统计学;数据分析;机器学习;因果模型 ;非混淆假设 ;反事实 ;SCM ;潜在输出模型
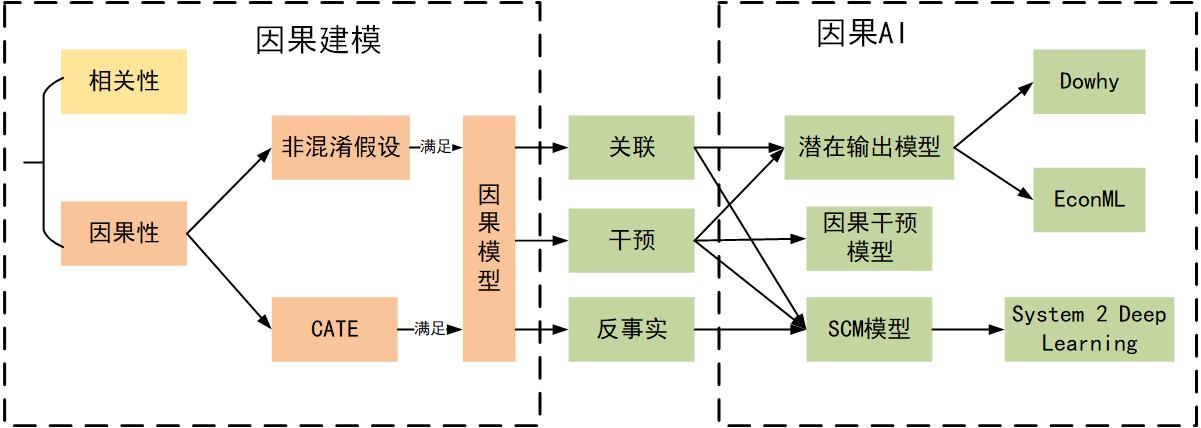
什么是因果性
- 事件/变量之间的关系,最主要的有相关性和因果性。
- 相关性是指在观测到的数据分布中,X与Y相关,如果我们观测到X的分布,就可以推断出Y的分布;
- 因果性是指在操作/改变X后,Y随着这种操作/改变也变化,则说明X是Y的因;
- 在常用的机器学习算法中,关注的是特征之间的相关性,而无法去识别特征之间的因果性,而很多时候在做决策与判断的时候,我们需要的是因果性。
为什么需要因果AI
因果革命和以数据为中心的第一次数据科学革命,也就是大数据革命(涉及机器学习,深度学习机器应用,例如 Alpha-Go、语音识别、机器翻译、自动驾驶等等 )的不同之处在于,它以科学为中心,涉及从数据到政策、可解释性、机制的泛化,再到一些社会科学中的基础概念信用、责备和公平性,甚至哲学中的创造性和自由意志。
因果AI应用场景
科研人员想衡量一种新的降血压药对病人的效果,发现服药的患者有些血压降低但有些血压升高。于是问题可以抽象成我们希望预测降压药会对哪些病人有效?相似的问题经常出现在经济,政治决策,医疗研究以及当下的互联网<font style="color:#000000;">AB</font><font style="color:#000000;">测试中</font>. 例如哪些人对优惠券更加敏感 ? 例如uber 通过算法来决定给哪些人发优惠券, 以提高他们在平台的留存率。
相关概念
反事实
因果推断的核心思想在于反事实推理 (counterfactual reasoning),即在我们观测到X和Y的情况下,推理如果当时没有做X,Y'是什么。
非混淆假设
当混杂变量(confounding variable)与观察变量独立,因果关系(Causal Effect)被描述为:
$ \tau_i=Y_i(1)-Y_i(0) $
CATE
CATE (Conditional Averaged Treatment Effect) 是指对于每个人实施 Treat 和 不实施 Treat 比, 会产生的Effect.
