论文试图对Transformer逆向工程采取初步的、非常初步的步骤。 鉴于现代语言模型令人难以置信的复杂性和规模,我们发现从最简单的模型开始并从那里开始工作是最富有成效的。 我们的目标是发现可以随后应用于更大更复杂模型的简单算法模式、主题或框架。 具体来说,在本文中,我们将研究只有两层或更少层且只有注意力块的转换器——这与像 GPT-3 这样的大型Transformer形成对比,后者有 96 层,并且注意力块与 MLP 块交替出现。
零层Transformer
二元表可以直接通过权重访问。

零层 attention-only transformers 模型。
单层Transformer
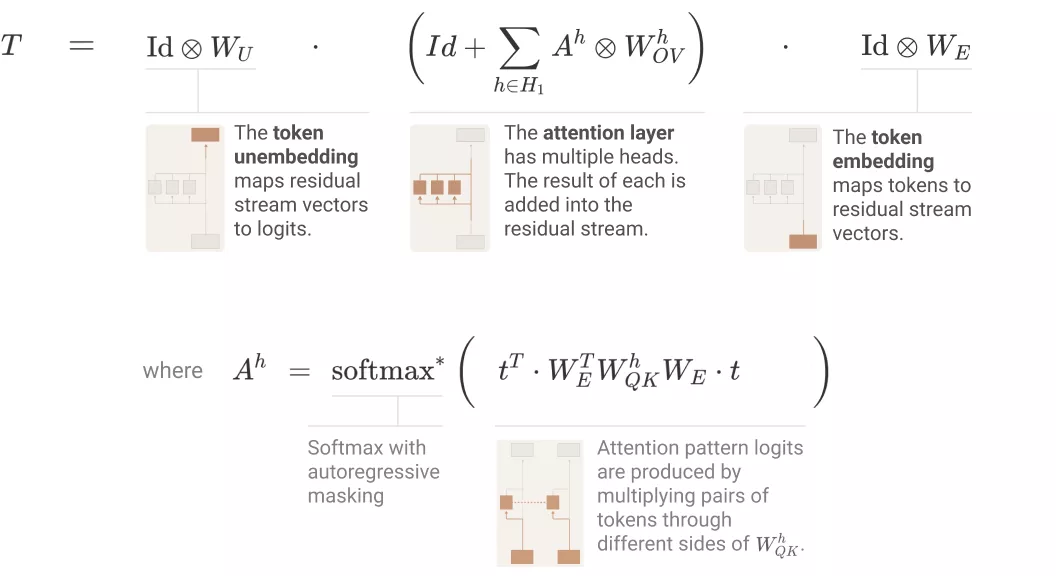
单层 attention-only transformers 是二元和 skip 三元模型的集合。同零层 transformers 一样,二元和 skip 三元表可以直接通过权重访问,无需运行模型。这些 skip 三元模型的表达能力惊人,包括实现一种非常简单的上下文内学习。
在路径扩展(path expansion)方面,如下图所示,单层 attention-only transformers 由一个 token 嵌入组成,后接一个注意力层(单独应用注意力头),最后是解除嵌入:

两层Transformer
两层 attention-only transformers 模型可以使用注意力头组合实现复杂得多的算法。这些组合算法也可以直接通过权重检测出来。需要注意的是,两层模型适应注意力头组合创建「归纳头」(induction heads),这是一种非常通用的上下文内学习算法。
对于 transformer 有一个最基础的问题,即「如何计算 logits」?与单层模型使用的方法一样,研究者写出了一个乘积,其中每个项在模型中都是一个层,并扩展以创建一个和,其中每个项在模型中都是一个端到端路径。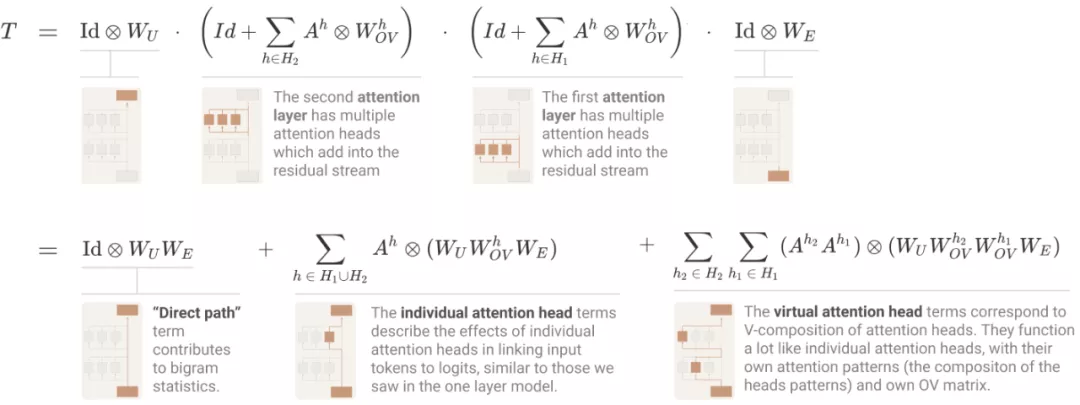

若有收获,就点个赞吧
0 人点赞
