transformer、注意力机制、自然语言处理、计算机视觉、RNN、LSTM、CNN
Attention机制
attention机制:又称为注意力机制,顾名思义,是一种能让模型对重要信息重点关注并充分学习吸收的技术,它不算是一个完整的模型,应当是一种技术,能够作用于任何序列模型中。
按照认知神经学中的注意力,可以总体上分为两类:
- 聚焦式(focus)注意力:自上而下的有意识的注意力,主动注意——是指有预定目的、依赖任务的、主动有意识地聚焦于某一对象的注意力;
- 显著性(saliency-based)注意力:自下而上的有意识的注意力,被动注意——基于显著性的注意力是由外界刺激驱动的注意,不需要主动干预,也和任务无关;可以将max-pooling和门控(gating)机制来近似地看作是自下而上的基于显著性的注意力机制。
在人工神经网络中,注意力机制一般就特指聚焦式注意力。
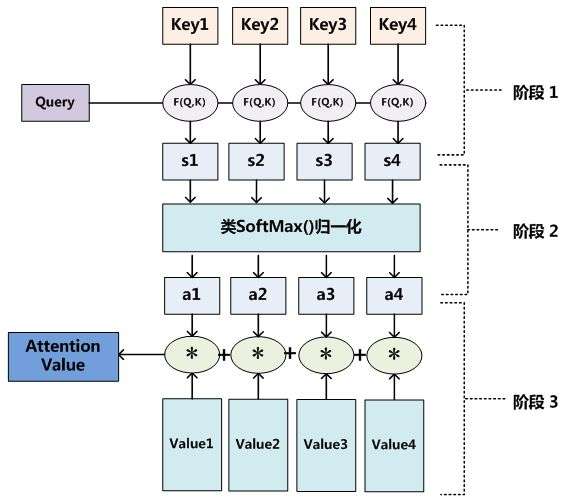
Attention机制的实质其实就是一个寻址(addressing)的过程,给定一个和任务相关的查询Query向量 q,通过计算与Key的注意力分布并附加在Value上,从而计算Attention Value,这个过程实际上是Attention机制缓解神经网络模型复杂度的体现:不需要将所有的N个输入信息都输入到神经网络进行计算,只需要从X中选择一些和任务相关的信息输入给神经网络。
Query对应的是需要被表达的序列(称为序列A),Key和Value对应的是用来表达A的序列(称为序列B)。其中key和query是在同一高维空间中的(否则无法用来计算相似程度),value不必在同一高维空间中,最终生成的output和value在同一高维空间中。上面这段巨绕的话用一句更绕的话来描述一下就是:
序列A和序列B在高维空间
中的高维表达
的每个位置分别和
计算相似度,产生的权重作用于序列B在高维空间
中的高维表达
,获得序列A在高维空间

transformer模型
模型结构如下图:
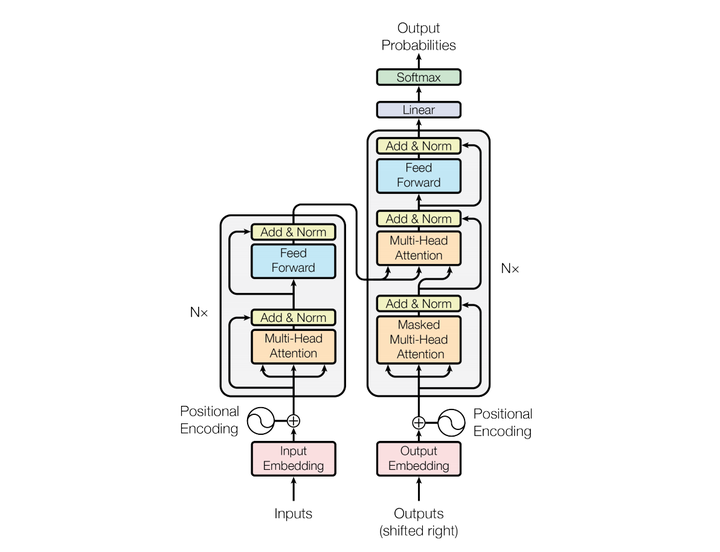
和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。
Multi-head Attention
Attention是将query和key映射到同一高维空间中去计算相似度,而对应的multi-head attention把query和key映射到高维空间中的不同子空间去计算相似度。
