大数据、数据湖、数据仓库、数据存储、数据管理、数据分析、湖仓一体化
概念
维基百科上定义,数据湖(Data Lake)是一个以原始格式存储数据的存储库或系统。它按原样存储数据,而无需事先对数据进行结构化处理。一个数据湖可以存储结构化数据(如关系型数据库中的表),半结构化数据(如CSV、日志、XML、JSON),非结构化数据(如电子邮件、文档、PDF)和二进制数据(如图形、音频、视频)。
但是随着大数据技术的融合发展,数据湖不断演变,汇集了各种技术,包括数据仓库、实时和高速数据流技术、数据挖掘、深度学习、分布式存储和其他技术。逐渐发展成为一个可以存储所有结构化和非结构化任意规模数据,并可以运行不同类型的大数据工具,对数据进行大数据处理、实时分析和机器学习等操作的统一数据管理平台。
特征
功能
结合目前开源的数据湖平台和组件,总结数据湖的基本参考架构如下:
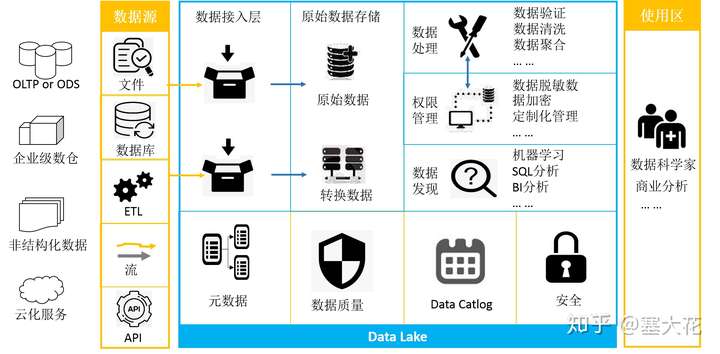
总结数据湖最核心的能力包括:
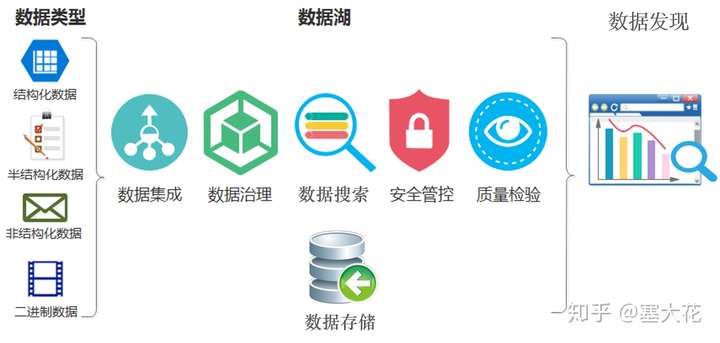
1、数据集成能力(数据接入)
1)接入不同数据源,包括数据库中的表(关系型或者非关系型)、各种格式的文件(csv、json、文档等)、数据流、ETL工具(Kafka、Logstash、DataX等)转换后的数据、应用API获取的数据(如日志等);
2)自动生成元数据信息,确保进入数据湖的数据都有元数据;
3)提供统一的接入方式,如统一的API或者接口;
2、数据存储
数据湖存储的数据量巨大且来源多样,数据湖应该支持异构和多样的存储,如HDFS、HBase、Hive等;
3、数据搜索
数据湖中拥有海量的数据,对于用户来说,明确知道数据湖中数据的位置,快速的查找到数据,是一个非常重要的功能。
4、数据治理
1)自动提取元数据信息,并统一存储;
2)对元数据进标签和分类,建立统一的数据目录;
3)建立数据血缘,梳理上下游的脉络关系,有助于数据问题定位分析、数据变更影响范围评估、数据价值评估;
4)跟踪数据时间旅行,提供不同版本的数据,便于进行数据回溯和分析;
5、数据质量
1)对于接入的数据质量管控,提供数据字段校验、数据完整性分析等功能;
2)监控数据处理任务,避免未执行完成任务生成不完备数据;