$ \tau(x)=E[Y_i(1)-Y_i(0)|X_i=x] $
其中$ Y_i(1) $表示此个体施加了 Treat 的组平均输出. $ Y_i(0) $则表示未施加 Treat 的组的平均输出。因果推理目前主要集中在如何估计 CATE, 由于<font style="color:red;">不可能同时观察到对于一个个体施加与不施加</font><font style="color:red;"> Treat </font><font style="color:red;">的结果</font>, 这个任务和传统的预测任务所采用的方法有较大的区别。
三层式因果模型层级
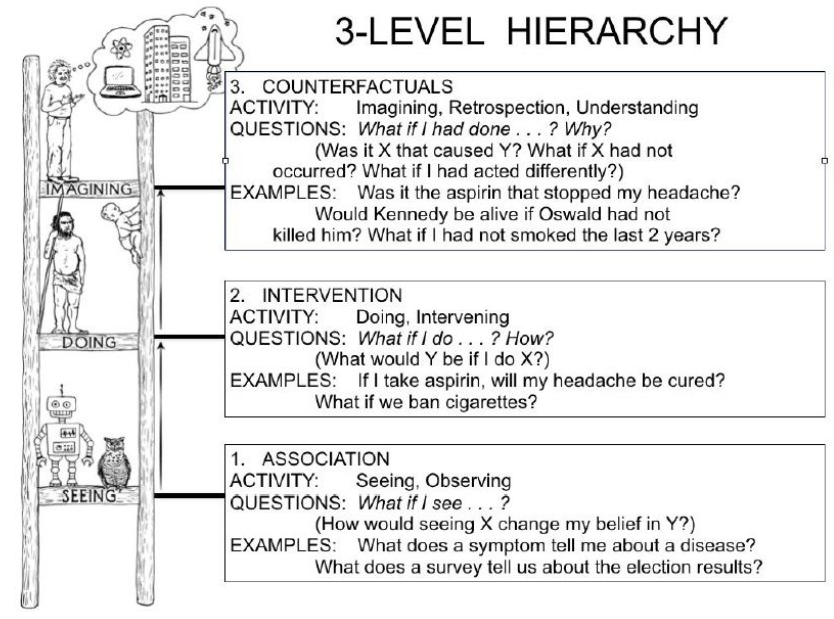
第一层被叫作关联(Association),它涉及由裸数据定义的纯统计关系。大多数机器学习系统运行在这一层上。
第二层被叫作干预(Intervention),不仅涉及到能看到什么,还涉及你可能采取的行动(干预措施)有哪些影响。我认为增强学习系统是运行在这个层上(例如,“如果我把骑士移到这个方格会怎样?”)。增强学习系统倾向于在定义良好的环境中运行,而干预层也包含了更多的开放性挑战。作为例子,Pearl 提了一个问题:“如果我们将价格翻倍,将会发生什么?”
第三层被称为反事实(Counterfactual),解决的是“如果……会怎样”问题。当规模很小时,序列到序列生成模型就能够解决问题。我们可以“重放”序列的开头,修改下一个数据值,然后查看输出会发生什么变化。
这些层构成了层次结构,介入性问题无法从纯粹的观察性信息中得到回答,而反事实性问题无法从纯粹的介入性信息中得到回答(例如,我们无法对已经接受了药物的受试者重新进行实验,以便知道如果不为受试者提供药物会怎样)。在层级 j 回答问题的能力意味着我们也可以回答层级 i(<=j)的问题。
这种层次结构及其所包含的形式限制解释了为什么基于关联的机器学习系统无法推理动作、实验和因果解释。
因果推理模型
因果模型(干预)
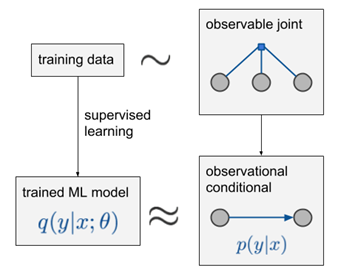
干预定义
观察$ \color{red}{p(y|x)} $:从$ p(x,y,z,\cdots) $中计算出它的两个边缘概率:$ p(y|x)=p(x,y)/p(x) $,其中$ x,y $是自然发生的。
介入$ \color{red}{p(y|do(x))} $:通过人为把X的值设为x来干预数据生成过程,但其余变量还是用原先的生成方式,以此观察Y的变化(请注意,数据生成过程与联合分布$ p(x,y,z,\cdots) $不同)。
问题定义
根据$ p(y|x) $如何生成$ p(y|do(x)) $
模型结构
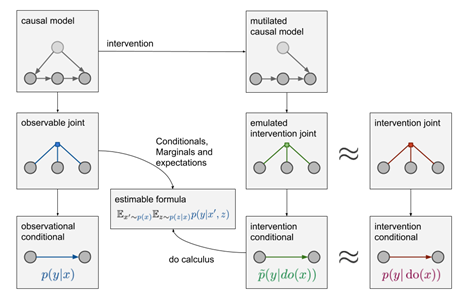
结构因果模型(SCM)
