知识图谱;大数据;多模态;推荐系统;智能问答;语义网络;实体提取;图论;
1. 传统知识图谱
知识图谱是由Google公司在2012年提出来的一个新的概念。从学术的角度,我们可以对知识图谱给一个这样的定义:“知识图谱本质上是语义网络(Semantic Network)的知识库”。但这有点抽象,所以换个角度,从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图(Multi-relational Graph)。
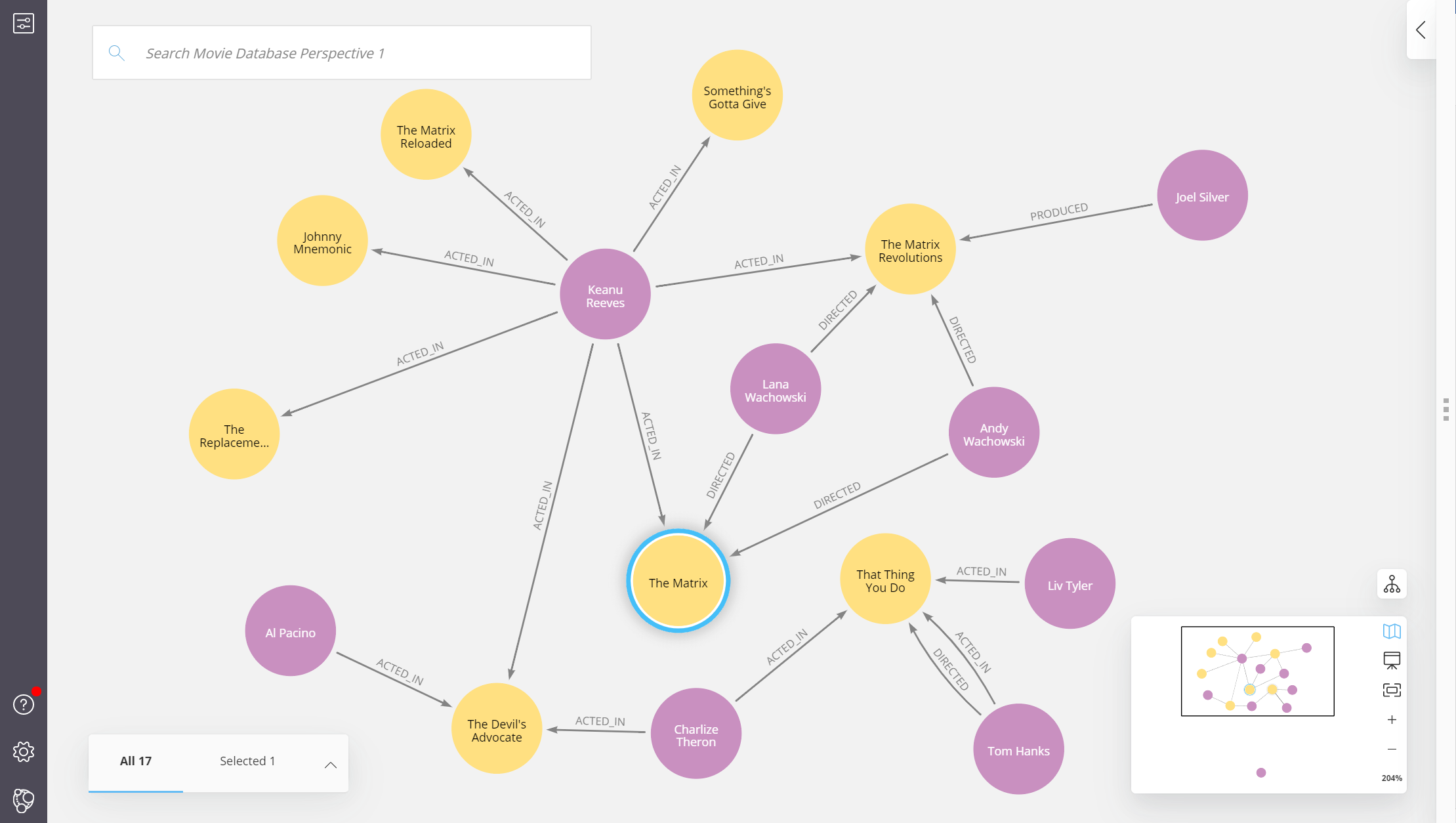
2. 多模态
多模态机器学习,英文全称 MultiModal Machine Learning (MMML),旨在通过机器学习的方法实现处理和理解多源模态信息的能力。目前比较热门的研究方向是图像、视频、音频、语义之间的多模态学习。举例:多模态表示学习,文字/图片的相互转换,

3. 多模态知识图谱(以Richpedia为例)
