自然语言处理,预训练,元学习,注意力机制,Transformer
GPT3是一个用于生成文本的预训练语言模型。给模型一段文字作为输入,模型会根据训练时从海量文字文字中『学习』的模型生成一段新的文字。
相比于GPT1与GPT2,GPT3最大的特点是模型容量和语料规模大幅度提高。
| 模型 | 发布时间 | 参数量 | 预训练数据量 |
|---|---|---|---|
| GPT | 2018.6 | 1.17亿 | 约5GB |
| GPT2 | 2019.2 | 15 亿 | 40GB |
| GPT3 | 2020.5 | 1750亿 | 45TB |
从GPT到GPT3,网络结构上基本没有创新,只是规模越来越大,因此下文从依次介绍GPT,GPT2与GPT3。
GPT1
GPT-1的思想是先通过在无标签的数据上学习一个通用的语言模型,然后再根据特定热任务进行微调,处理的有监督任务,包括:
自然语言推理(Natural Language Inference 或者 Textual Entailment):判断两个句子是包含关系(entailment),矛盾关系(contradiction),或者中立关系(neutral);
问答和常识推理(Question answering and common sense reasoning):类似于多选题,输入一个文章,一个问题以及若干个候选答案,输出为每个答案的预测概率;
语义相似度(Semantic Similarity):判断两个句子是否语义上市是相关的;
分类(Classification):判断输入文本是指定的哪个类别。
用无监督学习做有监督模型的预训练目标,因此叫做通用预训练(Generative Pre-training,GPT)。
网络结构
GPT系列网络结构如下,为单向的Transformer模型,因此善于做输入文字预测后面文字(例如BERT,双向Transformer结构,善于关联上下文),其中Trm为Transformer的Decoder。Transformer模型是Google于2017年在Attention is All You Need文章中提出的。具体关于Transformer的原理结构讲解可以参考The Illustrated Transformer。原始的 transformer模型由encoder和decoder组成,但在随后的许多研究工作中,这种架构要么去掉了encoder,要么去掉了decoder,只使用其中一种transformer堆栈,并尽可能高地堆叠它们,为它们提供大量的训练文本,并投入大量的计算机设备,以训练语言模型。
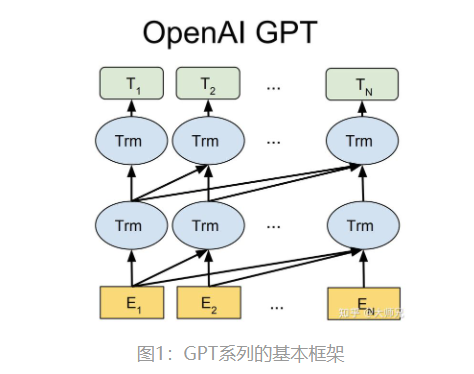
Transformer Decoder内部结构如下左图所示,GPT1堆叠了12个Decoder。
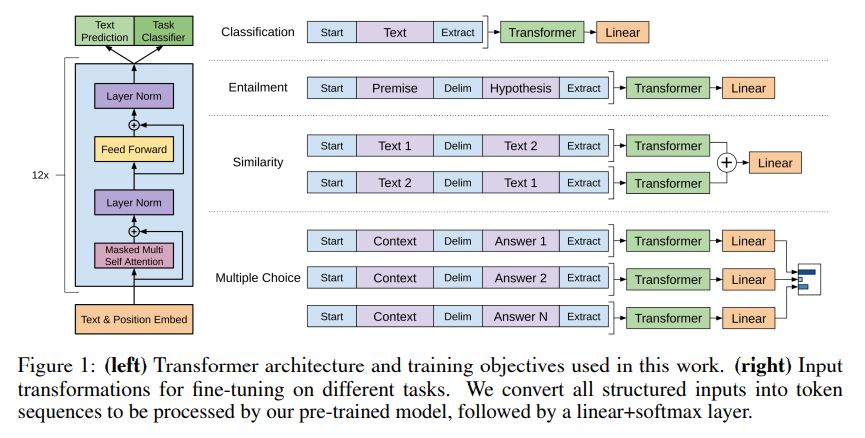
Transform的每个Decoder均由Self Attention层和Feed Forward Neural Network组成。其中Self Attention层是Transformer结构的核心。下面以一个例子简要介绍Self Attention的作用,内容主要摘自The Illustrated GPT-2
Self Attention
语言严重依赖于语境。例如:
A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.
句子中突出显示了三个单词,这三个单词都是指的是其他单词。如果不合并他们所指的上下文,就无法理解或处理这些单词。当模型处理这句话时,它必须能够知道:
it指的是机器人。
Such orders指的是前面所说的人类给予的命令。
The First Law是指前面完整的第一机器人定律。
这就是self-attention层的作用。它结合了模型对有关的和相关连的词的理解,在处理该词之前解释某个词的上下文,并将其传递给神经网络层。它通过为分段中每个单词的相关性分配分数,并将它们的向量表示相加来实现这一点。
作为一个例子,第一模块中的这个self-attention层在处理单词“it”时正在关注“a robot”。它将传递给它的神经网络的向量是三个单词中每一个向量乘以它们的分数之和。