结合了图形建模、结构方程、反事实和介入逻辑。SCM“推理引擎”通常将假设(以图形模型的形式)、数据和查询作为输入。我们可以使用这些工具正式表达因果问题,以图解和代数形式编纂我们现有的知识,然后利用数据来估计答案。此外,当现有知识状态或现有数据不足以回答我们的问题时,这个理论会警告我们,然后建议其他知识或数据来源,让问题变得可回答。
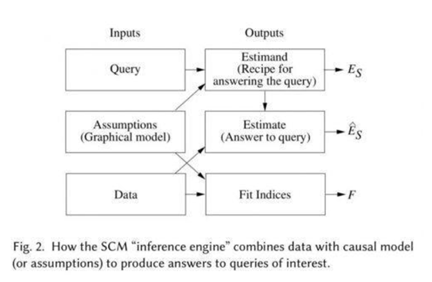
输入:查询 (Query) 、假设(以图形模型的形式)、数据
输出:
- 估计式(Estimand) 是关注的查询(Query)的某个概率表达式,表示在已有模型假定下计算 Query 的一种方法(干预 do-calculus);
- Estimate 是用某种统计方法和已有数据对 Estimand 概率表达式的估计 (结构方程);
- 一组拟合指标(Fit Indices)用于衡量数据与假设的兼容程度。
如果已有模型假定下某 Query 无法回答,也就是没有对应的 Estimand,则称该 Query 为“不可识别”,do-calculus 就是判断 Query 是否可识别的一个完备的演算工具。回答因果问题需要因果信息,当前存在多个回答因果问题的模型框架,但是回答反事实问题一般需要 Pearl 的结构因果模型(SCM),结构因果模型(SCM)由三个部分组成:图模型,结构方程以及反事实和干预逻辑。图模型是一种表示因果知识的语言,反事实和干预逻辑帮助他们阐明他们想知道的事情,结构方程将两者以扎实的语义联系在一起。
潜在输出模型 (Potential Outcome Framework)
假设一个药物治疗效果观测场景
当满足以下条件:
1、Stable Unit Treatment Value Assumption (SUTVA)
一是目标对象的独立性,即上述例子中一个病人的outcome不会影响另一个病人;二是treatment level的唯一性,比如指定剂量的药物A是唯一确定的。
2、Ignorability ( unconfoundedness assumption 混淆假设)
给定pre-treatment变量后,treatment变量与potential outcome变量是相互独立的,即不会有除了pre-treatment变量外的confounder。
3、Positivity
对于任何的pre-treatment变量,treatment assignment都是不确定性的
基于上述假设,观察到的输出 (observed outcome) 和潜在输出 (potential outcome) 的关系可以被如下表示
$ E[Y(W=w)|X=x]=EY(W=w)|W=w,X=x=E[Y^F|W=w,X=x] $
其中,$ Y^F $是观察输出的随机变量,$ Y(W=w) $是治疗变量为w的潜在输出的随机变量。
小结
结构因果模型(SCM)是 AI 领域中用得更多的因果建模框架,那么它和当前统计和社会学科中非常流行的 Pontential Outcome 框架有什么关系呢?
