作者:牛力
编辑:刘梓琰
编者按:这篇文章是一篇工作回顾,介绍了弱样本学习的定义,总结了解决弱样本学习问题的思路,调研了弱样本学习的相关工作进展,并对该领域空白的工作做了补充。
综述
跨种类迁移
深度学习模型的训练需要大量标注良好的训练样本,但是这种训练样本的获取成本非常高昂。现实世界中种类繁多,新种类也在源源不断地出现,因此不可能为所有种类收集大量标注良好的训练样本。尽管目前有很多高质量的标注数据库,但它们只包含有限个基础种类,如何从基础种类拓展到新种类成为很多热门领域的研究内容。比如零样本学习(zero-shot learning)和少样本学习(few-shot learning)把所有种类划分成没有交集的基础种类(base categories)和新种类(novel categories)。基础种类有大量标注良好的训练样本,新种类没有训练样本或者只有少量训练样本。弱样本学习(weak-shot learning)和零样本学习、少样本学习类似,也把所有种类划分成基础种类和新种类。不同的是,基础种类有大量强标注的训练样本,而新种类有大量弱标注的训练样本。 考虑到数据标注的”质量”包含”质”(quality)和”量”(quantity)两个方面,少样本学习和弱样本学习可以看成姊妹学习范式。少样本学习侧重于降低对新种类训练数据量的要求,而弱样本学习侧重于降低对新种类训练数据质的要求。零样本学习、少样本学习和弱样本学习的比较如图1所示:
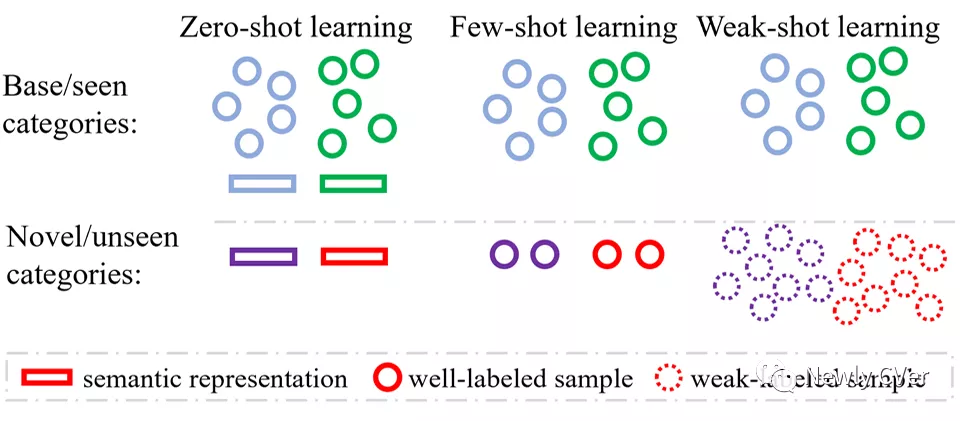
弱样本学习任务
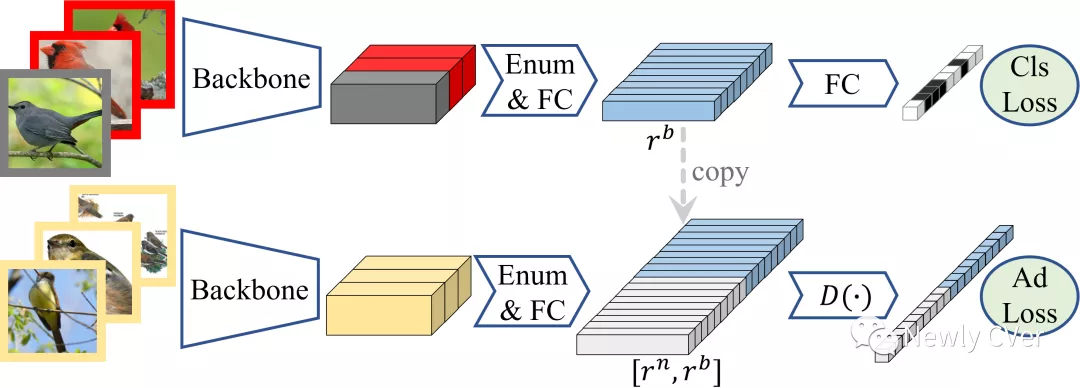
弱标注(weak annotation)的定义取决于不同的任务,并且同一个任务也可以有不同级别的弱标注,也就是不同程度的”弱”。 比如,对于图像分类任务来说,有噪音的图像标签属于弱标注。对于目标检测任务和语义分割任务来说,图像标签属于弱标注。说到不同程度的”弱”,拿语义分割举例,图像标签、点标注、线标注、标注框都属于弱标注。所以不同的任务搭配不同的弱标注形式,可以衍生出很多弱样本学习的具体问题。弱样本学习方法的内核是给定任务的基础网络,夹层是弱监督学习框架,外面套了一层如何从基础种类向新种类迁移信息的外壳,如图2所示。我们实验室的弱样本图像分类(weak-shot classification)工作[2]和弱样本目标检测(weak-shot object detection)工作[3]很幸运地同时被NeurIPS2021接收了。

弱样本分类的工作[2]其实是我之前一个工作[1]的延伸。博士期间做了一些基于网络数据的弱监督学习(webly supervised learning)方面的工作和零示例学习方面的工作,然后自然而然做了一个把弱监督学习和零示例学习结合的工作,把所有种类划分成没有交集的基础种类和新种类。基础种类有标注良好的训练图片,是强监督数据。新种类有带噪音的网络图片,是弱监督数据。所有种类都有词向量,以便迁移信息。但是,做[1]这个工作的时候发现如果新种类的弱监督训练数据充足,通过词向量迁移信息基本起不到帮助作用。做完[1]之后,我就想着如何简化问题设定,比如舍弃种类的词向量。一年半前,偶然间想到可以从基础种类向新种类迁移相似度,利用迁移的相似度为新种类的弱监督训练数据去噪。就让学生试了一下,在新种类上的性能提升超过了我的预期。这个工作[2]历经波折,幸运地被NeurIPS接收了。
