〇、概述
2018 年,一段川普鼓励比利时退出巴黎气候协议的视频[1][2]在互联网上炸开了锅。
视频中,他直视摄像机说到:“亲爱的比利时人民,这是一件大事。如你所知,我有勇气退出巴黎气候协议,你也应该这么做。”
此言论一出,立刻在国际舆论上掀起了轩然大波,许多人对美国总统毫不避讳地对比利时的气候政策发表意见表示愤怒……
尽管视频中的声音听起来有点像川普、照片看起来也似乎完全就是他本人,但事实上这并不是真正的特朗普,而是一个由比利时左翼政党 sp.a 制作并发布在 Twitter 和 Facebook 上的虚假视频。
众所周知,如今像这样的影像篡改是不胜枚举的,比如国内曾经著名的华南虎照片事件,还有网上铺天盖地的政客、明星恶搞视频……

当然,这些“作品”有的只是为了娱乐消遣,然而有的却是在欺骗公众,背后的影响足以误导社会舆论、牵动政局稳定,或者损害他人名誉及财产安全,那肯定不会是什么好事,人们应该引起足够的重视。今天我们就来聊一聊影像篡改那些事儿。



随着时间的推移和技术的更替,影像采集、存储和传输等方式就像一场场的接力赛,每一次的变更都留下了深深的时代烙印,而相应的篡改技术也同样经历了如下三个阶段:
- 胶片时代:也称“前 Photoshop 时代”,纸质的照片需要在暗房内通过胶卷冲洗完成,而这一时期较为鲜有的影像篡改也是源于一种“暗房技术”实现的。

- 数字时代:最为人熟知的时代,数字影像的采集、存储能够即刻完成,不必像胶片时代那样需要专业的暗房处理,有一种“开盖即饮”的感觉,而凭借强大的网络通信技术也可以轻松地实现传输自由。
 当然,在这个时期也出现了许许多多的篡改工具,加速了虚假影像的蔓延,它们基本上都可以被概括为“PS 技术”。
当然,在这个时期也出现了许许多多的篡改工具,加速了虚假影像的蔓延,它们基本上都可以被概括为“PS 技术”。 - 人工智能时代:一个技术革新的时代,影像篡改的方法得到进一步扩展,虚假的图片可以直接利用一种叫做“深度学习”的黑盒技术创造出来,而且它的视觉逼真程度更是令人叹为观止。

上图展示了一幅利用一个叫做 StyleGAN 的神经网络训练生成的图片,相信没有多少人能够轻易看出它是假的吧。
当然,这些令人难以置信的照片或许只能让人依稀感受到影像篡改的技术变迁,而对于每个时代的那些神秘技法依旧是充满未知的、令人着迷的。
那么,接下来就让我们首先走进胶片时代,感受一下暗房技术的魅力所在。
一、胶片时代
暗房技术
“胶片”是一个富有年代感的词汇,自从 1888 年美国柯达公司制造出第一个柔软、可卷绕的胶卷以来,距今已有 130 多年的历史。
胶片本身是一种光敏成像材料,主要的作用是通过感光记录画面,而从胶片到相片还有一个最重要的环节就是暗房技术,那么暗房技术究竟是什么呢?
实际上,暗房技术指的是黑暗环境下的一系列照片冲洗技术。当然,冲洗过程需要用到一些器材,比如:放大机、计时器、安全灯、洗相盘、各种化学药水及相纸等,至于它们的使用方法,还是先来看看暗房里是如何工作的?
(1)从相机的胶卷盒中取出卷绕的底片,利用化学药水依次进行显影、停影和定影处理,期间需要使用计时器来严格控制时间;
(2)用温水冲洗已经显现影像内容的底片,去除上面的溶液残留之后挂起来晾干;
(3)在安全灯光下,将底片置于放大机内,反复试验调整以确定理想的曝光时间;
(4)使用放大机将底片上的影像印放到相纸上,相纸也需要控制时间进行显影、停影和定影处理;
(5)在洗相盘中用温水冲洗相纸之后,擦干照片即可装裱使用。
当然,暗房技术还包括一些其他的处理,比如:减淡加深、曝光震动、多次曝光、刮擦底片、修饰底片(如上图)、模糊、上色、裁剪和拼接等。需要用到很多其它的辅助工具[3],比如:喷枪、放大镜、浆糊、墨水、油漆、棉花、灯、刀具、调色板、刷子、橡皮擦、炭笔、刻度尺、胶带等等。
优秀的暗房师们在众多工具的协助下,可以使用二次曝光来拼接照片或底片、可以使用漂白剂照亮照片或完全清洗掉部分内容、可以使用画笔进行手工美术绘画……
事实上,这些技术手法一一对应着我们熟知的 PS 技术,这也就是为什么胶片时代又称“前 Photoshop 时代”,早在 Photoshop 出现以前就已经有了这些处理技术,PS 只是数字化的延伸了暗房技术而已。