6、安全管控
1)对数据的使用权限进行监管;
2)对敏感数据进行脱敏和加密;
7、自助数据发现
提供一系列数据分析工具,便于用户对数据湖的数据进行自助数据发现,包括:
- 联合分析;
- 交互式大数据SQL分析;
- 机器学习;
- BI报表等
优势
- 轻松地收集和摄入数据:企业中的所有数据源都可以送入数据湖中。因此,数据湖成为了存储在企业内部服务器或云服务器中的结构化和非结构化数据的无缝访问点。通过数据分析工具可以轻松地获得整个无孤岛的数据集合。此外,数据湖可以用多种文件格式存储多种格式的数据,比如文本、音频、视频和图像。这种灵活性简化了旧有数据存储的集成。
- 支持实时数据源:数据湖支持对实时和高速数据流执行 ETL 功能,这有助于将来自 IoT 设备的传感器数据与其他数据源一起融合到数据湖中。
- 更快地准备数据:分析师和数据科学家不需要花时间直接访问多个来源,可以更轻松地搜索、查找和访问数据,这加速了数据准备和重用流程。数据湖还会跟踪和确认数据血统,这有助于确保数据值得信任,还会快速生成可用于数据驱动的决策的 BI。
- 更好的可扩展性和敏捷性:数据湖可以利用分布式文件系统来存储数据,因此具有很高的扩展能力。开源技术的使用还降低了存储成本。数据湖的结构没那么严格,因此天生具有更高的灵活性,从而提高了敏捷性。数据科学家可以在数据湖内创建沙箱来开发和测试新的分析模型。
- 具有人工智能的高级分析:访问原始数据,创建沙箱的能力,以及重新配置的灵活性,这些使得数据湖成为了一个快速开发和使用高级分析模型的强大平台。数据湖非常适合使用机器学习和深度学习来执行各种任务,比如数据挖掘和数据分析,以及提取非结构化数据。
问题
数据湖刚提出来时,只是一个朴素的理念。而从理念变成一个可以落地的系统,就面临着许多不得不考虑的现实问题:
首先,把所有原始数据都存储下来的想法,要基于一个前提,就是存储成本很低。而今数据产生的速度越来越快、产生的量越来越大的情况下,把所有原始数据,不分价值大小,都存储下来,这个成本在经济上能不能接受,可能需要打一个问号。
其次,数据湖中存放这各类最原始的明细数据,包括交易数据、用户数据等敏感数据,这些数据的安全怎么保证?用户访问的权限如何控制?
再次,湖中的数据怎么治理?谁对数据的质量、数据的定义、数据的变更负责?如何确保数据的定义、业务规则的一致性?