Multi-head Attention的本质是,在参数总量保持不变的情况下,将同样的query, key, value映射到原来的高维空间的不同子空间中进行attention的计算,在最后一步再合并不同子空间中的attention信息。这样降低了计算每个head的attention时每个向量的维度,在某种意义上防止了过拟合;由于Attention在不同子空间中有不同的分布,Multi-head Attention实际上是寻找了序列之间不同角度的关联关系,并在最后concat这一步骤中,将不同子空间中捕获到的关联关系再综合起来。
Feed Forward Network
每一层经过attention之后,还会有一个FFN,这个FFN的作用就是空间变换。FFN包含了2层linear transformation层,中间的激活函数是ReLu。
FFN的加入引入了非线性(ReLu激活函数),变换了attention output的空间, 从而增加了模型的表现能力。把FFN去掉模型也是可以用的,但是效果差了很多。
Positional Encoding
位置编码层只在encoder端和decoder端的embedding之后,第一个block之前出现,它非常重要,没有这部分,Transformer模型就无法用。位置编码是Transformer框架中特有的组成部分,补充了Attention机制本身不能捕捉位置信息的缺陷。
优势
Transformer的特性使得encoder的输入向量之间完全平等(不存在RNN那种recurrent结构),token的实际位置和positional encoding唯一绑定,我们可以通过对positional encoding进行操作来改变token在序列中的实际位置。
Transformer从NLP到CV
RNN、LSTM在NLP上的应用
以往的RNN、LSTM的做法基本是将一句话拆分成多个字,然后在训练过程中,按照该句话的前后顺序,按顺序进行输入,输入的LSTM或RNN模块可以根据训练中句子的长度进行调整,较短的句子可以通过占位符进行补齐。也就是说当输入第n个词的时候,我们仅仅有前n-1个词的信息。另外提一下,其中每个字用一个长度固定的vector向量来表示,这种表示方法是根据很大的语料库来获得的,大型语料库尽可能的将每个字编码成为一个特定的vector,我们暂时不管他是one-hot或其他表示方法。总之后面的NLP学习过程基本都是直接应用这批词向量进行。
为了适应整句话前后文的信息,RNN或LSTM逐渐发展为双向学习的。其中时序信息的前后依赖关系通过其中的遗忘门进行选择,这种方法从理论上对于长时间时序依赖关系的考虑是可行的,同时实验也证明了有效性。但是对于长时间的时序依赖关系仍然是有不足的。
Transformer出世,应用于NLP