帕布鲁•伊尼里奥是一位世界著名的马格南图片社首席暗房师,当年许多经典作品都出自他手,因此一向被誉为“暗房魔术师”。
上图是 20 世纪女神奥黛丽•赫本坐在汽车里的情景,可以看到,左边图上包含了大量的数字注释及线条,其实这些都是这位暗房师的杰作。当然,这张相片经过多次曝光时间的调整后,对比右图可以明显发现,赫本的面部表情和车身反光等效果提升了许多。
试想一下,那是一个没有 PS“选取工具”的年代,这一切都需要依靠人工裁剪出不同形状的遮光片处理完成,纵使是帕布鲁•伊尼里奥这样专业的暗房师,恐怕也需要几个小时甚至更长的时间才能完成一幅如此精良的作品。
美国著名摄影师杰瑞•尤斯曼也是一位顶级的暗房特技大师,他打破了传统摄影美学的限制,通过自身精湛的暗房技术创造出了一幅幅令人惊奇的超现实影像作品,被誉为“后摄影时代”的开拓者。

2016 年,在美国纽约露西奖的艺术摄影颁奖采访[7]中,杰瑞•尤斯曼提到自己有七台放大机,一般刚开始只会用到两、三台,通过观察连续不同的印样来确定基本创作方案后,再反复测试正确的曝光值和遮挡影像的时间,期间还会考虑影像的具体构成元素,大约需要经过几天的时间才能完成这样一幅类似“悬案”的影像作品。
杰瑞•尤斯曼的作品正如他自己所说,“我的最终目的是使我自己感到惊奇,我最大的乐趣便是面对探索过程中的悬念。”
识别方法
影像篡改的暗房处理过程非常“艰辛”,需要借助大量工具经过多次遮挡曝光、底片修饰、模糊、上色、裁剪、拼接等手法才能影印到相纸上。
那么,胶片时代有没有一些有效的真伪识别方法呢?
实际上,胶片时代与我们熟知的数字时代有所不同,复杂的手工处理工序常常会导致“创作”失败,而这种篡改的困难性也使得纸质照片的可信度普遍高于数字图像。此外,对比存储介质本身的差异也能想象到,胶片时代的识别手法要显得单一笨拙很多。
那个年代的人们大多是基于目视法辨别的,当然可以借助一些简单的技术或设备,比如:放大镜、显微镜等。目视法指的是根据照片中的内容特征进行鉴别,比如说:
- 自然规律检验
- 透视规律检验:验证影像中的物体是否遵循空间透视规律,通常,摄像机的拍摄符合小孔成像原理,应该具备近大远小特性。另外,平行于画面的直线应该保持原来的方向不消失,垂直于画面的直线应该相交于一点。
- 光照原理检验:也称“阴影检验法”,一般情况下,光源、物体、影子会在同一直线上,可以观察物体的光影分布是否合理,像那些通过多次曝光拼接合成的照片是很有可能发现端倪的。但是,在多光源或散射光源情况下可能会比较困难。
- 景深原理检验:当相机焦距对准某一点时,在“聚焦平面”前后会形成一个由清晰变模糊的范围,可以分析同一成像平面上是否存在虚实不均的情况。