数据湖的理念很好,但是它现在还缺乏像数据仓库那样,有一整套方法论为基础,有一系列具有可操作性的工具和生态为支撑。正因如此,目前把Hadoop用来对特定的、高价值的数据进行处理,构建数据仓库的模式,取得了较多的成功;而用来落实数据湖理念的模式,遭遇了一系列的失败。这里,总结一些典型的数据湖失败的原因:
- 数据沼泽:当越来越多的数据接入到数据湖中,但是却没有有效的方法跟踪这些数据,数据沼泽就发生了。在这种失败中,人们把所有东西都放在HDFS中,期望以后可以发掘些什么,可没多久他们就忘那里有什么。
- 数据泥团:各种各样的新数据接入进数据湖中,它们的组织形式、质量都不一样。 由于缺乏用于检查,清理和重组数据的自助服务工具,使得这些数据很难创造价值。
- 缺乏自助分析工具:由于缺乏好用的自助分析工具,直接对数据湖中的数据分析很困难。一般都是数据工程师或开发人员创建一个整理后的小部分数据集,把这些数据集交付给更广泛的用户,以便他们使用熟悉的工具进行数据分析。这限制了更广泛的人参与到探索大数据中,降低了数据湖的价值。
- 缺乏建模的方法论和工具:在数据湖中,似乎每一项工作都得从头开始,因为以前的项目产生的数据几乎没有办法重用。 其实,我们骂数据仓库很难变化以适应新需求,这其中有个原因就是它花很多时间来对数据进行建模,而正是有了这些建模,使得数据可以共享和重用。数据湖也需要为数据建模,不然每次分析师都得从头开始。
- 缺少数据安全管理:通常的想法是每个人都可以访问所有数据,但这是行不通的。企业对自己的数据是有保护本能的,最终一定是需要数据安全管理的。
- 一个数据湖搞定一切:大家都对能在一个库中存储所有数据的想法很兴奋。然而,数据湖之外总会有新的存储库,很难把他们全都消灭掉。 其实,大多数公司所需的,是可以对多种存储库联合访问功能。是不是在一个地方存储,并不是那么重要。
应用
开源平台
- Delta Lake
Delta Lake是Databricks公司今年四月刚刚开源的一个项目。它基于自家的Spark,为数据湖提供支持ACID事务的数据存储层。主要功能包括:支持ACID事务、元数据处理、数据历史版本、Schema增强等。 - Kylo