多模态知识图谱与传统知识图谱的主要区别是,传统知识图谱主要集中研究文本和数据库的实体和关系,而多模态知识图谱则在传统知识图谱的基础上,构建了多种模态(例如视觉模态)下的实体,以及多种模态实体间的多模态语义关系。
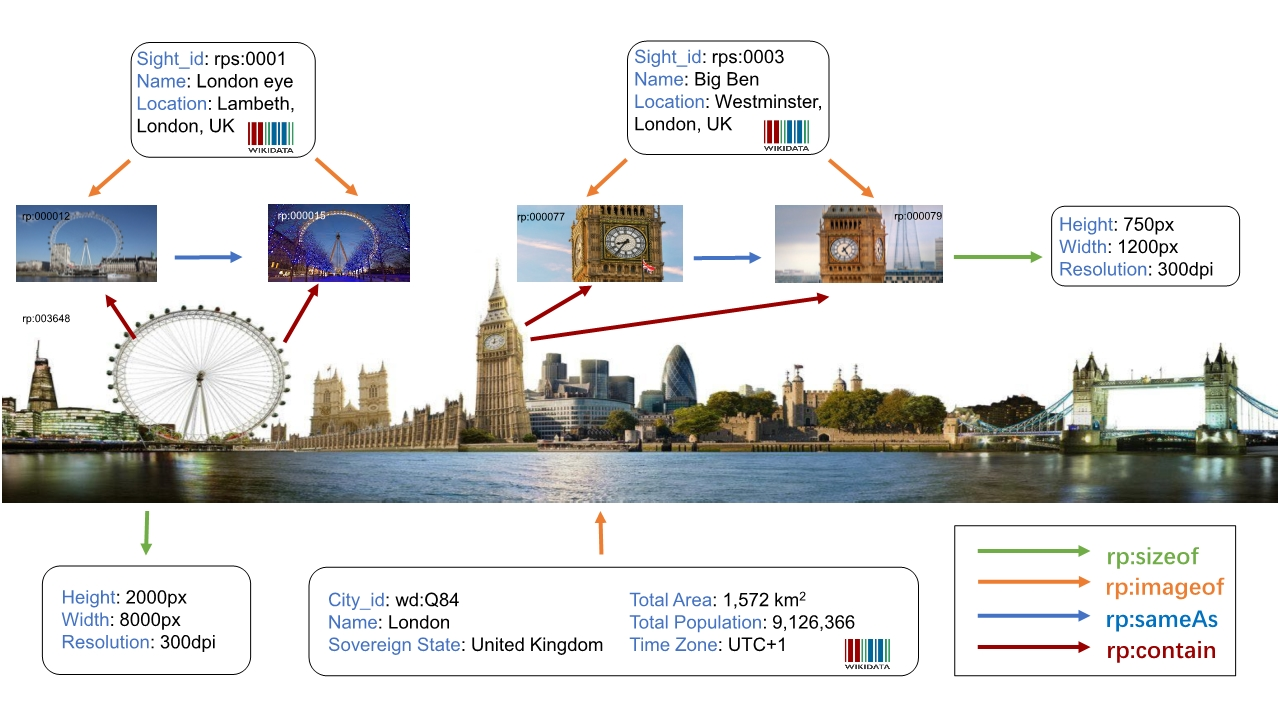
“据我们所知,我们是第一个为一般知识图提供全面的视觉相关资源的人。其结果是一个大型和高质量的多模态知识图数据集,它为研究人员从语义网和计算机视觉提供了更广泛的数据范围。
我们提出了构建多模式知识图的新框架。这个过程从分别从维基数据、维基百科和搜索引擎收集实体和图像开始。然后,图像由多样性检索模型进行筛选。最后,RDF 链接基于维基百科中的超链接和描述设置在图像实体之间。
我们将Richpedia发布为开放资源,并使用Apache Jena Fuseki提供分面查询端点。研究人员可以检索和利用分布在一般 KG 和图像资源上的数据来回答更丰富的视觉查询,并进行多关系链接预测。”