二、数字时代
数字化篡改与常用工具

数字时代的影像篡改是指什么呢?顾名思义,它指的就是在真实拍摄并记录的影像数据上,人工肆意地去修改这些像素数值。当然,为了篡改的隐蔽性,通常需要根据图像内容进行“有技巧”的修改,下面是一些常见的数字影像篡改手法:
- 复制粘贴,将同一幅图像中的局部区域像素从一个位置复制粘贴到另一个位置;
- 添加删除,在图像中新增或者移除一部分局部区域像素,添加意味着会覆盖掉原有的像素数值,而删除则需要在移除操作之后,利用周围区域的像素数值进行填充;
- 拼接合成,将不同图像中的局部区域拼接合成在一起,通常来自不同图像的拼接内容会在尺寸、色彩、纹理等很多方面存在一定的差异,需要进行一些尺寸调整或者拼接边界的平滑修复处理;
- 裁剪缩放,裁剪是指将图像中一些不需要的内容剔除掉,它与删除操作的区别在于会改变图像尺寸,而缩放是指通过一些像素插值方法来放大或者缩小图像;
- 修饰美化,对图像中一些感兴趣的内容进行修饰、渲染处理,比如美颜相机中常见的人脸美化技术;
- 扭曲变形,将图像中的一些特定目标区域进行无规则的平移、旋转、拉伸等操作,产生局部扭曲或者畸变的效果,比如恶搞人脸视频中的夸张表情。
胶片时代,暗房师们使用了工具,创造出了众多不可思议的经典影像;那先进的数字时代呢?
提到数字时代的影像篡改工具,Photoshop自然是无人不知、无人不晓的,是的,它是一款从胶片时代的手工操纵照片方式延伸过来的数字工具。
事实上,如今像这样的P图工具还有很多,比如:美图秀秀、美颜相机、Facetune、Crazy Talk、Mug Life、ZAO等等。
识别方法
数字水印
以LSB嵌入水印为例,一个8bit Gray图片,根据比特位数可以将图像分为8层,换句话说就是,将图像所有的像素值都表示成一个8位二进制数,每次取8位中的1位得到一个比特平面,共计8个,如下图所示:

可以看出,第1比特图像的像素值几乎是均匀随机的,如果嵌入水印的话并不会干扰到图像内容本身,重构图像也会具有较好的隐蔽性。
当篡改检测时,我们需要做些什么呢?
首先,按照水印嵌入的规则从图像中提取出隐藏的数字水印;然后,将提取的水印内容与已知水印进行比对,验证它的完整性是否遭到破坏即可。
然而,数字水印也是有缺点的,即在如今海量的数字影像中都嵌入水印似乎不太现实。
ELA分析
JPEG量化操作不但可以引入缺陷作为“特殊”水印,更常见的是一种因质量损失而产生的图像错误量。通常,一次压缩对图像所有8x8块引入的错误量基本上是相似的,只有当图像被篡改时,包含篡改位置的8x8块才会与其他部分产生不一致的错误量。
ELA(Error Level Analysis)从图像显示质量的角度出发,将原始图像以一个已知质量等级(如95%)进行压缩并保存成一张新的图像,然后计算两幅图像之间的差别。简单理解就是,将一次压缩产生的图像错误量当作一种被动引入的“特殊”水印。
如果不存在篡改,ELA图像通常处于全局最小错误级别,整张图像都会比较黑暗,只有少许微弱的噪声,反之,在局部就会产生比较强烈的错误级别。

