芯片 半导体 人工智能 云计算
通用芯片和专用芯片
我们可以把芯片分为两个大类,一是通用芯片,包括经常听到的CPU、 GPU、 DSP等;二是专用芯片,包括FPGA、ASIC等。这个大类划分很重要,两者有本质上的不同。这里“通用”与“专用”的区别是指该芯片是否是仅为执行某一种特定运算而设计,用银行来做个简单的比喻,通用芯片就是“银行柜员”,可以处理各种复杂的业务;而专用芯片就是“ATM机”,将某些流程标准化并固化在硬件中,做一台没有感情的处理机器。“通用”与“专用”并不是指该芯片是否仅用于某一种产品或使用场景,比如intel所研发的用于PC的CPU,这颗芯片仅用在PC上,但它不是我们这里说的“专用”芯片。通用芯片:灵活
专用芯片:高效
AI 芯片
定义
目前关于AI 芯片并没有一个严格的定义。比较宽泛的定义是面向人工智能应用的芯片都可以称为AI 芯片。
AI 芯片主要包括三类:
- 经过软硬件优化可以高效支持AI 应用的通用芯片,例如GPU,FPGA;
- 专门为特定的 AI 产品或者服务而设计的芯片,称之为ASIC(Application-Specific Integrated Circuit),主要是侧重加速机器学习(尤其是神经网络、深度学习),这也是目前AI 芯片中最多的形式;
- 受生物脑启发设计的神经形态计算芯片,这类芯片不采用经典的冯·诺依曼架构,而是基于神经形态架构设计,以 IBM Truenorth为代表。
- APU — Accelerated Processing Unit, 加速处理器,AMD公司推出加速图像处理芯片产品。
- BPU — Brain Processing Unit, 地平线公司主导的嵌入式处理器架构。
- CPU — Central Processing Unit 中央处理器, 目前PC core的主流产品。
- DPU — Deep learning Processing Unit, 深度学习处理器,最早由国内深鉴科技提出;另说有Dataflow Processing Unit 数据流处理器, Wave Computing 公司提出的AI架构;Data storage Processing Unit,深圳大普微的智能固态硬盘处理器。
- FPU — Floating Processing Unit 浮点计算单元,通用处理器中的浮点运算模块。
- GPU — Graphics Processing Unit, 图形处理器,采用多线程SIMD架构,为图形处理而生。
- HPU — Holographics Processing Unit 全息图像处理器, 微软出品的全息计算芯片与设备。
- IPU — Intelligence Processing Unit, Deep Mind投资的Graphcore公司出品的AI处理器产品。
- MPU/MCU — Microprocessor/Micro controller Unit, 微处理器/微控制器,一般用于低计算应用的RISC计算机体系架构产品,如ARM-M系列处理器。
- NPU — Neural Network Processing Unit,神经网络处理器,是基于神经网络算法与加速的新型处理器总称,如中科院计算所/寒武纪公司出品的diannao系列。
- RPU — Radio Processing Unit, 无线电处理器, Imagination Technologies 公司推出的集合集Wifi/蓝牙/FM/处理器为单片的处理器。
- TPU — Tensor Processing Unit 张量处理器, Google 公司推出的加速人工智能算法的专用处理器。目前一代TPU面向Inference,二代面向训练。TPU与同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。
