人工智能 强化学习 深度学习 自我博弈 蒙特卡罗方法 动作编码 分布式 ICML
AI斗地主的主要难点
- 非完美信息博弈:无法看到其他玩家的手牌,因此不能知道牌局的全部信息
——对比围棋:是完美信息博弈,双方均可看到整个棋盘 - 运气成分较大:一手好牌和一手坏牌对胜负影响很大
——对比围棋:棋子无好坏之分 - 合作竞争并存:两个农民要配合战胜地主,此前鲜有研究工作同时考虑博弈中的合作与竞争
——对比围棋:只有两位玩家,是竞争关系 - 庞大而复杂的牌型:单张、对子、三带一、四带二、顺子、炸弹
——对比围棋:每步行动只落一子
斗地主的牌型:

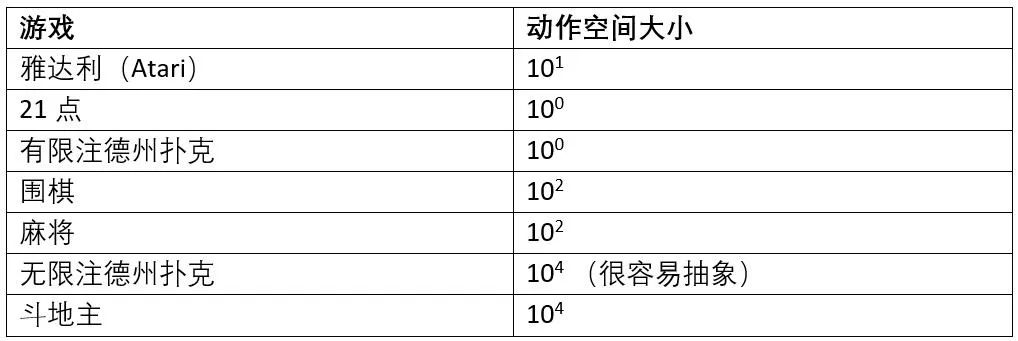
与其他棋牌类游戏的对比:
核心技术
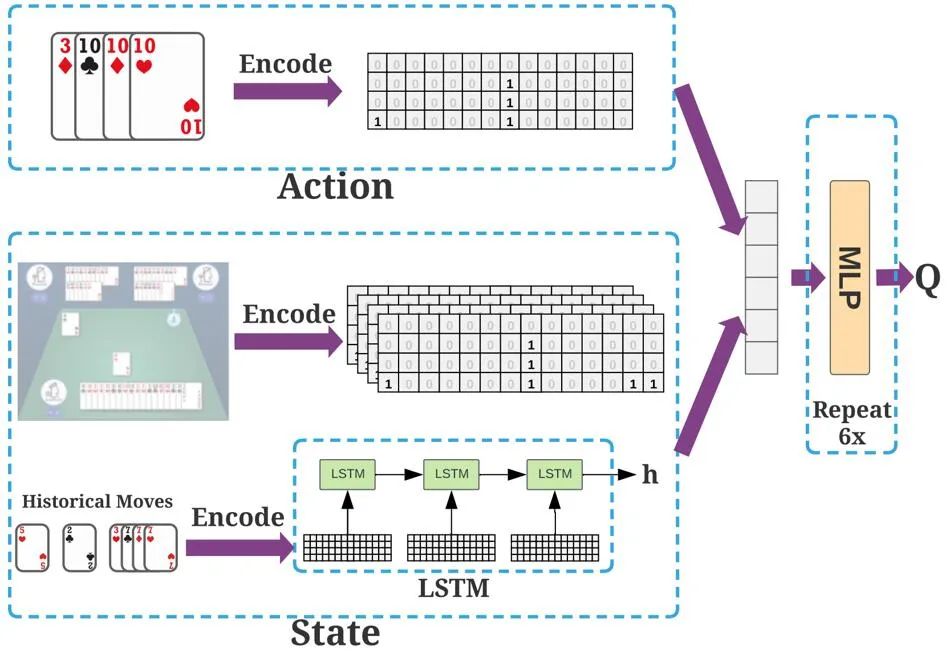
动作编码
通过一个4*15的矩阵对手牌、动作等进行表示,每一列代表一种牌,包含几张牌则对应列有几个1,以下图为例,手牌有一个4,因此第二列只有一个1,手牌有4个10,因此第八列有4个1。

价值网络
用LSTM对历史动作和当前状态进行建模,连同动作编码一起输入价值网络(六层全连接网络),得到当前状态下该动作的得分值。
蒙特卡洛模拟算法
利用蒙特卡洛模拟算法训练价值网络:
- 生成一次对局:三名玩家轮流出牌,以概率p进行随机动作,以概率1-p进行价值网络输出的得分最高的动作,如此往复直到游戏结束,记录所有的状态s与动作a,以及对局结果r。
- 利用第一步得到的
- 将新的的训练价值网络用于样本生成
分布式训练
利用大量Actor生成对局、计算回报,从而生成训练样本
利用三个Learner训练三个价值网络,Actor与Learner间通过buffer进行通信
与AlphaGo、AlphaGo Zero的主要区别
- 用矩阵对动作和状态进行编码,而AlphaGo利用二值图像模拟整个棋盘
- AlphaGo利用了专家知识进行训练,AlphaGo Zero、DouZero只利用规则本身,即自对弈进行训练
- AlphaGo Zero采用策略-价值网络,输入为状态,输出为动作+评分,DouZero采用价值网络,输入状态和动作,输出评分
参考文献
快手开源斗地主AI,入选ICML,能否干得过「冠军」柯洁? - 知乎 (zhihu.com)
[2106.06135] DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning (arxiv.org)

若有收获,就点个赞吧
0 人点赞