光照一致性
光照一致性是指在同一场景下的物体通常会具有相同的光影分布特性,比如:一群人迎着太阳行走,他们身体前面都会光照较强,而身体后面的影子方向也会基本一致。这种通过太阳或其他光源“制造”出来的一种“特殊”水印也会被动地隐藏在图像数据中。
事实上,光照一致性是从胶片时代目视法中的“光照原理检验法”延伸过来的,在数字影像篡改中,可以通过分析物体表面光源方向的一致性来识别篡改位置。
那么,物体表面光源方向要怎么估计呢?
光源方向估计需要物体表面的闭合边界,一般可利用边缘检测方法结合二次曲线拟合来获取,然后在边界曲线上人工选取一些独立的点分别进行光源方向估计,最后平均所有独立点的预测方向,就能得到物体表面光源方向的估计值。
通常对于拼接合成这类图像,往往篡改物体与其它物体之间不具备相同的光照特性,那么,判别物体表面光源方向是否一致就可以用来识别真伪。然而,这种方法也存在一些自身的缺点,即在无明确方向性光源或有多个复杂光源的场景可能会力不从心。
三、人工智能时代
GAN技术
继 Goodfellow 以后,GAN 技术并没有就此停下脚步,而是逐渐衍生出至少上百种模型,它们都可以轻易实现影像篡改处理,比如:CGAN、DCGAN、WGAN、CycleGAN、PGGAN、StarGAN、SAGAN、BigGAN、StyleGAN……
这些 AI 模型在生成虚假图片上,都不同程度地提升了人眼视觉质量以及模型鲁棒性,下面介绍三种比较流行的 GAN 模型。
CycleGAN
是 2017 年伯克利 AI 研究室提出来的一种用于图像风格迁移的 GAN 模型。
什么是“图像风格迁移”呢?
简单理解就是,将一幅图像从一种风格变换成另一种风格,比如:水墨风格变成油画风格、雨天场景变成雪天场景、航拍照片变成谷歌地图等等。

上图展示了三组图像风格迁移示例,左边是莫奈油画和实景照片之间的转换,中间是斑马和普通马之间的转换,右边是夏天景色和冬天景色之间的转换。
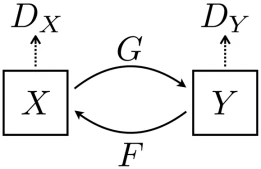
它包含两组风格映射关系,生成器 G 将 X 变换成 Y,生成器 F 将 Y 变换成 X,而判别器 DY 用来约束 Y 的生成质量,判别器 DX 用来约束 X 的生成质量。
当然,为了保证图像风格迁移的质量,其实还引入了一种循环一致性约束。要怎么理解循环一致性呢?顾名思义,就是指经过一次循环变换仍保持图像内容的一致性,比如:图像 X 先经过生成器 G 变换为图像 Y,然后这个 Y 再经过生成器 F 变换为新 X,经历了一次完整的循环,这两个图像 X 应该尽可能保持一致才对。
我们可以看到,CycleGAN 比 Goodfellow 最初的 GAN 模型要复杂了一些,需要使用两组生成器和判别器一起协同工作。不过,它的虚假照片生成质量也是有目共睹的,而且在实际应用上也要更加广泛一些。
彩蛋-wxy同学的本科毕业设计
采集人物正面与背面照片,通过cyclegan进行互相转换,识别改动较大的部位从而实现在不对人脸位置进行标注前提下的人脸初步检测。