Kylo是Teradata开源的一个全功能的数据湖平台。它基于Hadoop和Spark。提供一套完整的数据湖解决方案,包括数据集成、数据处理、元数据管理等功能。功能比较齐全。 - Dremio
Dremio是Dremio公司开源的一个DaaS平台。它主要基于Apache Arrow,提供基于Arrow的执行引擎,使得数据分析师可以对多种数据源的数据进行联合分析。
除此之外,还有一些商业的数据湖平台,比如zaloni。另外,各大云厂商也都提供了数据湖平台或数据湖分析服务,比如Azure、Amazon、阿里云等。
应用实例
- 政务信息化—基于数据湖架构的时空大数据与云平台解决方案

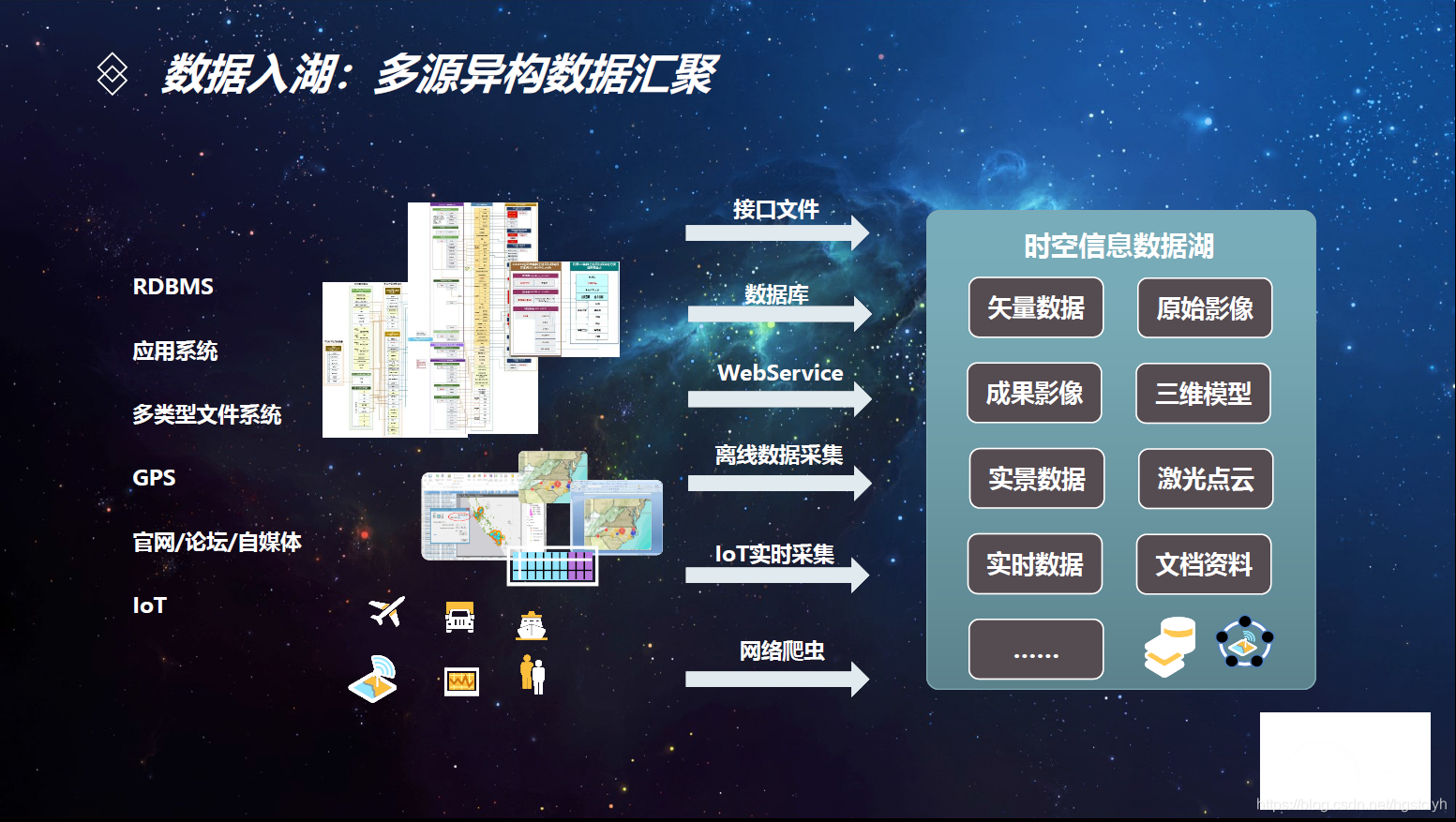

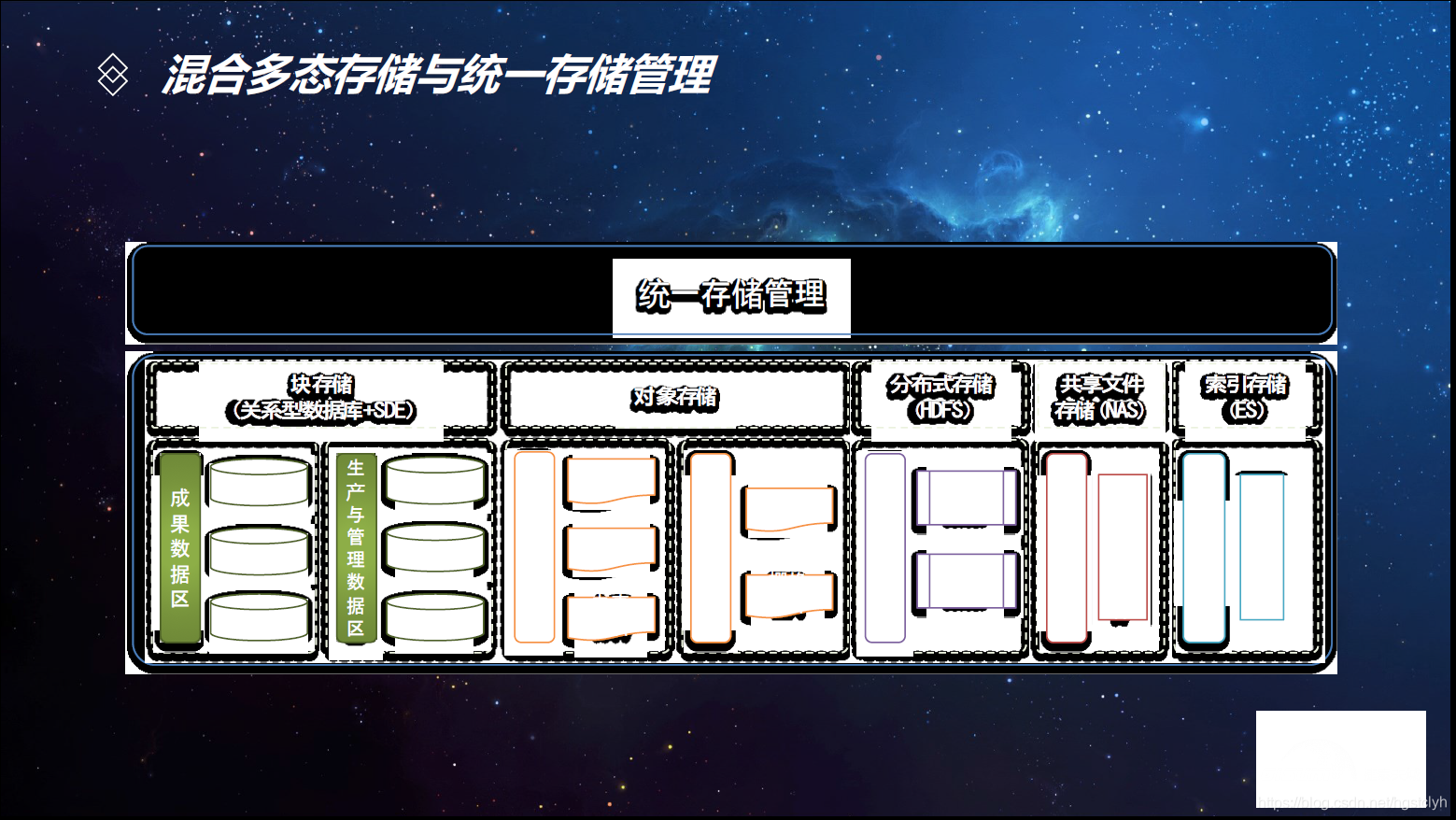

与数据仓库的区别
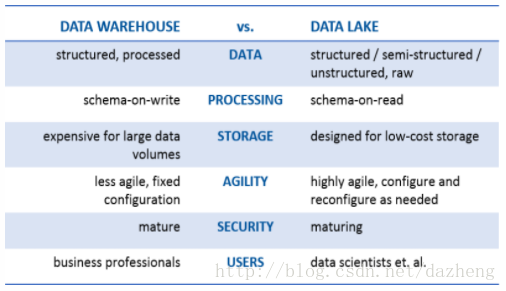
数据仓库是一种具有正式架构的成熟的、安全的技术。它们存储经过全面处理的结构化数据,以便完成数据治理流程。数据仓库将数据组合为一种聚合、摘要形式,以在企业范围内使用,并在执行数据写入操作时写入元数据和模式定义。数据仓库通常拥有固定的配置;它们是高度结构化的,因此不太灵活和敏捷。数据仓库成本与在存储前处理所有数据相关,而且大容量存储的费用相对较高。
相较而言,数据湖是较新的技术,拥有不断演变的架构。数据湖存储任何形式(包括结构化和非结构化)和任何格式(包括文本、音频、视频和图像)的原始数据。根据定义,数据湖不会接受数据治理,但专家们都认为良好的数据管理对预防数据湖转变为数据沼泽不可或缺。数据湖在数据读取期间创建模式。与数据仓库相比,数据湖缺乏结构性,而且更灵活;它们还提供了更高的敏捷性。在检索数据之前无需执行任何处理,而且数据湖特意使用了便宜的存储。
1)数仓中保存的都是结构化处理后的数据,而数据湖中可以保存原始数据也可以保存结构化处理后的数据,保证用户能获取到各个阶段的数据。因为数据的价值跟不同的业务和用户强相关,有可能对于A用户没有意义的数据,但是对于B用户来说意义巨大,所以都需要保存在数据湖中。
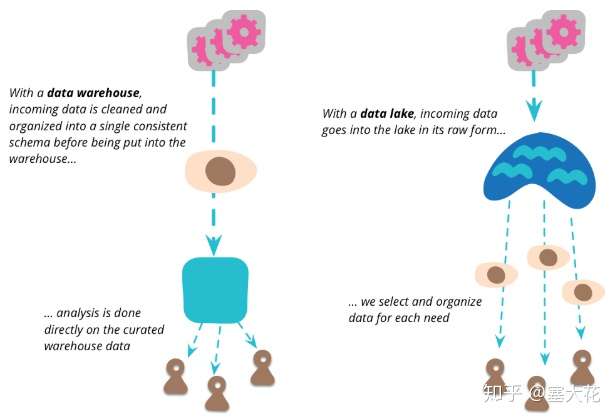
2)数据湖能够支持各种用户使用,包括数据科学家这类专业的数据人员。