做完弱样本分类的工作之后,组织学生调研了一下类似的问题设定在其他任务里面有没有做过。调研目标检测之后,发现弱样本目标检测已经有人做过了,但是实验设定非常混乱,起的名字也很混乱(cross-supervised, mixed-supervised)。我们遵循了其中一篇比较新的看起来比较权威的论文[5],做了工作[3],也很幸运地被NeurIPS接收了。调研实例分割之后,发现弱样本实例分割的工作相对较多相对规范,并且统一叫做部分监督实例分割(partially supervised instance segmentation)。调研语义分割之后,发现弱样本语义分割(weak-shot semantic segmentation)好像没有人做过,所以我们又做了一篇弱样本语义分割的工作。在做完弱样本图像分类和弱样本语义分割这两个工作之后,感觉像是填补了拼图上缺失的两块空白,让整个弱样本领域变得更系统更完整了。
思路总结
在看完弱样本学习在不同任务上的方法设计之后,发现在思想上有很多相通之处。我总结了一下,弱样本学习的方法大体可以分成两大类:
- 迁移种类无关的信息:比如similarity, objectness, boundary, saliency等等。这些信息可以从基础种类迁移到新种类。
- 迁移从弱监督信息到强监督信息的映射。因为强监督数据一般也可以获得其弱监督信息(弱样本图像分类除外),可以学习从弱监督标注到强监督标注的映射,或者从弱监督模型到强监督模型的映射,这些映射可以从基础种类迁移到新种类。
编者注:一种是转移内禀属性与怎么监督无关,另一种是把弱监督转换成强监督。
我写了篇弱样本学习的英文概述[4],简要介绍了弱样本学习范式的定义和解决问题的主要思路。相关论文和代码也都整理在github 上 。
链接:https://github.com/bcmi/Awesome-Weak-Shot-Learning
接下来详细介绍我们实验室的弱样本图像分类工作[2]和弱样本目标检测工作[3]。
弱样本图像分类

论文链接:https://arxiv.org/pdf/2009.09197.pdf
数据及代码已开源:https://github.com/bcmi/SimTrans-Weak-Shot-Classification
问题定义
基础种类有强标注(clean label)的图片,而新种类只有弱标注(noisy label)的图片。弱标注的图片可以使用类别名称在公共网站上检索来获得,这是一个有潜力的数据源来支持新种类的学习而不耗费任何的人工标注。研究如何从基础种类向新种类迁移信息,解决新种类训练图片标签噪音的问题。
强标注就是像素级标注,弱标注是图像级标注。
方法介绍
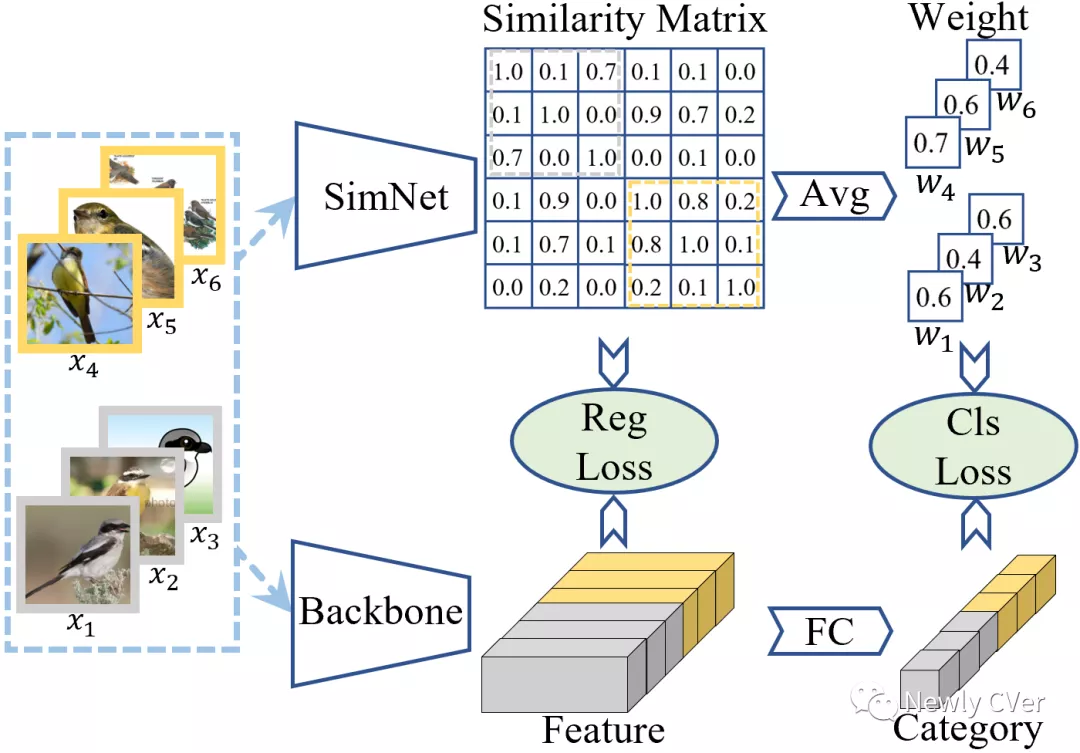
