国防 国家安全 技术预见 博弈对抗 仿真推演
意义
- 军事装备愈发先进,战场态势变化愈发迅速,需要智能博弈模型辅助决策。
- 实兵训练成本高,博弈对抗仿真模拟意义重大。
- 博弈对抗可以为指挥控制AI提供交战环境的对抗样本。
- 可以通过博弈对抗检验指挥控制AI的质量。
基于博弈对抗的作战仿真推演&辅助决策
介绍
博弈论,又称赛局理论(Game Theory)。具有竞争或对抗性质的行为称为博弈行为,在这类行为中,参加斗争或竞争的各方各自具有不同的目标或利益。为了达到各自的目标和利益,各方必须考虑对手的各种可能的行动方案,并力图选取对自己最为有利或最为合理的方案。博弈论考虑游戏中的个体的预测行为和实际行为,并研究它们的优化策略。在人工智能中,博弈对抗属于一个很大的概念,其相关并非专指特定的某些算法,而是包含“对抗思想”的算法都可以被囊括其中,例如GAN也属于博弈对抗的算法。
智能决策AI的组成
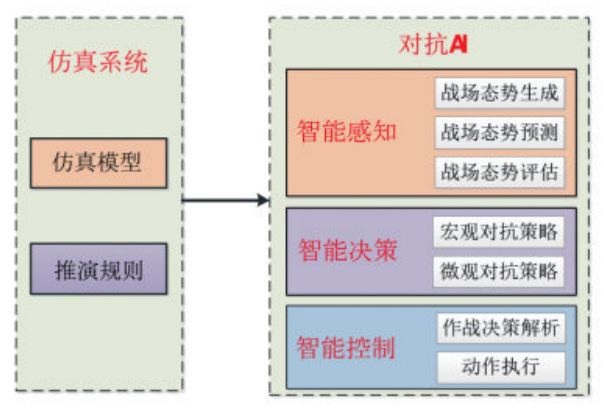
智能决策AI由**仿真系统**与**对抗AI**组成。仿真系统包括**仿真模型**(战场环境模拟、各作战单元仿真模 型等)、**推演规则**等。智能策略AI包括**智能感知系统**、**智能决策系统**、**智能武器控制系统**等。_智能感知是智能决策的基础,智能决策为智能控制提供行动的方向。_**智能感知**包括战场态势生成,战场态势预测,战场态势评估等。战场态势生成包括情报收集与综合、多源信息融合、目标综合识别等。战场态势预测包括对手意图识别、对手意图预测等。战场态势评估包括战损评估、双方赢率估计等。**智能决策**主要解决下一步如何行动的问题。智能感知的输出作为智能决策的输入。智能决策包括宏观对抗策略和微观对抗策略。对抗策略包括策略生成、策略评估、策略优化等。**智能控制**主要解决各作战单元或武器平台如何执行智能决策的输出结果。**博弈对抗的关键是智能决策部分。**
算法
深度强化学习
在强化学习中,智能体通过与环境的交互,自主地了解环境并完成任务。**强化学习以试错的方式与环境进行交互**,通过**最大化累积奖赏的方式来学习最优策略**,对于任意的状态,最优策略可给出相应的动作。
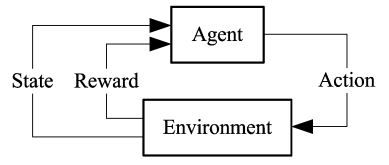
如上图所示,在强化学习的环境中,智能体(Agent) 接受环境(Environment) 的状态输入(State) ,输出决策 动作(Action) ,然后根据决策动作给出反馈(Reward) ,接着智能体接收反馈并学习然后给出新一轮的决策动作,如此反复交互就是强化学习的训练过程。由于军事场景的高度复杂性,难以穷举所有的状态,行为以及激励值,因此需要通过深度学习过组合低层特征形成更加抽象的高层形式表示属性类别或特征,以发现数据的分布式特征表示形式。**简单来说,深度强化学习是深度学习的感知能力+强化学习的决策能力。**最近几年发展起来的深度强化学习算法,主要有基于值函数的DQN及其扩展算法,基于Actor-Critic的A3C算法,基 于策略梯度的TRPO、DDPG算法,以及其他类型的深度 强化学习算法,如分层深度强化学习、多智能体深度强化学习等
元学习