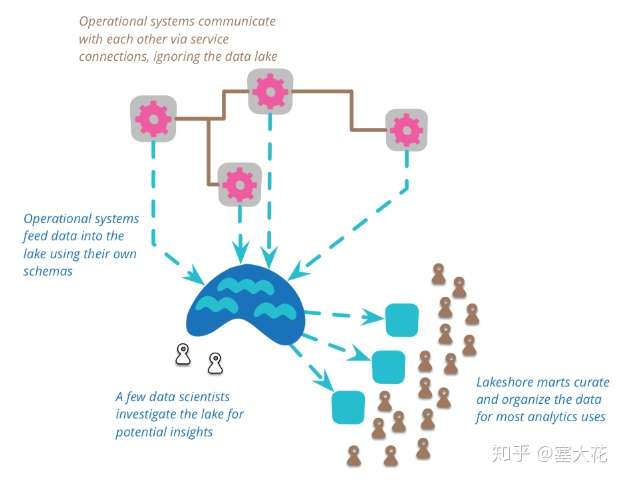
湖仓一体 (Lake House)
概念
Lake House,坊间通常称之为“湖仓一体”,而Amazon Web Services则叫做“智能湖仓”。 Lake House架构最重要的一点,是实现“湖里”和“仓里”的数据/元数据能够无缝打通,并且“自由”流动。 湖里的“新鲜”数据可以流到仓里,甚至可以直接被数仓使用,而仓里的“不新鲜”数据,也可以流到湖里,低成本长久保存,供未来的数据挖掘使用。必要性
那么湖仓割裂的状态会带来什么问题呢?为什么今天大家开始讨论湖仓一体化了。以机器学习在推荐业务的应用为例说明。 以视频推荐的场景为例: 大家知道一个完整的推荐系统,需要做大量的用户行为日志分析以及待推荐对象的特征提取工作。行为日志分析是一个经典的数仓操作,需要对用户的历史数据做大量的结构化处理,并且通过ETL加工特征。 另外因为被推荐对象是视频,是典型的非结构化数据,需要做一些图像和语意相关的解析,这些操作是无法通过数仓完成的,需要借助数据湖来实现存储,再由算法脚本提取图像和文本特征。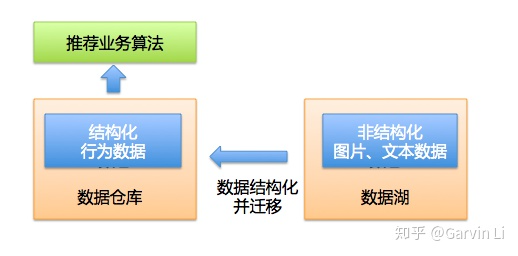
湖仓一体下多模态的机器学习业务
语音、文本、视觉相结合的解决方案在人工智能领域叫做多模态方案。在湖仓一体化的背景下,可以支持机器学习的数据以多种结构态存储并使用,所以我起了个名字,湖仓一体化可解决“数据多结构态”的问题。 在湖仓一体化的背景下,未来机器学习业务可以更多的去探索不同结构态数据间的建模打通工作。可以轻而易举的在一次模型训练中,即应用图像、语音、文本数据,也应用到数仓结果数据。这样无疑是对偏上层的机器学习业务的一种推动。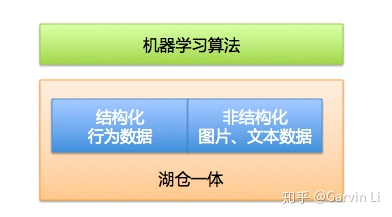
历史尝试
在数据湖阵营,早在2011年,Hadoop开源体系公司Hortonworks开始了Apache Atlas和Ranger两个开源项目的开发,分别对应数据追踪和数据权限安全两个数仓核心能力。这可以看做是数据湖向数据仓库做出的融合尝试。 遗憾的是,这两个开源项目的活跃度一直不高,直到2017年才完成孵化,且发布周期较慢,相较同时期的Spark、Flink等开源项目完全不可同日而语,几乎被人淡忘。 