机器学习 深度学习 神经网络 迁移学习 计算机视觉 图像识别 自然语言处理 注意力机制 自监督学习 预训练 Transformer
是什么
随着模型(如BERT、DALL-E、GPT-3)的兴起,人工智能正在经历一场范式转变,这些模型在大规模的广泛数据上进行训练,并能适应广泛的下游任务。我们称这些模型为基础模型,以强调它们至关重要但不完整的特性。
基础模型(foundation model)是在大规模的广泛数据上训练的任何模型,并且可以适应(例如,微调)广泛的下游任务;目前的例子包括BERT 、GPT-3 和CLIP。
从技术角度来看,基础模型并不新鲜——它们基于深度神经网络和自监督学习,这两者已经存在了几十年。然而,过去几年基础模型的规模和范围已经超出了我们的想象;例如,GPT-3有1750亿个参数,可以通过自然语言提示进行调整,在广泛的任务中做一项还过得去的工作,尽管没有被明确训练来完成其中的许多任务。与此同时,现有的基础模型有可能加重危害,并且它们的特征通常不为人所知。鉴于它们即将被广泛部署,它们已经成为一个受到严格审查的话题。
Foundation Model vs. Pre-trained Model?
在技术层面上,基础模型是通过迁移学习和规模(scale)实现的。迁移学习的思想是将从一个任务(如图像中的物体识别)中学到的“知识”应用到另一个任务(如视频中的活动识别)。在深度学习中,预训练是转移学习的主要方法:在替代任务上训练模型(通常只是达到目的的一种手段),然后通过微调来适应感兴趣的下游任务。
迁移学习使基础模型成为可能,但规模使它们变得强大。规模需要三个要素:
- 计算机硬件的改进——例如,在过去四年中,图形处理器的吞吐量和内存增加了10倍(4.5:系统);
- Transformer模型架构的开发,该架构利用硬件的并行性来训练比以前更具表现力的模型(4.1:建模);
- 可用性更好的数据。
现状&趋势&机遇&风险
随着 BERT、DALL-E、GPT-3 等大规模预训练模型的出现,AI 社区正在经历一场范式转变。从计算机视觉到自然语言处理,从机器人学到推理、搜索,这些大模型已经无处不在,而且还在继续「野蛮生长」。 这种野蛮生长是大模型的有效性带来的必然结果。在 BERT 出现(2018 年)之前,语言模型的自监督学习本质上只是 NLP 的一个子领域,与其他 NLP 子领域并行发展。但在 BERT 横扫 11 项 NLP 任务之后,这种格局被打破了。2019 年之后,使用自监督学习构造语言模型俨然已经成为一种基础操作,因为使用 BERT 已经成为一种惯例。这标志着大模型时代的开始。 这一时代的重要标志是「同质化」。如今,NLP 领域几乎所有的 SOTA(state-of-the-art)模型都是少数几个基于 Transformer 的大模型进化而来。而且,这种趋势正在向图像、语音、蛋白质序列预测、强化学习等多个领域蔓延。整个 AI 社区似乎出现了一种大一统的趋势。 毋庸置疑,这种同质化是有好处的,大模型的任何一点改进就可以迅速覆盖整个社区。但同时,它也带来了一些隐患,因为大模型的缺陷也会被所有下游模型所继承。基础模型也导致了惊人的「涌现」,这是规模的结果。例如,与GPT-2的15亿个参数相比,GPT-3 有1750亿个参数,它允许上下文学习,其中语言模型可以简单地通过向其提供提示(任务的自然语言描述)来适应下游任务,这是一种既没有经过专门训练也没有预期会出现的意外属性。
同质化和涌现以一种潜在的令人不安的方式相互作用。同质化有可能为任务特定数据非常有限的许多领域带来巨大收益;另一方面,模型中的任何缺陷都会被所有适应的模型盲目继承。由于基础模型的力量来自于它们的涌现质量而不是它们的显式构造,所以现有的基础模型很难理解,并且它们具有意外的故障模式。由于涌现对基础模型的能力和缺陷产生了很大的不确定性,通过这些模型进行激进的同质化是有风险的。
总结:基础模型的可解释性差。
