标,发展路线:首先要解决感知和决策,再谈学习和泛化。AGI的发展脉络可以简单地用下图来说明,即遵循的步骤是:
深度学习解决分类,检测,识别问题,即目标特征到语义属性的离散映射关系,即感知。有了感知,机器就可以熟悉认识其周围的环境;
深度强化学习解决序列决策问题,即环境状态到智能体行为动作的连续耦合映射关系,即决策。其利用状态转移概率可知的马尔可夫过程对最大化奖励的行为策略求解或者对状态转移概率不可知的值函数最大化的行为/策略进行估计,其本质上是属于动态规划问题,从而解决智能体连续决策问题。有了决策,机器智能体就可以基于目标最大化与环境进行交互;
深度元学习解决快速学习泛化问题,即智能体行为动作间的逻辑映射关系,即学习推理。有了学习推理,机器智能体就能够构建自己的知识体系,从而形成经验以适应环境进而生存。

AGI核心:元学习
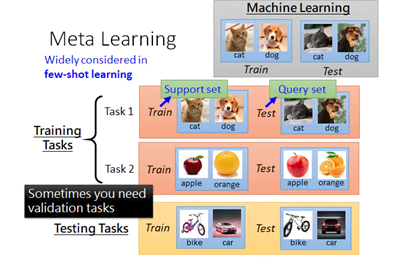
一个好的机器学习模型通常需要训练大量的样本。相比之下,人类可以更快,更有效地学习新的概念和技能。只看过几次猫和鸟的孩子可以迅速分辨它们。懂得如何骑自行车的人可能会发现很少甚至根本没有示范的快速骑摩托车的方法。是否可以设计一个具有类似特性的机器学习模型(通过一些培训示例快速学习新概念和技能)实质上就是元学习旨在解决的问题。
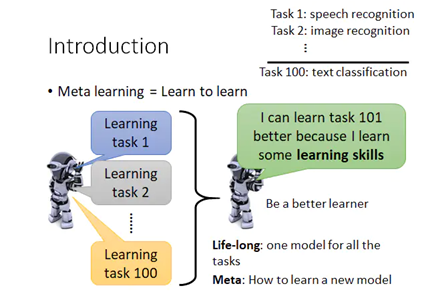
终身学习(Life-long Learning):学习一系列任务时试图解决神经网络中灾难遗忘的问题。
元学习(Meta Learning):用很多tasks做为训练数据来训练一个meta-model,这个meta-model然后可以用于学新的task,这个新任务不需要太多的数据,学的速度上也会更快。
我们期望一个好的元学习模型能够很好地适应或推广训练期间从未遇到过的新任务和新环境。适应过程本质上是一个在测试期间进行的小型学习会话,在对新任务配置的有限接触下,使调整后的模型可以完成新任务。
元学习可以分为:
- model based
- matric based
- optimization based
Optimization based
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks:(ICML,2017)
MAML学习一个好的初始化权重,从而在新任务上实现fast adaptation,即在小规模的训练样本上迅速收敛并完成fine-tune(精调),由few-shot learning演化而来。
model-agnostic即模型无关。MAML与其说是一个深度学习模型,倒不如说是一个框架,提供一个meta-learner用于训练base-learner。这里的meta-learner即MAML的精髓所在,用于learning to learn;而base-learner则是在目标数据集上被训练,并实际用于预测任务的真正的数学模型。绝大多数深度学习模型都可以作为base-learner无缝嵌入MAML中,而MAML甚至可以用于强化学习中,这就是MAML中model-agnostic的含义。
实验设置:我们需要利用MAML训练一个数学模型,目的是对未知标签的图片做分类,类别包括
$ P_1\sim P_5 $(每类5个已标注样本用于训练(support set)。另外每类有15个已标注样本用于测试(query set)用于训练)。
$ C1\sim C{10} $(每类30个已标注样本)另外10个类别的图片,用于帮助训练元学习模型。
实验设置为5-way 5-shot(训练数据1个Task中有5个类别,每个类别有5个被标记数据用于训练)。