现有的工作重点是捕获多媒体文件的高级元数据(如作者、创建日期、文件大小、清晰度、持续时间),而不是多媒体内容本身的音频或视觉特性。
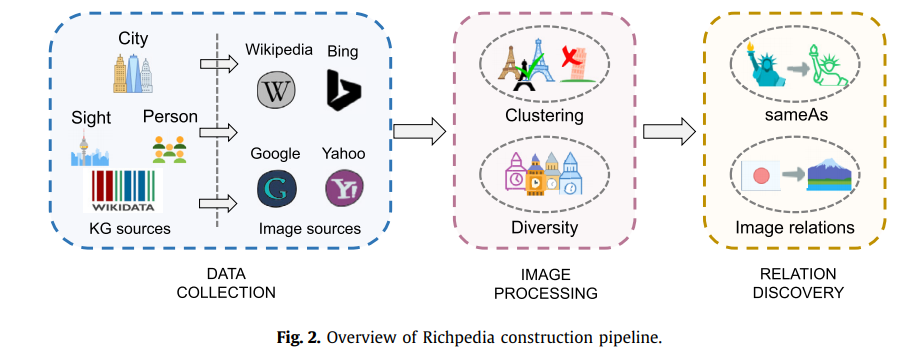
构建过程:将图像也视作一种实体。
- 基于现有的文本实体(现在只包含了城市、景点、人物),去四大引擎搜索图片。
- 对图片进行预处理,聚类(去噪)、去重(确保图像多样性)。
- 借助wikipedia图像描述中的超链接信息,设置规则提取实体间的相互关系,如’contain’,’nearby’等关系。
官网:http://rich.wangmengsd.com/#introduction
Github:https://github.com/wangmengsd/richpedia
其他的多模态知识图谱:DBpedia、Wikidata、IMGpedia、MMKG
4. 未来应用
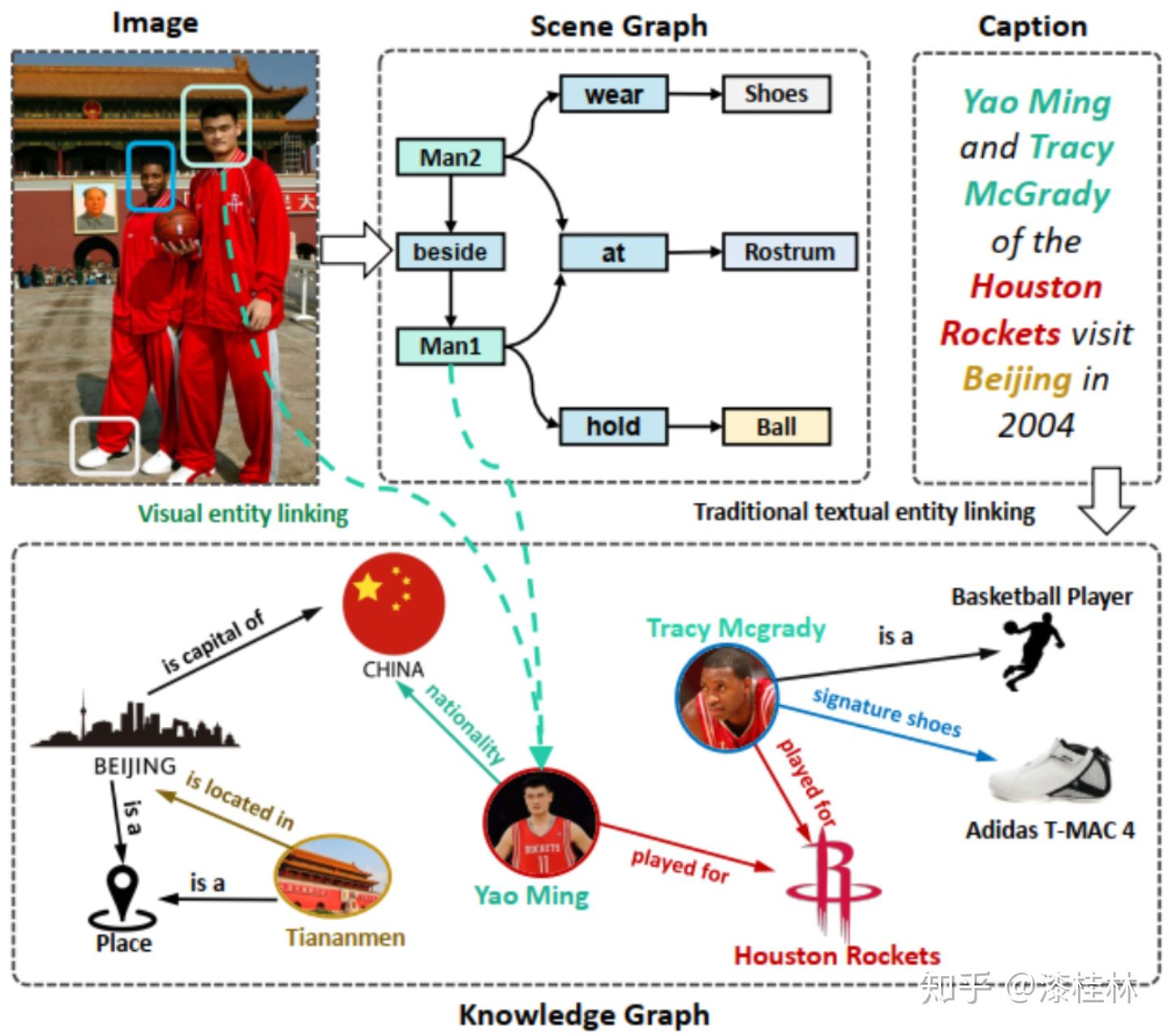
多模态知识图谱的应用场景十分广泛,首先一个完备的多模态知识图谱会极大地帮助现有自然语言处理和计算机视觉等领域的发展,同时对于跨领域的融合研究也会有极大的帮助,多模态结构数据虽然在底层表征上是异构的,但是相同实体的不同模态数据在高层语义上是统一的,所以多种模态数据的融合有利于推进语言表示等模型的发展,对于在语义层级构建多种模态下统一的语言表示模型提出数据支持。
其次多模态知识图谱技术可以服务于各种下游领域,例如多模态实体链接技术可以融合多种模态下的相同实体,可以广泛应用于新闻阅读,时事推荐,明星同款等场景中。多模态知识图谱补全技术可以通过远程监督补全多模态知识图谱,完善现有的多模态知识图谱,利用动态更新技术使其更加的完备。多模态对话系统的应用就更加的广泛,现阶段电商领域中集成图像和文本的多模态对话系统的研究蒸蒸日上,多模态对话系统对于电商推荐,商品问答领域的进步有着重大的推进作用。

若有收获,就点个赞吧
0 人点赞