目前,我们强调,我们没有完全理解基础模型提供的基础的性质或质量;我们无法描述“基础”是否值得信任。因此,对于依赖基础模型的研究人员、基础模型提供者、应用程序开发人员、决策者和整个社会来说,这是一个需要解决的关键问题。
典型模型
Bert
打破11项记录:
- MultiNLI(multi-genre natural language inference,文本蕴含识别)
- QQP(quora question pairs,文本匹配)
- QNLI(question natural language inference,自然语言问题推理)
- SST-2(the stanford sentiment treebank,斯坦福情感分类树)
- CoLA(the corpus of linguistic acceptability,语言可接受性语料库)
- STS-B(the semantic textual similarity benchmark,语义文本相似度数据集)
- MRPC(microsoft research paraphrase corpus,微软研究释义语料库)
- RTE(recognizing textual entailment,识别文本蕴含关系)
- WNLI(winograd NLI,自然语言推理)
- SQuAD(the StandFord question answering dataset,斯坦福问答数据集)
- NER(named entity recognition,命名实体识别)
- SWAG(the situations with adversarial generations dataset,)
证明了双向预训练对语言表示的重要性。与之前使用的单向语言模型进行预训练不同,BERT使用遮蔽语言模型来实现预训练的深度双向表示。
论文表明,预先训练模型的参数免去了许多工程任务需要针对特定任务修改体系架构的需求。 BERT是第一个基于微调的表示模型,它在大量的句子级和token级任务上实现了最先进的性能,强于许多面向特定任务体系架构的系统。
假如给一个句子 “能实现语言表征[mask]的模型”,遮盖住其中“目标”一词。从前往后预测[mask],也就是用“能/实现/语言/表征”,来预测[mask];或者,从后往前预测[mask],也就是用“模型/的”,来预测[mask],称之为单向预测 unidirectional。单向预测,不能完整地理解整个语句的语义。于是研究者们尝试双向预测。把从前往后,与从后往前的两个预测,拼接在一起 [mask1/mask2],这就是双向预测 bi-directional。
BERT 的作者认为,bi-directional 仍然不能完整地理解整个语句的语义,更好的办法是用上下文全向来预测[mask],也就是用 “能/实现/语言/表征/../的/模型”,来预测[mask]。BERT 作者把上下文全向的预测方法,称之为 deep bi-directional。如何来实现上下文全向预测呢?BERT 的作者建议使用 Transformer 模型。
这个模型的核心是聚焦机制,对于一个语句,可以同时启用多个聚焦点,而不必局限于从前往后的,或者从后往前的,序列串行处理。不仅要正确地选择模型的结构,而且还要正确地训练模型的参数,这样才能保障模型能够准确地理解语句的语义。BERT 用了两个步骤,试图去正确地训练模型的参数:
- 第一个步骤是把一篇文章中,15% 的词汇遮盖,让模型根据上下文全向地预测被遮盖的词。假如有 1 万篇文章,每篇文章平均有 100 个词汇,随机遮盖 15% 的词汇,模型的任务是正确地预测这 15 万个被遮盖的词汇。通过全向预测被遮盖住的词汇,来初步训练 Transformer 模型的参数。
- 然后,用第二个步骤继续训练模型的参数。譬如从上述 1 万篇文章中,挑选 20 万对语句。挑选语句对的时候,其中_10 万对语句,是连续的两条上下文语句,另外_10 万对语句,不是连续的语句。然后让 Transformer 模型来识别这 20 万对语句,哪些是连续的,哪些不连续。