- VPU — Vector Processing Unit 矢量处理器,Intel收购的Movidius公司推出的图像处理与人工智能的专用芯片的加速计算核心。
- WPU — Wearable Processing Unit, 可穿戴处理器,Ineda Systems公司推出的可穿戴片上系统产品,包含GPU/MIPS CPU等IP。
- XPU — 百度与Xilinx公司在2017年Hotchips大会上发布的FPGA智能云加速,含256核。
- ZPU — Zylin Processing Unit, 由挪威Zylin 公司推出的一款32位开源处理器。
AI芯片的关键特征:
- 新型的计算范式:AI 计算既不脱离传统计算,也具有新的计算特质,如处理的内容往往是非结构化数据(视频、图片等)。处理的过程通常需要很大的计算量,基本的计算主要是线性代数运算(如张量处理),而控制流程则相对简单。处理的过程参数量大。
- 训练和推断:AI 系统通常涉及训练(Training)和推断(Inference)过程。简单来说,训 练过程是指在已有数据中学习,获得某些能力的过程;而推断过程则是指对新的数据,使用这些能力完成特定任务(比如分类、识别等)。
- 大数据处理能力:人工智能的发展高度依赖海量的数据。满足高效能机器学习的数据处理要求是AI 芯片需要考虑的最重要因素。
- 数据精度:低精度设计是AI 芯片的一个趋势,在针对推断的芯片中更加明显。对一些应用来说,降低精度的设计不仅加速了机器学习算法的推断(也可能是训练),甚至可能更符合神经形态计算的特征。
- 可重构的能力:针对特定领域(包括具有类似需求的多种应用)而不针对特定应用的设计,将是AI 芯片设计的一个指导原则,具有可重构能力的AI 芯片可以在更多应用中大显身手,并且可以通过重新配置,适应新的AI 算法、架构和任务。
- 开发工具:就像传统的CPU 需要编译工具的支持, AI 芯片也需要软件工具链的支持,才能将不同的机器学习任务和神经网络转换为可以在AI 芯片上高效执行的指令代码,如NVIDIA GPU 通过CUDA 工具获得成功。
主要厂商&市面上主流芯片
高通
- 骁龙888:AI第六代引擎,每秒高达算力26TOPS,每瓦特性能提升至前代的3倍,在升级版的骁龙888 Plus上面,通过CPU升频的方式,又将AI计算能力提升了20%,达到了惊人的32万亿次。
海思
- 麒麟9000:基于5nm工艺制程的手机Soc,基于5nm工艺制程打造,集成多达153亿个晶体管,包括一个3.13GHz A77大核心、三个2.54GHz A77中核心、四个2.04GHz A55小核心。
平头哥
- 含光800:12nm工艺+709平方毫米大核心。在业界标准的ResNet-50测试中,含光800推理性能达到78563 IPS,比目前业界最好的AI芯片性能高4倍;能效比500 IPS/W,是第二名的3.3倍。
寒武纪:同时发力终端和云端芯片,技术综合实力较强。
- 思元370:第三代云端AI芯片思元370,基于7nm制程工艺,是寒武纪首款采用chiplet(芯粒)技术的AI芯片,集成了390亿个晶体管,最大算力高达256TOPS(INT8),是寒武纪第二代产品思元270算力的2倍。
Google:TPU 芯片已经实现从云到端,物联网 TPU Edge 是当前布局重点
Nvidia:AI 芯片市场的领导者,计算加速平台广泛用于数据中心、自动驾驶等场景。推出有Tensorcore等。人工智能方面,英伟达面向人工智能的产品有两类,Tesla 系列 GPU 芯片以及 DGX 训练服务器。
未来趋势
- 云端训练和推断:大存储、高性能、可伸缩。
- 边缘设备:把效率推向极致。
- 软件定义芯片。
云服务器芯片
定义
云芯片——即用于云服务器的CPU芯片
背景现状