我们方法的训练阶段由两部分组成:在基础种类训练集上学习相似度网络;在新种类数据集上学习主分类器。相似度网络的架构如图3所示,它输入一批图片,然后输出每一对图片之间的相似度分数。其中的枚举层把每一对图片的骨干网络特征拼接起来,称之为关系特征。然后通过全连接层对拼接起来的特征输出相似度分数。相似度分数由分类代价函数监督,如果一对图片是来自于同一个种类,那么就是”相似”种类,反之则为”不相似”种类。如果自由地抽取一批图片,那么绝大多数图片对是来自于不同的种类。所以为了减少相似对和不相似对的不均衡问题,对于每一批图片,我们首先选择少量的种类,然后再从少量的种类中抽取图片。
训练相似度用标签做监督
对于单个新种类中网络图片来说,我们可以发现标签正确的样本通常占大多数。当在单个新种类中计算每一对图片的相似度时,我们可以发现标签错误的样本与其他大部分图片都不相似。因此,我们可以根据一张图片是否与其他图片相似来判断它标签的正确与否。对于每一个新种类,我们首先利用预训练好的相似度网络计算该种类中所有图片对的相似度,得到了一个相似度矩阵,然后我们利用某个图片与其他所有图片的相似度的平均作为该图片的代价函数权重。 然后所有图片的权重规范化到均值为1。最后,将图片的权重应用于分类的代价函数中。通过这样的方式,我们对标签错误样本的分类代价函数施加更低的权重。
当直接在新种类训练集上学习的时候,特征图结构,也就是图片特征之间的相似度,被噪声标签所主导。例如,噪声标签的代价函数隐式地拉近具有相同标签的图片的特征距离。然后这样的特征图结构可能被噪声标签所误导,所以我们试图用迁移来的相似度来纠正被误导的特征图结构。具体地,我们使用经典的图正则化来规范特征,使得语义相似的图片对的特征相近。 网络图片主要有两种噪声:异常值和标签翻转。异常值指图片不属于任务中所考虑的任何种类,而标签翻转指图片的真实标签是所考虑种类中的一种。对于标签翻转噪声,上文介绍的样本权重方法直接通过分配更低的权重抛弃了它们。然后图正则化可以利用它们来保持合理的特征图结构和帮助特征学习。方法细节和实验结果请参见论文。
弱样本目标检测

论文链接:https://arxiv.org/pdf/2110.14191.pdf
代码已开源:https://github.com/bcmi/TraMaS-Weak-Shot-Object-Detection
问题定义
基础种类有强标注(bounding box)的图片,而新种类只有弱标注(image label)的图片。研究如何从基础种类向新种类迁移信息,提升新种类目标检测的性能。
方法介绍
编者注:用mask代替了二分类目标检测器,添加了一个相似度网络,解决一些选框标签错误问题。
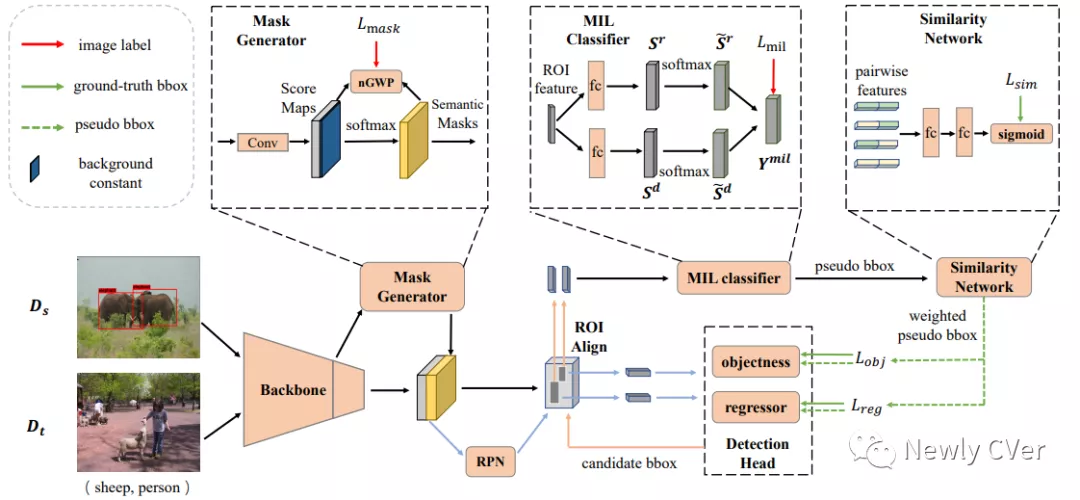
之前的工作[5]提出了一种基于渐进式知识迁移的方案,具体是先利用基础种类的数据去训练一个二分类目标检测器,然后将此检测器学习到的类无关的objectness从基础种类迁移到新种类,用这个二分类目标检测器对新种类的数据做测试,输出的粗糙的候选框再经过一个多实例学习(Multi-Instance Learning)分类器,实现对这些候选框的分类,再根据分类得分筛选出高置信度的候选框作为新种类的伪标注框。得到的伪标注框被添加到前面提到的二分类目标检测器的训练数据中,迭代优化该检测器,后续操作不断迭代进行,从而实现对新种类物体的检测。