这两步训练合在一起,称为预训练 pre-training。训练结束后的 Transformer 模型,包括它的参数,是作者期待的通用的语言表征模型。
模型输入:
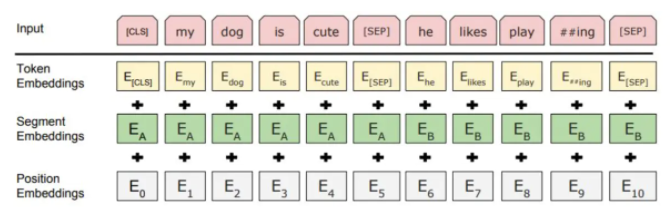
- 使用WordPiece嵌入(Wu et al., 2016)和30,000个token的词汇表。用##表示分词。
- 使用学习的positional embeddings,支持的序列长度最多为512个token。
- 每个序列的第一个token始终是特殊分类嵌入([CLS])。对应于该token的最终隐藏状态(即,Transformer的输出)被用作分类任务的聚合序列表示。对于非分类任务,将忽略此向量。
- 句子对被打包成一个序列。以两种方式区分句子。首先,用特殊标记([SEP])将它们分开。其次,添加一个learned sentence A嵌入到第一个句子的每个token中,一个sentence B嵌入到第二个句子的每个token中。
- 对于单个句子输入,只使用 sentence A嵌入。
BERT刷新了11项NLP任务的性能记录。本文还报告了 BERT 的模型简化研究(ablation study),表明模型的双向性是一项重要的新成果。
对Bert的观点:
- high-performance的原因其实还是归结于两点,除了模型的改进,更重要的是用了超大的数据集(BooksCorpus 800M + English Wikipedia 2.5G单词)和超大的算力(对应于超大模型)在相关的任务上做预训练,实现了在目标任务上表现的单调增长
- 模型的双向训练是性能提升的一大原因
- 可复现性差:有钱才能为所欲为
https://www.jianshu.com/p/4dbdb5ab959b?from=singlemessage
GPT-3
它的参数量要比 2 月份刚刚推出的、全球最大深度学习模型 Turing NLP 大上十倍,而且不仅可以更好地答题、翻译、写文章,还带有一些数学计算的能力。 GPT-3具有1,750亿个参数的自然语言深度学习模型,比以前的版本GPT-2高100倍。该模型经过了将近0.5万亿个单词的预训练,并且在不进行微调的情况下,可以在多个NLP基准上达到最先进的性能。
应用领域
语言
2021年至今,自然语言处理是受基础模型影响最深的领域。第一代基础模型展示了令人印象深刻的各种语言能力,以及对各种语言环境惊人的适应能力。自2018年引入早期基础模型ELMo 和BERT以来,自然语言处理领域已经在很大程度上围绕使用和理解基础模型展开。该领域已转向使用基础模型作为主要工具,将更广泛的语言学习作为中心方法和目标。
基础模型的影响
基础模型对自然语言处理领域产生了巨大的影响,现在是大多数自然语言处理系统和研究的核心。在第一个层次上,许多基础模型是熟练的语言生成器:例如,Clark等人[2021]证明,非专家很难区分GPT-3写的短格式英语文本和人类写的短格式英语文本。然而,在自然语言处理中影响最大的基础模型的特点不是它们原始的生成能力,而是它们惊人的通用性和适应性:单个基础模型可以以不同的方式进行调整,以解决许多语言任务。
语言变体和多语种
随着英语基础模式的成功,多语言基础模式已经发布,将这种成功扩展到非英语语言。对于世界上6000多种语言中的大多数来说,可用的文本数据不足以训练大规模的基础模型。举一个例子,讲西非语言拉夫语的人超过6500万,但拉夫的NLP可用资源很少(如果有的话)[Nguer等人,2020]。多语言基础模型通过同时进行多种语言的联合培训来解决这一问题,迄今为止的多语言基础模型(mBERT、mT5、XLM-R)均接受了约100种语言的培训[Devlin等人,2019年;Goyal等人,2021年;薛等[2020]。多语种联合培训依赖于一个合理的假设,即语言之间共享的结构和模式可以导致高资源语言向低资源语言的共享和转移,从而为我们无法培训独立模式的语言提供基础模式。然而,这些模型在多大程度上是强有力的多语言还是一个悬而未决的问题。