在数据中心服务器CPU领域,根据Trendforce在2021年8月的文章估计,使用ARM架构的服务器芯片只占到了整个市场的3%,其余97%仍然是X86芯片,并且认为至少在2023年之前,ARM芯片还无法和X86芯片抗衡。主流厂商&市面上主流芯片
X86架构
- Intel
- AMD
ARM架构
- AWS(亚马逊云) Graviton2
- 华为 鲲鹏920
- 平头哥 倚天710
- 等等
- 华为的鲲鹏920在获得了ARM V8的永久授权之后,目前在独立发展。在华为发布的《鲲鹏计算产业白皮书》里面,写明了鲲鹏处理器核、微架构和芯片均由华为自主研发设计,鲲鹏计算产业兼容全球Arm生态,二者共享生态资源,互相促进、共同发展,称之为鲲鹏生态。
- 倚天710采用业界最先进的5nm工艺,单芯片容纳高达600亿晶体管;在芯片架构上,基于最新的ARMv9架构,内含128核CPU,主频最高达到3.2GHz,能同时兼顾性能和功耗。在内存和接口方面,集成业界最领先的DDR5、PCIe5.0等技术,能有效提升芯片的传输速率,并且可适配云的不同应用场景。在SPECInt2017基础测试平台上,跑分达到440分,是性能最强的服务器芯片,超出业界标杆20%,能效比优于业界标杆50%,能有效帮助数据中心节能减排。
未来趋势
国内
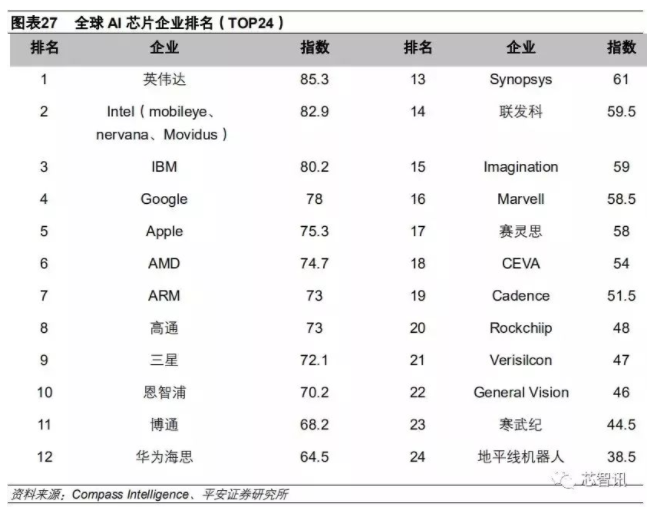
芯片设计这个行业,国内目前还非常缺乏巨头公司,相比高通、博通、英特尔、联发科、AMD、苹果、Nvidia这些巨头芯片设计公司,国内的芯片设计企业还处于小而散的阶段,都还没有到“大而不强”的阶段。而我们也可以看出,以上这些国际巨头,基本都具备很强的通用CPU的设计能力,以及占有大量的全球份额,具备雄厚的资本和技术实力。而在服务器芯片的通用CPU领域,国内主要就只有海思鲲鹏,而拥有雄厚资金实力,以及自带不断增长的云服务器需求的阿里的入局服务器芯片,这相比之前平头哥发布的AI芯片和RISC-V处理器更向前了一步,无疑是件好事,阿里在这方面走出了第一步,这是一个进步。
公司调研:平头哥半导体有限公司
主营业务
技术开发、技术服务、技术咨询、技术成果转让:软件、电子产品(除电子出版物)和半导体集成电路科技;电子产品(除电子出版物)和半导体集成电路产品的设计、封装、测试、制造与销售;电子产品(除电子出版物)和半导体集成电路产品的代理;货物及技术的进出口业务(法律、行政法规禁止经营的项目除外,法律、行政法规限制经营的项目取得许可证后方可经营)等。发展历程
2018年9月19日,阿里巴巴首席技术官张建锋在云栖大会上表示,阿里巴巴正式宣布:合并中天微达摩院团队,成立平头哥半导体芯片公司 2018年10月31日,平头哥半导体有限公司注册成立。 2018年11月7日,一家叫平头哥(上海)半导体技术有限公司正式注册,注册资本1000万,且注册地正是浙江。法定代表人为刘湘雯。股东信息显示,其股东发起人正是阿里巴巴达摩院(杭州)科技有限公司。 2019年7月25日,阿里巴巴旗下半导体公司平头哥发布公司成立后第一个成果基于RISC-V的处理器IP核玄铁910,阿里巴巴集团副总裁戚肖宁表示,其可用于设计制造高性能端上芯片,应用于5G、人工智能以及自动驾驶等领域。使用该处理器可使芯片性能提高一倍以上,同时芯片成本降低一半以上。 2019年9月25日,阿里巴巴在2019云栖大会上正式对外发布含光800AI芯片,含光为上古三大神剑之一,含而不露,光而不耀。产品反馈
含光800
2021双11期间,含光800通过阿里云平台支持了淘宝搜索、推荐等业务,其中淘宝主搜100%的AI算力由该芯片提供。实际应用情况显示,含光800有效发挥了芯片与云计算环境融合的优势,既提升了系统的性能又降低了整体能耗,以搜索场景为例,相比传统GPU,使用含光800运行的算法效率最高可提升近2倍,单位算力能耗降低58%。参考文献

若有收获,就点个赞吧
0 人点赞