元学习可以理解为要学习一种学习能力,用来解决深度强化学习训练量大,奖赏函数难以设定的问题。关于元学习的研究目前处于刚起步的状态,呈现一种百花齐放的趋势,有很多不同的研究思路出现,比如学习神经网络训练过程中的超参数或神经网络的结构以及优化器等以 往需要人为设定的东西;通过在神经网络上添加记忆来实现充分利用以往的经验学习;在强化学习中,通过在输入上增加以往的奖赏或状态动作等信息来推断环境或任务级别的信息;同时运用多个任务的合成梯度方向进行训练等。
应用
兵棋推演
兵棋推演是研究现代战争的有力工具。在兵棋推演中,对抗双方或多方运用兵棋,按照一定规则,在模拟的 战场环境中对设想的军事行动进行交替决策和指挥对抗的演练。兵棋推演的作用是推演各方通过排兵布阵及对战场资源的利用来模拟战争,通过对推演过程中指挥员决策的分析来寻找适合这场战争的最佳策略。结合人工智能的兵棋推演可能会成为未来军事模拟的主要手段。
军事指挥信息系统
军事指挥信息系统是作战体系的中枢神经,军事指挥信息系统的智能化可以通过智能策略AI重点解决战场态势理解、方案分析和辅助决策等问题。
案例
指挥官虚拟参谋
“指挥官虚拟参谋”(Commander’s Virtual Staff,简称CVS)是美陆军2015年着手规划,计划2016年启动、2018年结束的新项目,是继“深绿”后美军发展指挥控制智能化的又一重要举措。CVS借鉴Siri、Watson等产品理念,扮演类似参谋或助手的角色,旨在综合应用认知计算、人工智能和计算机自动化等智能化技术,来应对海量数据源及复杂的战场态势,提供主动建议、高级分析及针对个人需求和偏好量身剪裁的自然人机交互,从而为陆军指挥官及其参谋制定战术决策提供从规划、准备、执行到行动回顾,全过程的决策支持。
围绕陆军需求,项目规划的能力较为全面:
1)指挥员专用工具:辅助指挥员理解、显示、描述、指挥的手持工具,可不受位置限制地使用;
2)协作工作流:支持指挥员和参谋随处开展任务编排、跟踪、产品及任务交付物的生产和共享;
3)数据汇聚:面向任务需求获取相关信息,提供给指挥员整合后的数据集;
4)敏捷规划:领域无关的集成规划能力,支持战争博弈、准备、排演,及实现任务执行过程中的人机协作;
5)评估:基于当前、未来及替代方案等,向指挥员持续提供计算机支持的在线评估;6)预测:基于态势数据和当前计划,识别和推理态势的演变,生成告警,和具有一定置信度的未来态势图(很可能是“深绿”的延续);
7)建议:基于特定领域知识自动生成建议,附上置信度评价及替代方案;
8)机器学习和用户配置持续改进:更好的支持特定个人及组织的过程和偏好。
“雅典娜”兵棋平台
雅典娜平台是美国海军陆战队一直在实验的兵棋推演平台,该平台可用于训练、教育以及测试AI应用程序。在这种推演环境中,美国军方能够获取构建AI应用程序所需的数据,可以检测不同的决策并探索与整合新科技相关的人类因素。雅典娜在协助军事规划者探索将AI整合到现代能力方面具备以下优势:
首先,它能提供更具适应性的专门化教育环境。通过跟踪对阵员提出的问题,与兵棋的交互以及结果,雅典娜可以了解美国军方的战斗方式以及需要改进的地方。
其次,它为测试新的AI应用程序提供了平台。比如,开发人员可引入新的AI启动的后勤管理体系来确定对阵员的表现是否因此提高。
第三,雅典娜还具备自动组建红方(假想敌)能力。随着更多对阵员规划和执行任务,并同时与类似于Alexa界面交互,军方通过建立一个数据语料库来说明我们的偏见和风险承受能力。该系统可用来测试突出这些偏见是否会改变兵棋推演结果。