可以得出,$ C1\sim C{10} $中每个task有5个类别,每个类别有5个被标注样本(support set),假设有15个已标注样本用于测试(query set)。
目标:学习$ C1\sim C{10} $的分类问题后,通过少量$ P_1\sim P_5 $的学习掌握分类$ P_1\sim P_5 $的能力、
算法:gradient by gradient(两次梯度更新):为了提高模型的泛化能力。

以上算法针对$ C1\sim C{10} $,对于$ P_1\sim P_5 $中的query set无需gradient by gradient,只需训练support set进行fine-tune。

Matric based
度量学习 (Metric Learning) == 距离度量学习 (Distance Metric Learning,DML) == 相似度学习
比如我们要做一个门禁系统,每增加或减少一个员工(等于是一个新类别),就要修改识别网络并重新训练。很明显,这种做法在某些实际运用中很不科学。目前,Metric Learning已被广泛运用于人脸识别的日常运用中。
因此,Metric Learning作为经典识别网络的替代方案,可以很好地适应某些特定的图像识别场景。一种较好的做法,是丢弃经典神经网络最后的softmax层,改成直接输出一根feature vector,去特征库里面按照Metric Learning寻找最近邻的类别作为匹配项。
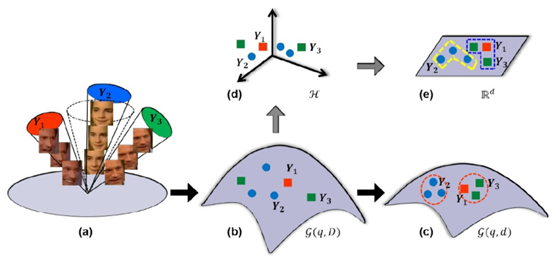
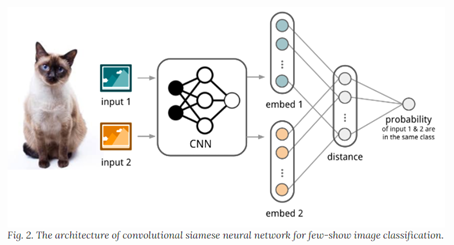
度量学习的线性模型:
- 监督的全局度量学习:该类型的算法充分利用数据的标签信息。如
Information-theoretic metric learning(ITML)
Mahalanobis Metric Learning for Clustering
Maximally Collapsing Metric Learning (MCML)
- 监督的局部度量学习:该类型的算法同时考虑数据的标签信息和数据点之间的几何关系。如
Neighbourhood Components Analysis (NCA)
Large-Margin Nearest Neighbors (LMNN)
Relevant Component Analysis(RCA)
Local Linear Discriminative Analysis(Local LDA)
- 非监督的马氏度量学习。如
主成分分析(Pricipal Components Analysis, PCA)
多维尺度变换(Multi-dimensional Scaling, MDS)
非负矩阵分解(Non-negative Matrix Factorization,NMF)
独立成分分析(Independent components analysis, ICA)
邻域保持嵌入(Neighborhood Preserving Embedding,NPE)
局部保留投影(Locality Preserving Projections. LPP)
度量学习的非线性模型:等距映射(Isometric Mapping,ISOMAP) 、局部线性嵌入(Locally Linear Embedding, LLE) ,以及拉普拉斯特征映射。
Model based
Meta Network(ICML,2017)
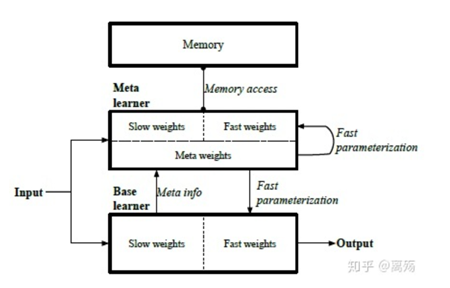