- 关于因果的理解有些区别,SCM是干预主义因果,用函数来表示因果关系;潜在输出模型通常关注吃药或者不吃药的对比,也被称为实验主义因果。
- SCM 是回答反事实问题的框架,而潜在输出模型一般回答干预层的问题。
- 反事实基本定律将SCM和潜在输出模型联系起来。
上述因果推理模型的几类工具:
1 do-calculus 和混淆控制(干预)
这里的混淆是指潜在变量的存在,潜在变量是两个或多个已观察到的变量的未知成因。
- 反事实
现代因果关系研究的最大成就之一就是通过图形表示形式化反事实推理。每个结构方程模型都确定了每个反事实句子的真实性。因此,如果句子的概率是从实验或观察研究或二者的组合估计出来的,那么我们就可以基于分析做出决策。
- 调解分析
调解分析涉及发现中间机制,通过这些中间机制可以将原因传给结果。我们可以发起诸如“X 对 Y 的影响的哪些部分是由变量 Z 调节的”之类的查询。
- 适应性、外部有效性和样本选择偏差
健壮性问题需要环境的因果模型,并且不能在 Association 层面处理,do-calculus 提供了一种完整的方法用于克服由于环境变化而引起的偏差。它既可用于重新调整学习策略以规避环境变化,也可用于控制由非代表性样本引起的偏差。
- 从不完整的数据中恢复
通过使用 SCM 因果模型,我们有可能对条件进行正规化。在这些条件下,可以从不完整的数据中恢复因果关系和概率关系,并且只要满足条件,就可以为所需关系生成一致的估计。
- 因果发现
检测并列举给定模型的可测试含义,推断出与数据兼容的模型集。还有一些方法用于发现因果方向性。
拓展模型
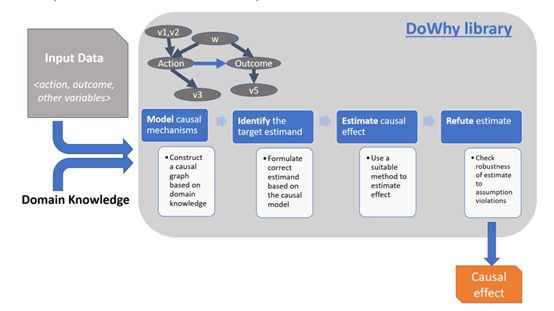
微软:Dowhy软件库:建模、识别、估计和反驳
- 画因果图,把假设写下来。
- 提供了很多受欢迎的因果推理模型的接口。
- 检验假设的健壮性,甚至如果这个假设不成立会怎么样。
https://causalinference.gitlab.io/kdd-tutorial/
https://github.com/Microsoft/dowhy
微软:EconML软件库
https://github.com/Microsoft/EconML
https://econml.azurewebsites.net/
https://www.microsoft.com/en-us/research/project/econml/#!use-cases
System 2 Deep Learning
目标为人类水平智能的范式,将因果推理能力的内容作为其核心组件。指出人的认知系统包含两个子系统:System1是直觉系统,主要负责快速、无意识、非语言的认知,这是目前深度学习主要做的事情;System2是逻辑分析系统,是有意识的、带逻辑、规划、推理以及可以语言表达的系统,这是未来深度学习需要着重考虑的。

参考文献
https://drive.google.com/file/d/1UT118pX3DzePaEEwj1tlaznqwHICSzhG/view
The Book of Why: The New Science of Cause and Effect (English Edition) 2018 Judea Pearl,Dana Mackenzie
Ferenc ML beyond Curve Fitting: An Intro to Causal Inference and do-Calculus
Introduction to Judea Pearl’s Do-Calculus 2013, Robert R. Tucci

若有收获,就点个赞吧
0 人点赞
