- 一、解决的问题">一、解决的问题
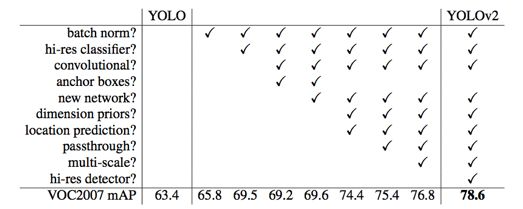
- 三、YOLOv2改进">三、YOLOv2改进
- 1)批规范化(Batch Normalization)">1)批规范化(Batch Normalization)
- 2)高分辨率分类器(High Resolution Classifier)">2)高分辨率分类器(High Resolution Classifier)
- 3)使用Anchor Box">3)使用Anchor Box
- 4)通过K-means来学习出anchor box">4)通过K-means来学习出anchor box
- 5)定向位置预测(Directed Location Prediction)">5)定向位置预测(Directed Location Prediction)
- 6)细分类特征(Fine-Grained Features)">6)细分类特征(Fine-Grained Features)
- 7)多尺寸训练(Multi-ScaleTraining)">7)多尺寸训练(Multi-ScaleTraining)
- 四、Faster">四、Faster
- 六、结果">六、结果
目标检测,卷积,YOLO
recall value是查全率(r),查全率是被正确分类的正例数量除以测试集中实际的正例数量。
相应的还有查准率(precision)。查准率(p)是被正确分类的正例数量除以分类为正例的数量。
一、解决的问题
目标检测一直是机器视觉领域的一个热点,RCNN、fast RCNN、faster RCNN、SSD等杰出的方法层出不穷。但是这些目标检测方法都受限于数据集只能检测较小的物体种类(20种)。由于目标检测数据集的标定比物体识别的数据集的标定要昂贵的多,因此想要获得想ImageNet这种级别的目标检测数据集是几乎不可能完成的任务。如何训练出能识别出许多种物体的目标检测模型就显得极为诱人。本文作者提出了一种**联合训练**的方法将目标检测数据集与分类数据集结合,使得YOLOv2网络能够识别9000种物体,升级为YOLO9000。 # 二、YOLO结构 如图所示,YOLO实现了一个目标检测领域的端对端模型。通过一个大的loss function将bounding box检测和物体识别同时训练,使用不同的$ \lambda $来调整的权重。
如图所示,YOLO实现了一个目标检测领域的端对端模型。通过一个大的loss function将bounding box检测和物体识别同时训练,使用不同的$ \lambda $来调整的权重。
三、YOLOv2改进
1)批规范化(Batch Normalization)
Batch Normalization的作用是提高了网络模型的鲁棒性,缓解了Covariant Shift问题,有一定的正则化(regularization)作用,在这里也不例外。通过在YOLO所有的卷积层中加入Batch Normalization,可以使得mAP提高2%,并且dropout的部分也可以丢掉。2)高分辨率分类器(High Resolution Classifier)