Meta Network**是一种元数据学习模型,具有用于跨任务快速概括的体系结构和培训过程。模型的跨任务快速概括**依赖于fast weight。神经网络中的参数通常是根据目标函数中的梯度下降来更新的,这个过程对于小样本学习是很慢的。一种更快的学习方法是利用一个神经网络预测另一个神经网络的参数,生成的参数称为快权值即fast weight。普通的基于SGD等优化的参数被称为慢权值即slow weight。
本算法能够实现连续学习,在Omniglot数据集上训练得到的网络,可以进一步在MNIST数据集上继续训练,在学习MNIST数据集的同时,并不会产生严重的“遗忘灾难”(即忘记Omniglot数据集上的信息)。另一方面作者指出该算法可以应用于强化学习,模仿学习,或者基于RNN用于序列模型和自然语言理解等任务。
AGI未来展望
- Hierarchy Model: 可以针对神经网络在网络结构层面进行改进,神经网络的分层不仅仅是在时间尺度上,按照逻辑我们人类做的任何决策都是一种hierarchy,从本质结构上,人脑和神经网络有很大的相似之处。
- Modulear Neural Networks: 可以在网络结构层面进行改进,神经网络模块化一定是一种趋势,因为我们未来将会看到一个神经网络能够同时处理视觉、语音、控制等等各种输入输出,没有模块化是办不到的,这类似于人类大脑不同区域的不同功能,但是里面有很多信息可以共用和迁移。
- 广义RL:带反馈的广义强化学习。广义RL的形式反映了人类如何获取信息并转化为知识和技能的过程,最后形成一种经验常识被固化保留下来,从而能够作为一种高级语义信息被传播和重复利用,这是高级智慧的体现。广义RL为机器智能体学习提供了一套通用的框架。
- Transfer Learning:随着人工智能的大规模部署和应用,在实际场景中网络训练的时耗以及网络模块的迁移重用将会是应用过程中的重要部分,而且工作量繁重。所以,必须让网络模块具备自适应迁移的功能,能够在近似的场景中进行快速部署和应用,这就意味着需要让网络稍加修改和微调训练就能够使用,即迁移学习。
所谓的通用人工智能就是要让人工智能能够只用同一套算法学习掌握各种各样的任务,而不是单一任务从头训练。因此,通用人工智能必须具备快速学习能力,快速学习能够让每个人拥有的人工智能系统都不一样。不难看出,快速学习是实现通用人工智能AGI的必由之路,而元学习(Meta Learning)又是实现快速学习的重要方法之一。
参考文献:
Finn C , Abbeel P , Levine S . Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks[J]. 2017.
https://zhuanlan.zhihu.com/p/85804572
https://arxiv.org/pdf/1703.00837.pdf
https://blog.csdn.net/langb2014/article/details/84953307
内卷
前情回顾
狼抓羊,狼抓到羊+10,狼撞到障碍物-1,每秒狼-0.1,5w轮训练后狼选择自杀。
训练分析
- 原地站着15秒得-1.5分;
- 一头扎死得-1.1分;
- 尝试绕路但是撞死得-1.1 到-2.4分。
- 所以由于狼根本没有吃到过羊,因此狼在-1.1到-2.4分之间选择了-1.1,也就是自杀。
段子
- 连人工智能都知道拒绝内卷的。
- 狼就是打工人…每秒扣的是青春和时间,羊永远达不到的“升职、加薪、迎娶白富美、走上人生巅峰”。
- 面对不合理的KPI和奖惩机制,连ai展现出了令人类叹为观止的尊严。
- 为了激励狼快点抓羊而倒扣分是错误的,相反,应该激励狼活下去而每秒加0.1分。想要最高分当然会尽量抓羊,抓不到羊还撞障碍物扣分已经很劝退了,只有加分才能激励狼活下去。太现实了,只有活着本身就是一种奖励,人才愿意活下去。要不然真的不如一头撞死。