PGGAN
2017 年英伟达公司提出的一种渐进式训练 GAN 的模型。
或许你已经略微感觉到 GAN 有一丢丢复杂,嗯……可以理解,GAN 网络的训练过程是比较麻烦的,尤其是在训练一些大型复杂的图像时会比较容易崩掉。而 PGGAN 通过一种渐进式的训练方式可以很好地解决这个。
问题,它是怎么做的呢?
我们不要一上来就直接“学习”复杂的高清图像,而应该从低清开始,学好了之后再逐步提升图像的分辨率,比如:4x4 到 8x8,……,最后到 1024x1024。
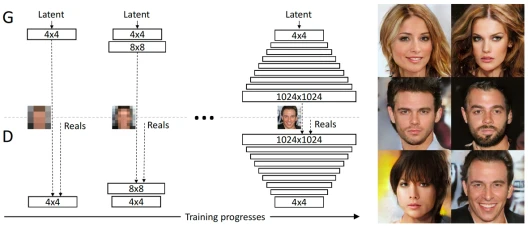
上图展示了从左到右渐进式地提升训练图像的分辨率和网络的层规模,可以看到,刚开始学习的 4x4 图像比较模糊,随后会逐步变得清晰起来。
当然,PGGAN 有了这种相对稳定的训练方式,自然会在一定程度上提升 GAN 网络生成虚假图像的视觉质量。
StyleGAN
StyleGAN是 2018 年英伟达公司提出的一种风格迁移 GAN 模型,它号称可以自动学习对图像高级语义特征的解耦分离。该怎么理解高级语义特征的解耦分离呢?
以一张人脸图片为例,如人脸的姿势、身份以及发型、发色、斑痕、皱纹、胡须等众多高级语义特征在一定程度上其实都是可以分别控制生成的。“解耦分离”这一点对于提升图像生成的多样性以及人们对“黑盒”神经网络的理解都有着重要的意义。
StyleGAN 是如何做到这一点的呢?
- 利用一个映射网络提前学习一种 style A 特征,分别输入到生成器的不同尺度层,A 可以用来控制生成风格的全局属性,如人脸的姿势、身份等;
- 通过高斯噪声获取一种 style B 特征,也分别输入到生成器的不同尺度层,B 可以用来控制一些次要的随机变化,如发型、发色、斑痕、皱纹、胡须等。
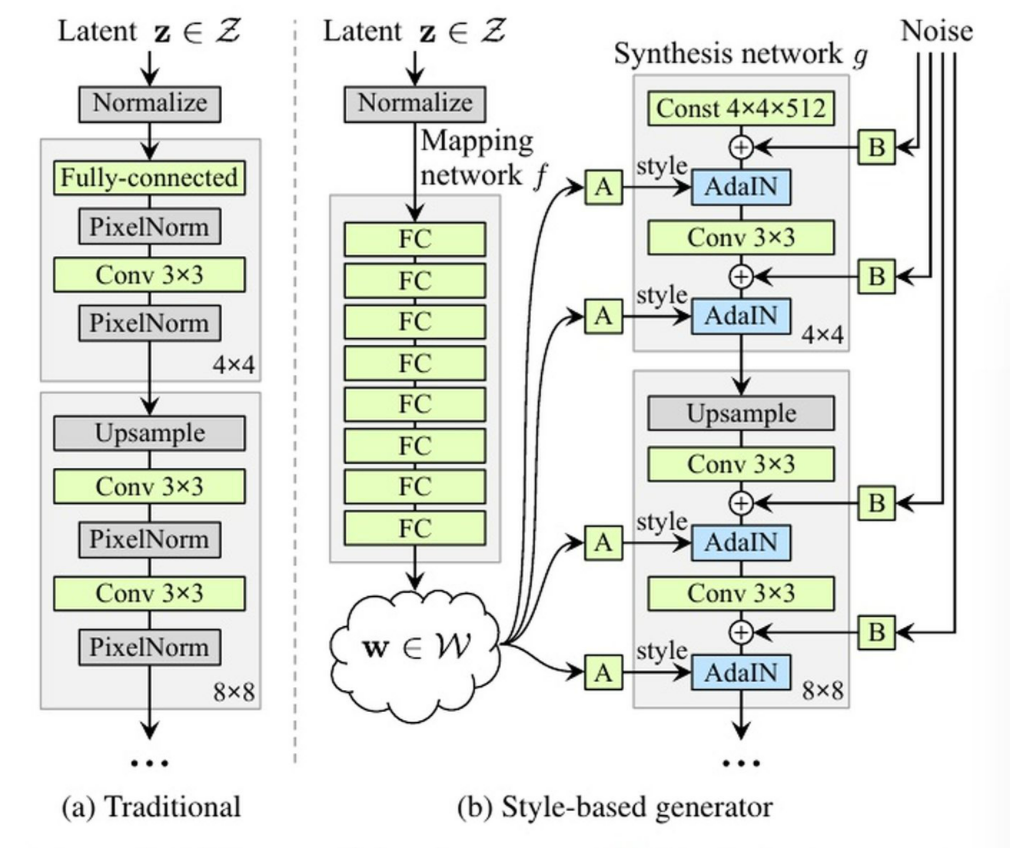
我们能够看出,StyleGAN 与以往 GAN 模型单一输入的生成器结构是不同的,它在生成器中引入了不同风格变量的输入,可以较好的控制不同的高级语义特征。当然,StyleGAN 生成的图片质量也有了更进一步的提升。