从AlexNet开始,大多数的分类器都在分辨率小于256*256的图像上执行分类。YOLO一代在训练分类网络的时候用的是224224分辨率,检测网络的时候用的是448448分辨率,这就意味着网络需要同时切换到目标检测并且适应新的分辨率。在YOLO二代中,直接使用448*448的分辨率微调(fine tune)了网络,训练了10个epoch。可以使得mAP提高大概4%。3)使用Anchor Box
YOLO使用全连接层来预预测检测框的坐标和长宽。与faster RCNN相比,YOLO只能预测98个框,数量太少,在检测数量较多的物体比如人群,鸭群等的时候误差较大。并且faster RCNN网络预测的是检测框的偏移度(offset),可以简化问题并且使得网络能更容易地学习。因此YOLOv2将全连接层移除,引入了anchor box。并且将网络输入从448调整为416,这是为了使经过卷积层下采样(downsample)以后,能得到唯一的中心点(416/32=13)。因此输入为13*13的feature maps。
在未使用anchor box的情况下,模型的recall为81%,mAP为69.5,使用anchor box的情况下,模型的recall为88%,mAP为69.2。尽管mAP略有降低,但是recall得到了较大的提升。在加入anchor box思想之后,在训练集中,我们将每个anchor box视为一个训练样本。因此,为了训练目标模型,需要标记每个anchor box的标签,从而解决每张图只能识别一类物体的问题。
4)通过K-means来学习出anchor box
faster RCNN中,anchor box是手动选择的,作者想找出一个更好的anchor box来训练网络,因此作者使用了K-means聚类用于得到更好的anchor box。K-means主要用与预测anchor box的长跟宽。 在这里,如果K-means聚类采用的事欧氏距离的话,那么尺寸大的box比尺寸小的box对error的影响更大,所以作者提出了使用IOU , (Intersection over Union, 交集/并集)来度量距离: d(box, centroids) = 1 – IOU(box, centroids) 聚类结果如图,下图代表Avg IOU与聚类数目K的关系,在权衡Avg IOU和模型复杂度以后,作者选择了K=5。右图代表了VOC和COCO数据集的box的聚类结果。可以看出聚类所得到的anchor box与手动选择相比,更倾向于选择高瘦的anchor box。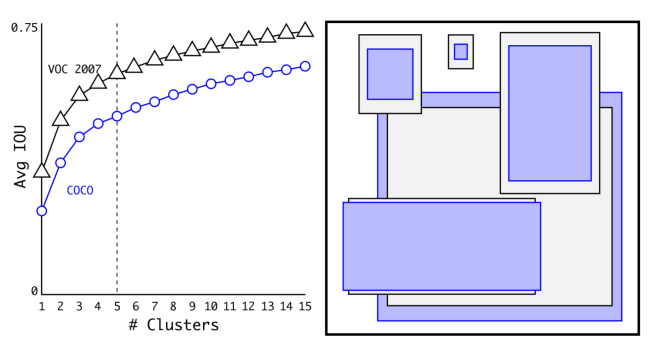
5)定向位置预测(Directed Location Prediction)
用Anchor Box的方法,会让model变得不稳定,尤其是在最开始的几次迭代的时候。而不稳定的因素主要来自于预测bounding box坐标(x, y)的时候。YOLOv2与YOLO网络相似,预测的是(x, y)的坐标值而非偏移量。并且作者通过sigmoid函数将偏移量限制在0到1之间,如图所示,这种限制使得predict box的跳跃被限制在以$ (c_x,c_y),(c_x+1,c_y+1) $为对角线的网格中。
使用Directed Location Prediction为YOLO网络带来了5%的提升。
6)细分类特征(Fine-Grained Features)