在数据仓库阵营,2017年AWS Redshift推出RedshiftSpectrum,支持Redsift数仓用户访问S3数据湖的数据。开始在AWS产品体系内,尝试打通数据仓库到数据湖统一存储的边界;同时,2018年阿里云MaxCompute推出外表能力,支持访问包括OSS/OTS/RDS数据库在内的多种外部存储。实现阿里云产品体系内数仓产品到数据湖统一存储的打通。 这两次数据仓库与数据湖融合做的尝试,但因为这类数仓到数据湖的打通仍然停留在各自的技术体系内,而且是从存储层进行打通,上层元数据仍然要在数仓中人工重建,易用性较差,只适用于低频查询。所以,也没有在业界引起广泛的关注。 2020年1月9日,在微博首次在测试当中完成了湖和仓的数据和元数据打通。到2020年4月,湖仓一体在微博生产系统正式应用,PAI深度学习和机器学习训练任务以及各种数据处理任务通过湖仓一体技术,实现在MaxCompute和EMR之间的无缝调度,真正在两套体系之上实现了统一的元数据管理和数据开发体验。 从此,微博摆脱繁重的数据搬迁,极大的提升平台化服务能力,使微博数据湖中的数据和算法工程师能够轻松无缝的借助阿里巴巴成熟的超大规模计算能力和算法赋能业务提效,并且实现MaxCompute云数仓加数据湖的闭环,极大的提升AI类作业的效率,将数据湖的灵活性和云数仓的性能成本,云原生优势充分结合,形成互补,从而达到成本节约。参考
[1] https://zhuanlan.zhihu.com/p/87795611
[2] https://blog.csdn.net/dazheng/article/details/73499510
[3] https://www.jianshu.com/p/dc510ec49f53
[4] https://blog.csdn.net/hgstclyh/article/details/114209452
[6] https://www.sohu.com/a/419664531_116326
[7] https://zhuanlan.zhihu.com/p/255236251
[8] https://baijiahao.baidu.com/s?id=1701919462106140639&wfr=spider&for=pc

若有收获,就点个赞吧
0 人点赞