识别方法
U-Net
U-Net是 2015 年德国弗莱堡大学的生物信号研究中心提出来的,之所以叫“U-Net”,是因为它的网络结构酷似 U 型。它最初是一种用于医学图像分割的卷积神经网络模型,不过在影像篡改识别问题上,这个网络也同样适用。
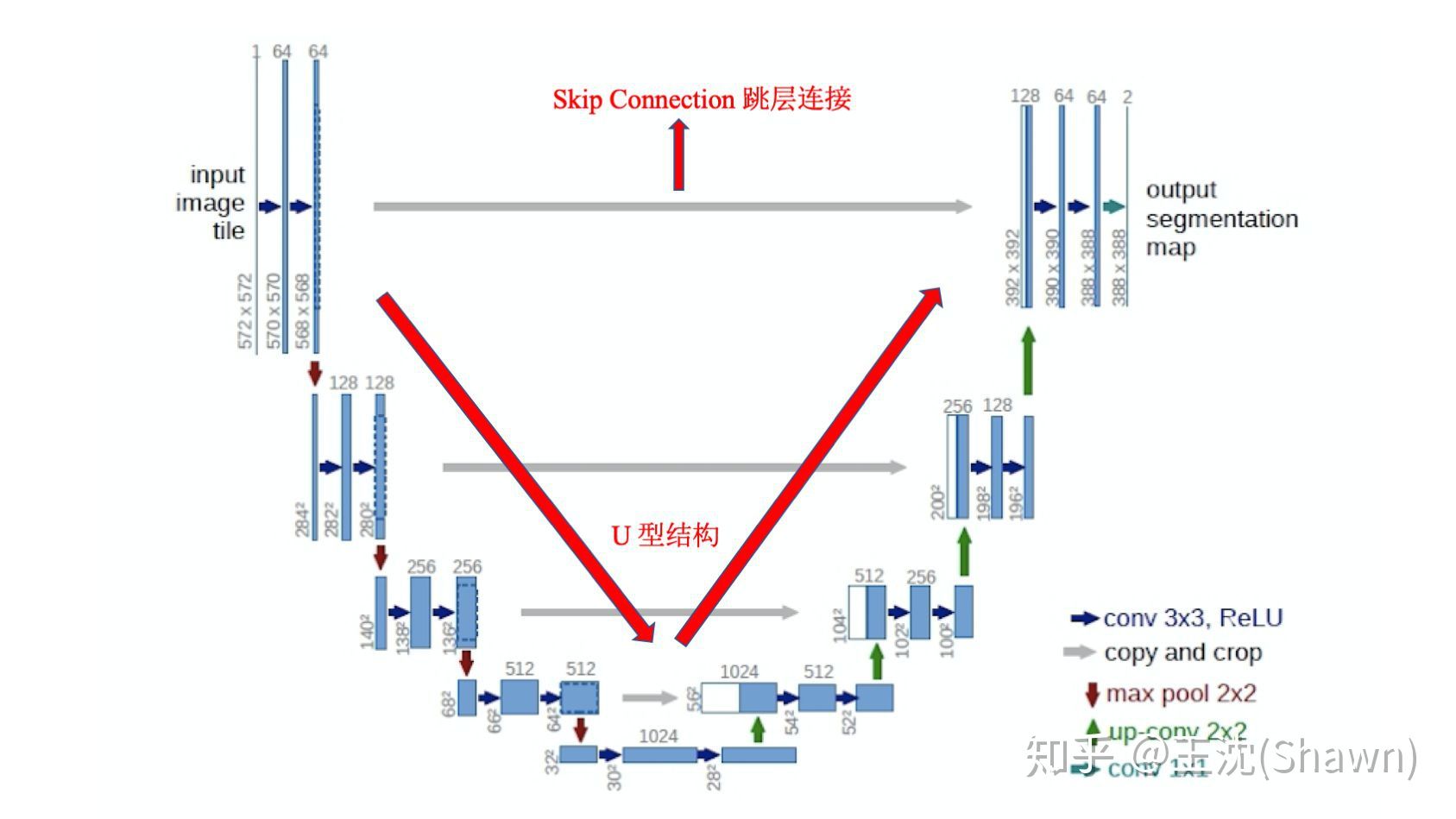
为什么说 U-Net 模型适用呢?
U-Net 是通过 U 型网络将医学 RGB 图片直接学习到二值分割图片的,当然,所谓的“分割特征”是根据网络中一系列的卷积运算自动学习的。
要是我们能够搜集一些篡改 RGB 图片作为训练数据“x”,然后人工标注篡改位置得到二值图片作为训练数据“y”,那么,是不是也可以让 U-Net 网络来集中精力学习图片篡改区域和真实区域之间的差别,进而训练出网络的模型参数“k”和“b”。