Self-attention 是沿着段中每个token的路径来处理。重要的组成部分是三个向量:
查询向量(query):查询是当前单词的代表,用来去对其他所有词(使用他们的键向量)进行打分,我们只关心我们当前正在处理的token的查询。
键向量(key):键向量类似于段落中所有单词的标签,它们是我们搜索相关单词时所匹配的内容。
值向量(value):值向量是实际的单词表示。一旦我们得出每个单词的相关程度,这些加起来表示当前单词的值。
Attention就是将一个query和一系列 key-value对 (其实就是之前输入的句子)映射为一个输出。
一个简单粗暴的比喻是在档案柜中找文件。查询向量就像一张便利贴,上面写着你正在研究的课题。键向量像是档案柜中文件夹上贴的标签。当你找到和便利贴上所写相匹配的文件夹时,拿出它,文件夹里的东西便是值向量。只不过我们最后找的并不是单一的值向量,而是很多文件夹值向量的混合。
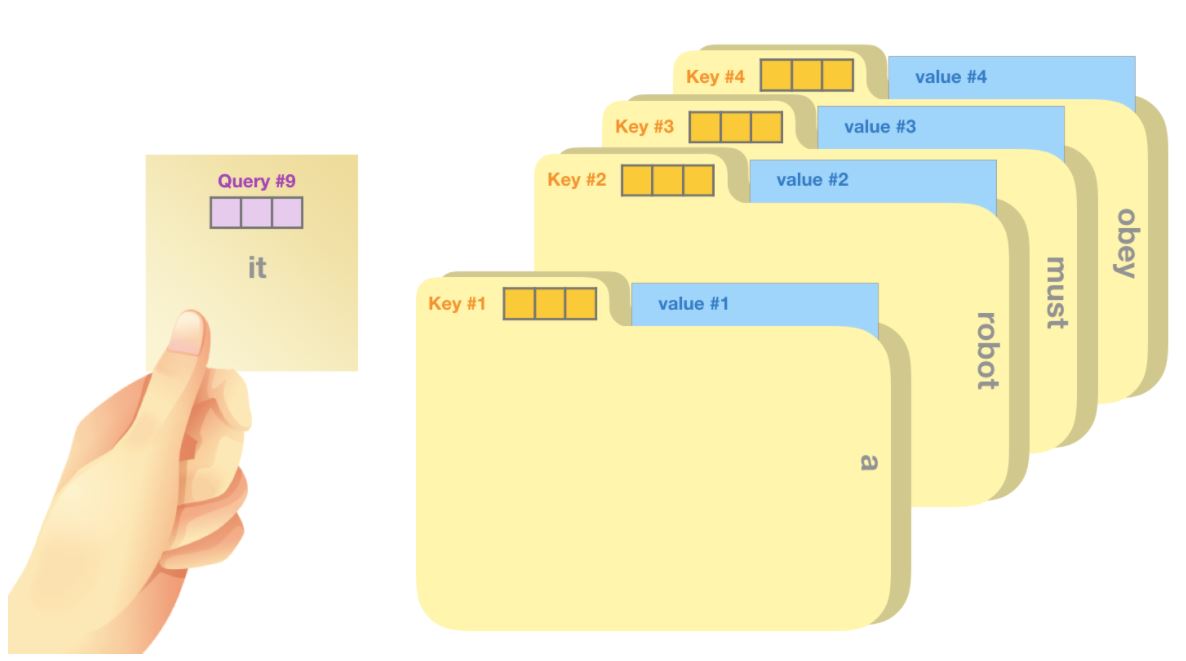
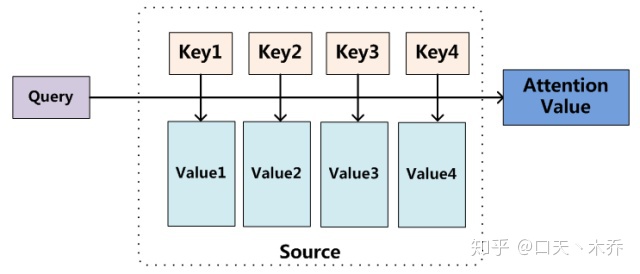
其中query,key,value,是由输入向量乘以对应的3个随网络训练的参数矩阵得到。具体内部计算细节参考The Illustrated GPT-2或The Illustrated Transformer,搜索这个名字可以找到翻译版。
GPT2
GPT-2的目标旨在训练一个泛化能力更强的词向量模型,它并没有对GPT-1的网络进行过多的结构的创新与设计,只是使用了更多的网络参数和更大的数据集。例如,GPT2堆叠的Decoder深度从GPT1的12上升至48,并且参数量大幅提升。
其学习目标是使用无监督的预训练模型做有监督的任务。其核心思想为:任何有监督任务都是语言模型的一个子集,当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务。
GPT2使用的zero-shot学习,为GPT3的in context learning的雏形,将在后面GPT3中介绍。
GPT3
GPT3延续了GPT2的思想,将参数量以及模型容量进一步拉大,其参数量高达1750亿,堆叠的decoder多达96个,训练费用高达1200万美元。
In-context learning
GPT3中使用In-context learning代替了GPT1的微调。下图中左边为三种情景训练方式,右边为微调。其实还是相当于GPT2的训练一个语言模型直接完成多个任务的思想,不过略有不同。

GPT3未使用微调不代表他不可以微调,如果经过微调,其必然会有更好的结果。毕竟这个参数量训练成本已经很高了,训练期间出了个bug Openai也没钱再来一遍了。模型效果随参数量提升的提升并不如线性,费用随模型量提升的提升可能大于线性,后续估计只能在微调或者网络架构上面优化了。
参考文献
Language Models are Few-Shot Learners GPT3
Language Models are Unsupervised Multitask Learners GPT2
Improving Language Understanding by Generative Pre-Training GPT1
Attention Is All You Need Transformer
https://zhuanlan.zhihu.com/p/37601161 Attention
https://zhuanlan.zhihu.com/p/350017443 GPT123比较
https://zhuanlan.zhihu.com/p/56865533 GPT2
https://zhuanlan.zhihu.com/p/54356280 Transformer
https://zhuanlan.zhihu.com/p/104393915 Transformer

若有收获,就点个赞吧
0 人点赞