- 请给狼加一个参数:生命成本。这个参数的定义是我活这么大不容易随便死了太不值了。每次抓不到羊挫败-0.1,但每多活一天就累积+1,降到0才执行自杀,你就收获了一群要死不死的社畜狼了。
内卷、囚徒效应
关于内卷:
很久很久以前,地球上有一个小镇。小镇上有很多鞋店,这些鞋店每天上午10点开门,中午12点到下午2点午休,下午2点到晚上6点继续营业;每周一至周五营业5天,周末休息。
夏天最热的那几天,鞋店老板们会纷纷把店关掉,去南方的海边度假;冬天最冷的那几天,鞋店老板们也会纷纷把店关掉,去北方的山里滑雪。
多年以来,小镇上的常住人口没有什么变化,鞋的品质一直优秀,供货也稳定,所以,小镇上的鞋的供需关系一直处于一个近乎完美的平衡状态。
后来有一天,一户人家出于不明原因从大城市搬来小镇上,并且也开了一家鞋店。小镇虽然小,但也算具有一定规模,鞋的供需平衡还不至于因为新增一家鞋店而被打破。
但是,那座大城市的人民以勤奋、能吃苦著称。果然,这户来自大城市的人家也具备这些特点。他们家的鞋店每天早晨7点就开门了,中午也不午休,晚上直到11点才关门;周末他们也正常营业,夏天和冬天他们也从不去度假。
渐渐地,他们的“勤奋”得到了回报,他们鞋店的生意明显好于小镇上的其他鞋店。以前小镇人民吃完晚饭后是无法买鞋的,但现在,他们几乎随时可以去大城市人的鞋店买鞋,也就没什么必要光顾其他鞋店了。
但小镇老板们也不服输,他们纷纷效仿大城市人民的作息时间,每周工作7天,每天工作16小时。他们的“勤奋”也得到了“回报”:他们的营业收入恢复到了以前的状态。
那么,此时的小镇生活发生了什么样的变化呢?由于小镇人口并没有增加,鞋的需求量保持恒定,跟以前一样,所以每家鞋店最终的营业收入没什么变化,并不会增长。但营业时间从原来的每周5天,每天6小时变成了每周7天,每天16小时。
也就是说,他们的工作时间变长了,但收入却没有增加。
这就是传说中的内卷(involution)。同时,这也是传说中的囚徒困境。
关于囚徒困境:
我们可以把鞋店简化为两家:大城市鞋店和小镇鞋店。他们工作模式也可简化为996和955。小镇上鞋的需求不变。根据以上条件可知:
如果两家鞋店都选择955,会平分市场需求,同时也保证了休息时间,这种情况下总体收益最高,假设两家的收益分别是5, 5。
如果两家鞋店都采取996工作模式,最终仍然会平分市场,但由于休息时间减少,幸福感降低,收益不能再是5, 5而应该是3, 3。
而如果一家店选择了996而另一家店选择了955,那么996鞋店最终可能会独占市场,而955鞋店会没生意,于是两家的收益可假设为8, 0。
这场博弈中两位鞋店的赢利表如下:
两位鞋店老板彼此不知道对方是怎么想的,但他们都是“聪明”人,很容易算出:如果对方996,那么我955的收益是0,我也996的收益是3,所以我应该996;如果对方955,那么我也955的收益是5,我996的收益8,所以我应该996。
最终,两家鞋店都选择了996,这场博弈达到纳什均衡,两位老板都成了996的“囚徒”。
纳什均衡是这样一种状态,在该状态下每个参与人所采取的策略都是对于其他参与人的策略的最优反应。
几点思考:
1、 大家共同不努力平分稳定的“蛋糕”
2、 小镇来了一个新鞋匠,周末也加班做最好的手工羊皮鞋,最后联合小镇的几大制鞋家族成为世界最有名的鞋业小镇,改变了一生及后代。
3、 小镇来了新企业,使用电商取代线下零售,成为垄断力量,其他企业一蹶不振。(反全球化)
内卷,本意是指人类社会在一个发展阶段达到某种确定的形式后,停滞不前或无法转化为另一种高级模式的现象。当社会资源无法满足所有人的需求时,人们通过竞争来获取更多资源。内卷的最大矛盾其实是“面对不确定性的价值创造的担忧”,当创造价值不变而消耗更多资源时,发生内卷。

若有收获,就点个赞吧
0 人点赞