17年transformer在NLP领域横空出世,transformer就有效的解决了RNN对于长时间的时序依赖关系不足这个问题,仅看transformer结构的输入,将整句话的所有词向量打包成类似图像中的一个batch作为输入,然后其中主要思想是通过内积的方式,内积意义上也是一种相似度匹配,将整句话的词之间的相似度计算出来,作为权重信息合并到这一组词向量中,这样等于就加入了一句话中某个词和其他所有词之间的相关关系,这样在transfomer中叫做self-attention。那么也就是说,通过transfomer这样的输入模式和self-attention操作,我们就可以将整句话中每两个词之间距离拉到相同去公平对待,而不会像RNN、LSTM那样离得越远, 相关关系就越弱。这样就对于很长时间的词依赖关系进行了更多的考虑。而后为了同时也不丢失句子中词本身的顺序信息,transfomer中也在输入词向量前给词向量加入position信息。
Transformer转移CV领域
17年transformer之后,18年紧接着就有将其应用于图像领域,但刚开始做法基本都是针对像素进行处理,使之变成类似词向量的形式。比如将一个patch中所有的像素点进行考虑,然后通过transformer,那么这样的思想是将建模NLP中长时间的词向量相似性变为了建模图像中像素之间的相关性。
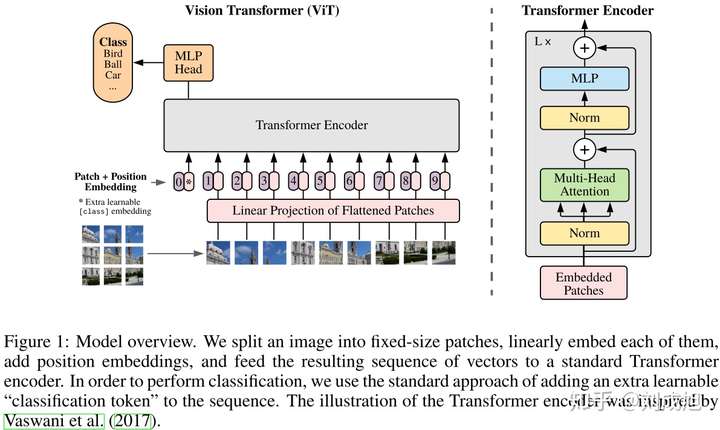
图像分类——ViT
目标检测——DETR
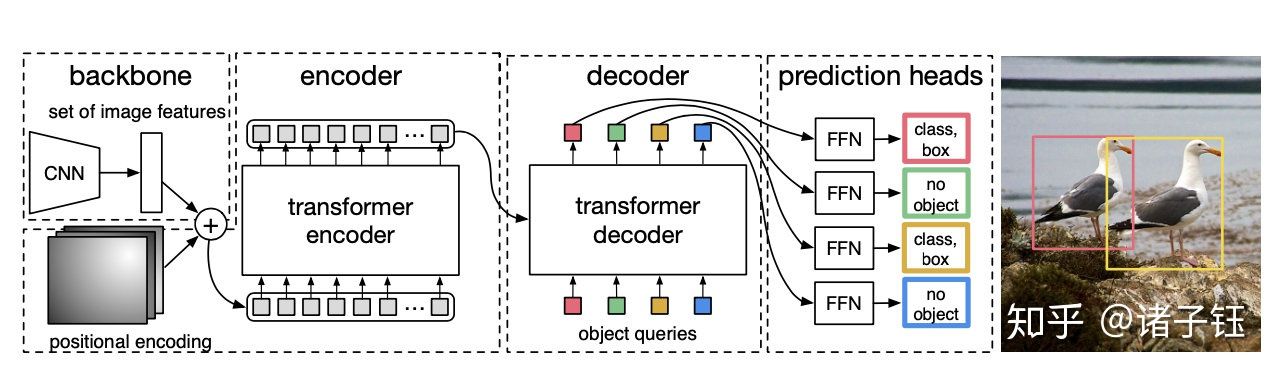
先用CNN提取特征,然后把最后特征图的每个点看成word,这样特征图就变成了a sequence words,而检测的输出恰好是a set objects,所以transformer正好适合这个任务。
实验表明,该模型可达到与经过严格调整的Faster R-CNN基线相当的结果。DETR模型简洁直接,但缺点是训练时间过长,对小目标的检测效果不好。
图像分割——SETR
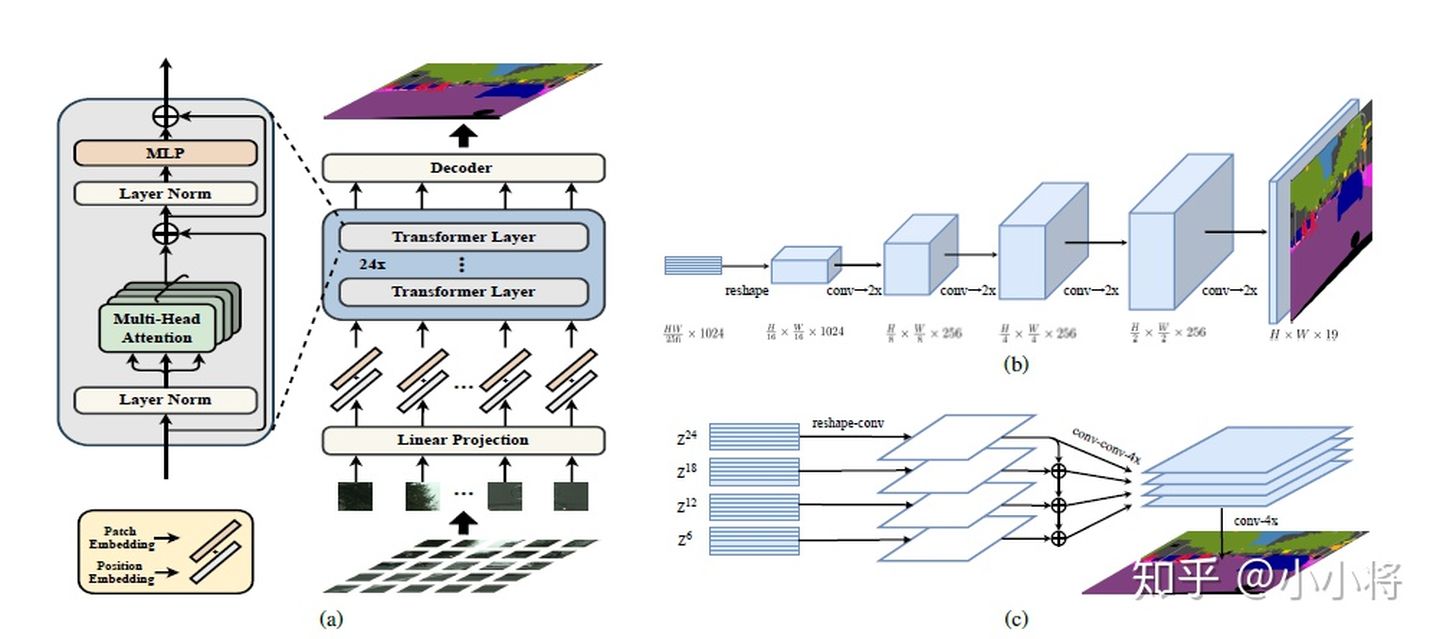
用ViT作为的图像的encoder,然后加一个CNN的decoder来完成语义图的预测。
大量实验表明,SETR在ADE20K(50.28%mIoU)、Pascal上下文(55.83%mIoU)和城市景观上取得了新的水平。特别是在竞争激烈的ADE20K测试服务器排行榜上,取得了第一名(44.42%mIoU)的位置。
Transformer优缺点
优点
1、相较于RNN必须按时间顺序进行计算,Transformer并行处理机制的显著好处便在于更高的计算效率,可以通过并行计算来大大加快训练速度,从而能在更大的数据集上进行训练。