我们在这种渐进式知识迁移的基础上,加入了分割掩码(mask)生成器和相似度网络。分割掩码生成器的利用数据中的类标签得到每个种类对应的分割掩码,一共有C个种类,那么最后该分割掩码生成器会输出C个通道的分割掩码。我们将该分割掩码与基础网络输出的特征图进行融合,从而得到掩码增强的特征图,再输入到后续结构中。我们假设利用分割掩码辅助预测候选框的能力可以从基础种类迁移到新种类。
而相似度网络的设计出发点是我们认为在对候选框做筛选的时候,只根据分类得分这一个标准来做筛选的话,太过于粗糙,可能会保留一些被错分类的但是置信度很高的候选框。所以我们设计了一个相似度网络,该网络可以计算两两候选框之间的相似度。那么如果某两个候选框属于同一类的话,这两个候选框应该是具有较高相似度的,反之,两个不同类的候选框会有很低的相似度。我们基于此,筛选出同一类中平均相似度较低的候选框,并将其视为异常候选框。在训练相似度网络时,基础种类中两两相同种类的候选框的相似度为1,而不同类的候选框之间的相似度为0。然后可以计算某个候选框与同类中其他候选框的平均相似度,用于过滤候选框。至此,我们将分割掩码生成器与相似度网络加入到主网络中,如图5所示。训练阶段迭代训练每一个部分,具体流程请参考原文Algorithm 1。方法细节和实验结果请参见论文。
参考文献
- Li Niu, Ashok Veeraraghavan, Ashu Sabharwal, “Webly Supervised Learning Meets Zero-shot Learning: A Hybrid Approach for Fine-grained Classification”, CVPR, 2018.
- Junjie Chen, Li Niu, Liu Liu, Liqing Zhang, “Weak-shot Fine-grained Classification via Similarity Transfer”, NeurIPS, 2021.
- Yan Liu, Zhijie Zhang, Li Niu, Junjie Chen, Liqing Zhang, “Mixed Supervised Object Detection by Transferring Mask Prior and Semantic Similarity”, NeurIPS, 2021.
- Li Niu, “Weak Novel Categories without Tears: A Survey on Weak-Shot Learning”, arXiv preprint arXiv:2110.02651, 2021.
- Yuanyi Zhong, Jianfeng Wang, Jian Peng, Lei Zhang, “Boosting weakly supervised object detection with progressive knowledge transfer”, ECCV, 2020.

若有收获,就点个赞吧
0 人点赞
