多模态;度量学习;表示学习;图像识别;深度学习;主题模型;玻尔兹曼机;哈希算法;自编码器
背景介绍
跨模态检索属于跨模态学习研究“生成”、“问答”、“检索”三大研究应用方向之一。“生成”指根据一张图生成其描述或根据一句话生成对应的图片。VQA侧重于内容理解,是根据图片内容进行提问。这两个研究领域属于细粒度的研究。“检索”是语义级别的理解,不需要太细粒度,给定一个模态中的信号,让你在另一个模态的空间中找到”对应的”或者最接近的若干个信号;该问题可转化为给出两个不同模态的信号,判断其相似程度。

定义
学习一种跨模态的相似性度量,对给定查询词,返回最相似的另一模态的样本。
数据集
Wikipedia数据集
该数据集包含2866个图像文本数据对,共10个不同的语义类。显然该数据集存在语义类少,模态类型有限,只包括图像文本两种模态等不足。链接:http://www.svcl.ucsd.edu/projects/crossmodal/.
XMedia数据集
数据集由北京大学多媒体计算实验室通过Wikipedia、Flickr、YouTube等来源采集。共包括20个语义类,每一类分别包含250段文本、250幅图像、25段视频、50段语音、25个3D模型五种不同模态,是目前跨模态检索领域数据量最大,模态最多的一个数据集。链接:http://www.icst.pku.edu.cn/mipl/XMedia.
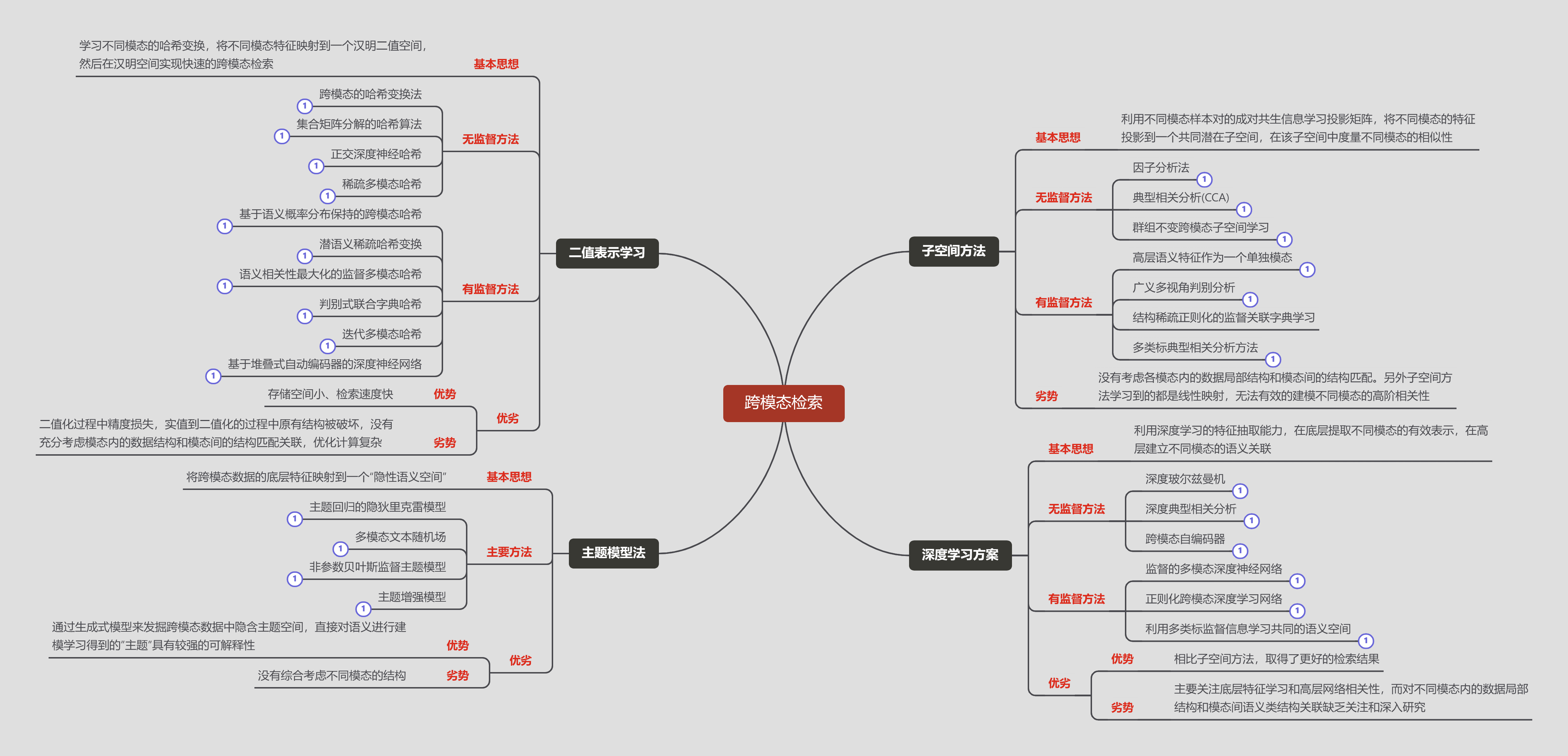
主要方法
评价指标
平均精度均值(Mean Average Precision),是平均精度(AP)的平均值,后者定义如下:
$ AP=\frac{1}{R}\sum_{r=1}^{R}P(r)\delta(r) $
其中P(r)代表查询结果排名为r的样本的得分,若该样本与查询样本相关则δ为1,不相关则为0。
未来发展
大规模数据集的采集
XMedia只包含20类语义信息,可以参照ImageNet思路,建立语义类更多、模态类型更多的跨模态数据集。
精细的模态表示
不同模态的精细表示是保持判别性的主要途径。现有方法在单模态表示时过于粗糙,如用SIFT等表示图像模态。这些统计特征忽略了图像的空间信息,不利于后续跨模态关联建模。
多角度的模态关联建模
跨模态检索的关键是建立不同模态之间的关联。这需要从模态间语义类关联、模态共生关联、局部结构相似关联等角度建立模态间多层次、多结构的关联。
与深度学习融合发展
度学习的分层特征抽象能力为图像的表示学习提供了很好的思路。如何结合深度学习的分层特征学习特点,分层次建立不同模态间关联是值得关注的研究方向。
参考文献
- 欧卫华, 刘彬, 周永辉,等. 跨模态检索研究综述[J]. 贵州师范大学学报(自然科学版), 2018, 36(02):118-124.
- 评价指标分析 https://blog.csdn.net/Flyingzhan/article/details/84779607
- 研究背景介绍 https://mp.weixin.qq.com/s?__biz=MzIxMzQ1NzIxOA==&mid=2247483701&idx=1&sn=6ff869d7417766f368cf3da39f94ee22&chksm=97b7c118a0c0480e0359e33779d52dab89a3440103af9ae7a494215e41e6b1335f5cac1499da&scene=21#wechat_redirect
- 多模态学习研究综述 https://cloud.tencent.com/developer/article/1628169

若有收获,就点个赞吧
0 人点赞
