大数据、数据挖掘、数据分析、数据管理、自然语言处理、神经网络、深度学习、知识管理、网页爬取、网页净化、信息提取、核心概念提取、因果知识提取
1 网页净化
1.1 基于文档树的网页净化
HTML是一个标识语言(Markup Language),它定义了一套标签来刻画网页显示时的页面布局和视觉效果。因此,对于 HTM 网页最常用的结构表示方法是构造网页的标签树。现有的标签树构造工具很多,文档树(DOM Tree)是一个常用标签树构造工具,它可以将网页中的标签按照嵌套关系整理成一棵树状结构。
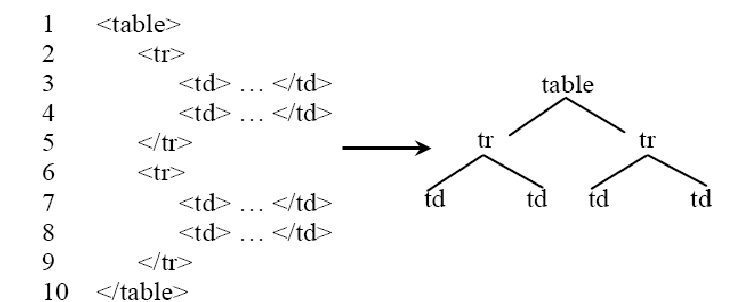
1.2 基于视觉的网页净化
基于视觉识别的网页净化方法利用了字体的大小,布局信息,背景颜色等一些视觉信息,根据一定的规则将页面划分成视觉块。这种方法很好的模拟了人们观察网页的习惯。当人去观察一个网页的时候,他会很轻易的找到网页的正文,因为正文比较突出,比较醒目,并且在网页的正中间,所以可以很轻松的找到。不过,由于视觉特征的复杂性,运用的启发知识往往较为模糊,需要人工不断地总结调整规则。
1.3 基于HTML标签的网页净化
这种方法是利用 HTML 标记(Tag)将网页进行分块,然后根据网页正文块所具有的一些特征来识别。
2 核心概念提取
2.1 概念注释
概念注释模块负责从学习资源文本中提取概念,通过输入文本再返回一组结构化的统一资源标志符(Uniform Resource Identifier, URI),即搜寻文本中的概念并于知识库中的概念联系起来,但不会对所选的注释进行其他验证,因为无法保证自动获得的注释的正确性,这里需要进行手动校正。
2.2 概念扩展
扩展模块用于丰富未在文本中明确提及或者未被注释服务识别的概念.我们将注释集(即文本中的概念)扩展为新的概念集,主要使用以下两种不同的方法:1. 基 于 类 别 的 扩 展 (Category- based Expansion,CBE):此类扩展针对语义表征内的每个注释类别(或知识图谱中关于概念的其他分层信息).2. 基 于 属 性 的 扩 展 (Property- based Expansion,PBE):此类扩展针对语义表征内的每个注释属性,通过遍历某些属性找到的概念来丰富知识图谱.
2.3 概念加权
该模块是学习资源核心概念识别的关键.具有最高权重的概念被认为是核心概念.相比之下,具有最低权重的概念可以被视为表征中的噪声.与学习资源主题无关的概念往往在文档中不常见或在表征中显示为弱连接(即与其它概念很少或没有联系).这种无关的概念具有低权重,因此不会被视为核心概念。影响权重的特征包括:概念的频率、是否为扩展概念、PageRank、关联概念的数量等。
半结构化抽取逻辑图

参考
[1] 何恒昌. Web挖掘中信息采集技术研究与实现[D].北京物资学院,2010.
[2] 赵嫦花,米春桥,匡进鹃,李晓梅.基于知识图谱的学习资源核心概念提取策略分析[J].怀化学院学报,2020,39(05):117-121.
[3] 李悦群,毛文吉,王飞跃.面向领域开源文本的因果知识提取[J].计算机工程与科学,2010,32(05):100-104.
[4] 潘璇,蔡祥睿,温延龙,袁晓洁.基于深度学习的数据库自然语言接口综述[J/OL].计算机研究与发展:1-30[2021-04-18].http://kns.cnki.net/kcms/detail/11.1777.TP.20210301.1423.002.html.

若有收获,就点个赞吧
0 人点赞