最后,一旦有充足的数据,雅典娜可在参考性学习基础上自己模拟现代军事战争并提出新战术。这些战术以及用于人类行动方案测试的应用程序,可让数以千计的对阵员在商业平台上通过战斗竞赛形式进行测试。
DARPA的游戏之路
2017年4月,DARPA发布征询启示,寻求推进当前的推演、建模和仿真能力。2018年5月,Siri软件的创造者之一斯坦福研究所(SRI International)加入了DARPA,计划用《星级争霸》游戏训练AI,成功后会尝试迁移到现实中执行类似任务。《星际争霸》之类的即时策略(Real-TimeStrategy,简称RTS)游戏,相比棋类游戏更贴近真实战争博弈。如果快速发展的游戏AI能成功用在作战指挥控制中,对发展指挥控制智能化将起到很大的推动作用。
军事运筹辅助决策系统
解放军理工大学研制的军事运筹辅助决策系统,可自动生成作战方案,演示战斗过程,评估战场效果等。具体参考[指挥控制智能化——瓶颈问题和建议_发展 (sohu.com)](https://www.sohu.com/a/257308635_358040)中参考文献18。
“进攻一号”军事专家支持系统
由军事科学研究院研发,建立了4000多条规则和一个定性与定量相结合的高效推理机制,能够自主生成作战的参考方案,辅助指挥员决策。具体参考指挥控制智能化——瓶颈问题和建议_发展 (sohu.com)中参考文献19。
智能决策AI面临的问题
军事领域智能决策AI面临的根本问题是缺乏战争博弈实践,主要包括以下三方面:
- 缺乏对抗样本数据。主要数据来源是日常值班,实兵演练,模拟训练等,对抗激烈程度低,同时数据缺乏标注。
- 缺乏验证评价手段。单项装备或系统可以直接在靶场验证检验,但决策AI的效果需要通过一个兵力系统的综合行动体现,并且需要置于对抗环境中,AI的泛化能力难以保证。
- 缺乏应用选点指导。利用AI技术解决具体问题时,需要人同时对问题领域和AI技术都有很深的领悟。目前,同时对作战指挥和AI技术深入了解的人很少。
可能的解决方案——人机混合智能模式
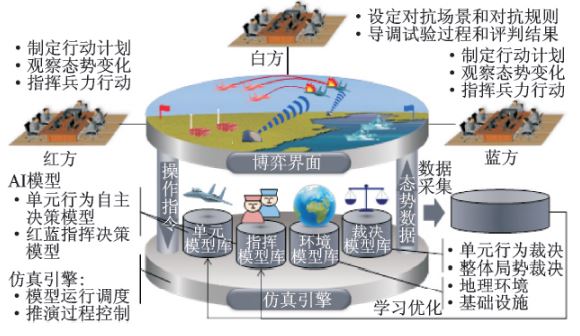
平台如上图所示,白方(导演方)可任意设定对抗场景和对抗规则,导调试验过程,评判试验结果。红方和蓝方制定行动计划,观察战场态势变化,运用博弈策略指挥兵力行动。仿真环境下,模拟推演指挥对象的自主对抗行为和裁决行动效果,生成模拟态势,采集对抗数 据,开展机器学习。

人机混合的思想如上图所示。如果所有棋子均需要认为操控,那么一次博弈实验耗时极长,而直接全部AI控制棋子的问题如前文所说,因此,选择了折中方案,通过人的博弈,AI采集态势数据并学习,多次迭代后逐步减少“人在环”的比例,先实现单个棋子的自主行动,在实现对全局棋子的自主指挥。
参考文献
指挥控制智能化——瓶颈问题和建议_发展 (sohu.com)
基于深度学习的军事智能决策支持系统 (360doc.com)
体系对抗中的智能策略生成 张瑶,马亚辉
WAR-ALGORITHM ACCOUNTABILITY Dustin A. Lewis, Gabriella Blum, and Naz K. Modirzadeh
发展智能指挥控制与打造博弈试验平台 金欣
基于人工智能技术的智能自博弈平台研究 卢锐轩, 孙 莹 , 杨 奇 , 王 壮 , 吴昭欣, 李 辉
作战推演中智能博弈对抗算法水平评估模型研究 韩超

若有收获,就点个赞吧
0 人点赞