例如GPT-3(Transformer的第三代)的训练数据集大约包含5000亿个词语,并且模型参数量达到1750亿,远远超越了现有的任何基于RNN的模型。算法的并行性非常好,符合目前的硬件(主要指GPU)环境。
2、Transformer模型还具有良好的可扩展性和伸缩性。
在面对具体的任务时,常用的做法是先在大型数据集上进行训练,然后在指定任务数据集上进行微调。并且随着模型大小和数据集的增长,模型本身的性能也会跟着提升,目前为止还没有一个明显的性能天花板。
3、Transformer的特征抽取能力比RNN系列的模型要好。
4、Transformer的设计最大的带来性能提升的关键是将任意两个单词的距离变成1,这对解决NLP中棘手的长期依赖问题是非常有效的。
缺点
1、Transformer模型缺乏归纳偏置能力,例如并不具备CNN那样的平移不变性和局部性,因此在数据不足时不能很好的泛化到该任务上。
然而,当训练数据量得到提升时,归纳偏置的问题便能得到缓解,即如果在足够大的数据集上进行与训练,便能很好地迁移到小规模数据集上。
2、粗暴的抛弃RNN和CNN虽然非常炫技,但是它也使模型丧失了捕捉局部特征的能力,RNN + CNN + Transformer的结合可能会带来更好的效果。
3、Transformer失去的位置信息其实在NLP中非常重要,而论文中在特征向量中加入Position Embedding也只是一个权宜之计,并没有改变Transformer结构上的固有缺陷。
Transformer vs CNN
CNN网络在提取底层特征和视觉结构方面有比较大的优势。这些底层特征构成了在patch level 上的关键点、线和一些基本的图像结构。这些底层特征具有明显的几何特性,往往关注诸如平移、旋转等变换下的一致性或者说是共变性。比如,一个CNN卷积滤波器检测得到的关键点、物体的边界等构成视觉要素的基本单元在平移等空间变换下应该是同时变换(共变性)的。CNN网络在处理这类共变性时是很自然的选择。但当我们检测得到这些基本视觉要素后,高层的视觉语义信息往往更关注这些要素之间如何关联在一起进而构成一个物体,以及物体与物体之间的空间位置关系如何构成一个场景,这些是我们更加关心的。目前来看,transformer在处理这些要素之间的关系上更自然也更有效。从这两方面的角度来看,将CNN在处理底层视觉上的优势和transformer在处理视觉要素和物体之间关系上的优势相结合,应该是一个非常有希望的方向。
参考
https://www.zhihu.com/question/68482809
https://zhuanlan.zhihu.com/p/44121378
https://zhuanlan.zhihu.com/p/104393915

若有收获,就点个赞吧
0 人点赞