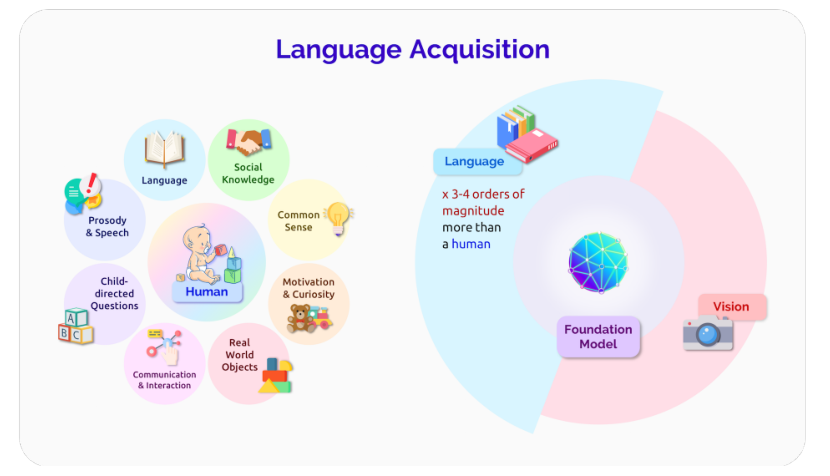
人类语言学习和基础模型。虽然人脑和基础模型之间肯定存在不同的归纳偏见,但它们学习语言的方式也非常不同。最引人注目的是,人类与一个物质和社会世界互动,在这个世界中,他们有各种各样的需求和愿望,而基础模型主要观察和建模他人产生的数据。
基础模型极大地改变了自然语言处理的研究和实践。大多数复杂的自然语言处理任务,在基础模型出现之前,研究团体都专注于解决,现在最好使用少数几个公开发布的基础模型之一来解决。然而,在复杂的下游环境中,这种性能与基础模型的直接和安全实用性之间仍然存在差距。基础模型还为社区带来了许多新的研究方向:将生成理解为语言的一个基本方面,研究如何最好地使用和理解基础模型,理解基础模型可能增加自然语言处理中不平等的方式,检查基础模型是否能够令人满意地包含语言的变化和多样性,以及寻找利用人类语言学习动态的方法。
视觉
CV概况
视觉是生物体理解其生存环境的主要模式之一。视觉能够为智能体带来稳定广泛的密集信号收集能力。计算机视觉领域的几大关键任务,包括:- 语义理解任务;
- 含有几何、运动等元素的三维任务;
- 多模态集成任务,例如视觉问答等。
- 面向医疗保健和家庭环境的外围( ambient )智能领域;
- 移动和消费领域;
- 具体化的、可互动的智能体中领域。
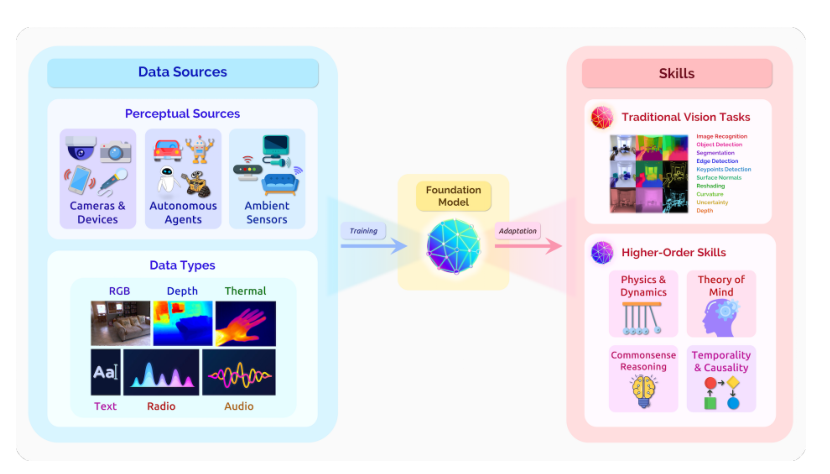 通过大规模利用自监督,视觉基础模型具备一种潜力,即提取原始多模态感知信息并转化为视觉知识,可有效支持传统感知任务,并能够在具有挑战性的高阶技能方面取得新进展。
通过大规模利用自监督,视觉基础模型具备一种潜力,即提取原始多模态感知信息并转化为视觉知识,可有效支持传统感知任务,并能够在具有挑战性的高阶技能方面取得新进展。
视觉的基础模型目前处于早期阶段,但已在传统计算机视觉任务取得了一些改进(特别是在泛化方面),并预计近期的进展将延续这一趋势。然而,从长远来看,基础模型在减少对显式注释的依赖方面的潜力可能会带来智能体基本认知能力(例如,常识推理)的进步。 对于用于下游应用的基础模型的潜在影响,我们强调了几个这样的领域: 1. 医疗保健和家庭环境的环境智能 2. 移动和消费者应用 3. 体现的、交互的智能体 ** ### 基础模型应用于视觉系统的挑战 语义系统性和感知鲁棒性 虽然当前的基础模型已经显示出有希望的图像合成能力和推广到细粒度语言输入的早期结果,但这些模型仍然难以推广到简单形状和颜色的组合。视觉场景和物体的物理动力学和几何属性有着天然的规律性。基础模型显示了理解场景和物体几何形状的早期迹象。此外,在感知模型中对物理场景和几何理解的早期努力可以为正在进行的基础模型开发提供指导。 计算效率和动力学建模 语言的基础模型已经显示出模拟事件长期一致性的初步步骤;捕捉视觉输入中的长期时间相关性和因果一致性的类似能力将有利于机器人等下游环境。然而,相对于语言中的单词标记级输入,低级计算机视觉输入的维度极高:单个1080p帧包含超过200万像素。大规模动态视觉输入的高效建模瓶颈仍然是一个多方面的研究方向,必须在未来加以解决。 训练、环境和评估 目前的视觉基础模型主要集中在一小部分模式(例如,RGB图像和文本数据集),因为这些可能是最容易获得的。这推动了更多大规模培训数据集的开发和使用,这些数据集包含广泛模式的各种投入。我们还想考虑静态数据集之外的环境:经典研究表明,人类的感知理解与其化身和交互式生态环境相关联。 # 参考文献 Bommasani R, Hudson D A, Adeli E, et al. On the Opportunities and Risks of Foundation Models[J]. arXiv preprint arXiv:2108.07258, 2021.

若有收获,就点个赞吧
0 人点赞