上图展示一组训练数据[x, y],左边是湖中复制粘贴两条小船的篡改图片“x”,右边是人工标注篡改位置的二值图片“y”,这个标签 y 是为了告诉模型篡改的位置在哪里。
那么,U-Net 网络要怎么做呢?
- 利用 U 型结构前半部分的卷积和下采样操作,逐层收缩图像数据的分辨率,提取有效的分割特征;
- 利用 U 型结构后半部分的卷积和上采样操作,逐层恢复图像数据的分辨率,实现篡改位置的定位。
U-Net 模型其实也相当于一种 Encoder-Decoder 结构,先对图像数据进行编码提取特征,然后再进行解码生成定位数据。
当 U-Net 网络经过大量的训练数据[x, y]学习后,模型就可以有效地区分出图像中正常区域与篡改区域的像素差异,而之后就算再给它输入一张从未见过的篡改图片,它也能准确地将篡改位置定位识别出来。
视频帧间光流模型
视频帧间光流模型是 2019 年意大利佛罗伦萨大学 MICC 与帕尔马 CNIT 联合提出的一种用于视频篡改检测的模型。
众所周知,一个视频通常包含大量的图像帧(以一个 10s 视频为例,每秒 30 帧就会有 300 帧图像),而这些图像帧之间一般都具有高度相关性,比如:帧间内容的相似性、运动物体的连续性等。
那什么是视频帧间光流呢?
当人们观察空间物体时,物体的运动景象会在人眼的视网膜上形成一连串连续变化的影像,这些影像不断“流过”视网膜,就像是一种光的“流”,所以称作光流。
而光流一般是指空间运动物体在观察成像平面上的像素运动的瞬时速度,它是由于空间物体本身的移动或相机的运动产生的。
对于视频帧间光流,可以简单理解为:在一个视频中,三维空间物体的运动会体现在二维图像帧上产生的一个位置变化,当运动间隔极小时,这种位置变化可以被视为一种描述运动物体瞬时速度的二维矢量。

上图左边展示了一个人说话的视频帧,说话引起嘴巴的运动会在局部产生光流变化,而右边是一个篡改视频的图像帧,可以看出,篡改并不具备这种光流变化特征。
当然,这种反映物体运动瞬时速度的光流,是可以根据视频中连续帧产生的位置变化以及图像帧的时间间隔估计出来的。实际上,这个视频帧间光流模型就是一种帧间光流结合 CNN 进行视频篡改识别的方法。

正如上图 Optical flow,模型先利用颜色编码方法将光流转换成包含 3 个通道的图像数据,其中,像素的颜色由光流矢量方向与水平轴的夹角决定,而颜色的饱和度由运动强度决定。最后,光流特征会基于 CNN 实现篡改检测识别。
四、结束语
人工智能时代,是一个影像篡改识别技术革新的时代。
在篡改伪造方面,除了独占鳌头的 GAN 技术以外,实际上还有一些如变分编码器 VAE(Variational Auto-Encoder)等方法,都能产生以假乱真的影像效果。若这些篡改技术被恶意利用的话,将不由得令人生畏。
相比以前的检测识别,这个时代的特征提取在一定程度上解放了人工是一大进步(由神经网络代劳),但是从解决问题方面来讲仍然尚显不足,如何进一步有效鉴别虚假影像,估计还会在很长一段时间内给人们带来严峻的挑战。
参考文献
影像篡改与识别(一):胶片时代_YDclub的博客-CSDN博客
影像篡改与识别(二):数字时代_YDclub的博客-CSDN博客

若有收获,就点个赞吧
0 人点赞