Faster F-CNN、SSD都使用不同尺寸的Feature Map来取得不同范围的分辨率,而YOLOv2采取了不同的方法,YOLOv2加上了一个跳跃层(Passthrough Layer)来获取之前的26*26分辨率的层的特征。这个Passthrough layer能够把高分辨率特征与低分辨率特征连结(concatenate)起来,这种方式看起来与ResNet很像,但是略有不同,因为ResNet采用的是summation,而YOLOv2的Fine-Grained Features采用的是concatenate。 Fine-Grained Features这提升了YOLO 1%的性能。7)多尺寸训练(Multi-ScaleTraining)
作者希望YOLO v2能鲁棒地运行于不同尺寸的图片之上,所以把这一想法用于训练model中。 区别于之前的补全图片尺寸的方法,YOLO v2每迭代几次都会改变网络参数。每10个Batch,网络会随机地选择一个新的图片尺寸,由于使用了下采样参数是32,所以不同的尺寸大小也选择为32的倍数{320,352…..608},最小320320,最大608608,网络会自动改变尺寸,并继续训练的过程。 这一方法使得网络在输入图片尺寸比较小的时候跑的比较快,输入图片尺寸比较大的时候精度高,下图为YOLOv2和其他的目标检测网络的对比。四、Faster
YOLO使用的是GoogleNet架构,比VGG-16快,YOLO完成一次前向过程只用8.52 billion 运算,而VGG-16要30.69billion,但是YOLO精度稍低于VGG-16。因此作者在YOLOv2中设计了一种新的网络结构叫Darknet-19。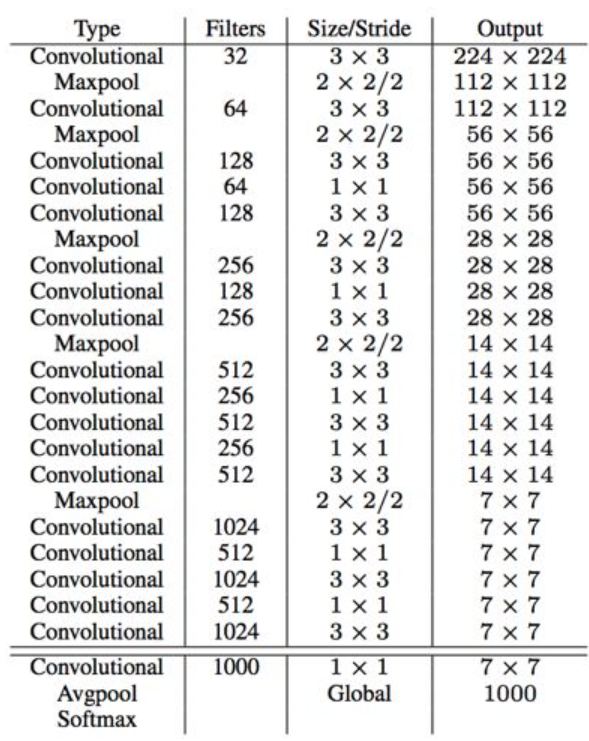
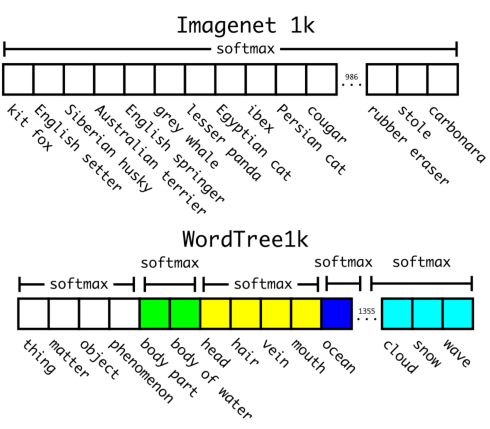
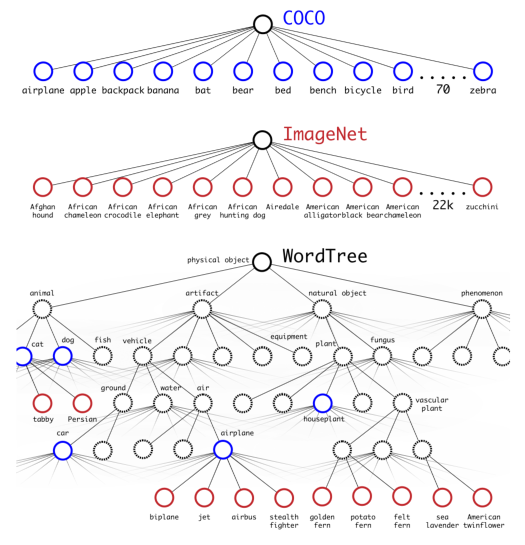
3)在使用WordTree混合了COCO与ImageNet数据集后,混合数据集对应的WordTree包含9418类。由于ImageNet数据集跟COCO比太大了,产生了样本倾斜的问题,因此作者将COCO过采样,使得COCO与ImageNet的比例为1: 4。使用联合训练法,YOLO9000可以从COCO数据集中学习检测图片中物体的位置,从ImageNet中学习物体的分类。
六、结果
1)评估YOLOv2——PASCAL VOC2007 & COCO
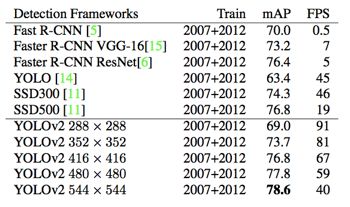
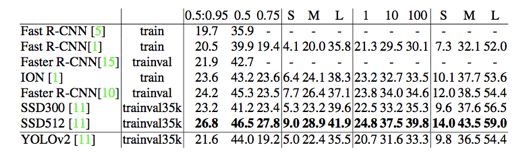
2)评估YOLO-9000——ImageNet Detection Task
评估结果: YOLO9000整体的mAP为19.7。 在未学习过的156个分类数据上进行测试,mAP为16.0。YOLO9000的mAP比DPM(一个目标检测算法)高,而且YOLO9000是使用部分监督的方式在不同训练集上进行训练,能实时检测9000种物体。
虽然YOLO9000对动物的识别性能很好,但是对类别为”sunglasses“或者”swimming trunks“这些衣服或者装备的类别,它的识别性能不是很好。这跟目标检测数据集中只考虑“人”这个整体有很大关系。

若有收获,就点个赞吧
0 人点赞
