人工智能,机器学习,深度学习,预训练
简介
**课程学习(CL)是一种训练策略**,它模仿了人类课程中有意义的学习顺序,从**较容易的数据开始训练机器学习模型,并逐步加入较难的数据。**课程学习策略作为一个易于使用的插件,在计算机视觉和自然语言处理等广泛的场景中,提高了模型的泛化能力和收敛速度。
Original CL
一个具有T步的训练过程可以写为:
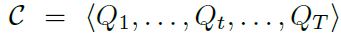
其中Q为:
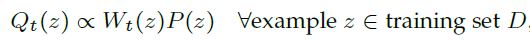
Q为训练中某一步时的样本分布(P是原先样本分布)
要求满足:

- 熵增,样本包含的信息越来越多;
- 使用的样本越来越多,训练集逐渐增大;
- 最终,重新加权的样本分布等于原样本分布。
简单来说,就是先取少量简单样本,随着训练次数慢慢加入相对复杂的样本,最后所有样本加入训练。
以上属于CL最初的定义,但大多数CL方法并非严格遵守这三点定义,而是领会“从简单数据(任务)到复杂数据(任务)”的精神。例如,有的模型觉得完整数据好分析,其算法找到的“课程顺序”是从完整数据,到各个子集。
CL为什么有效
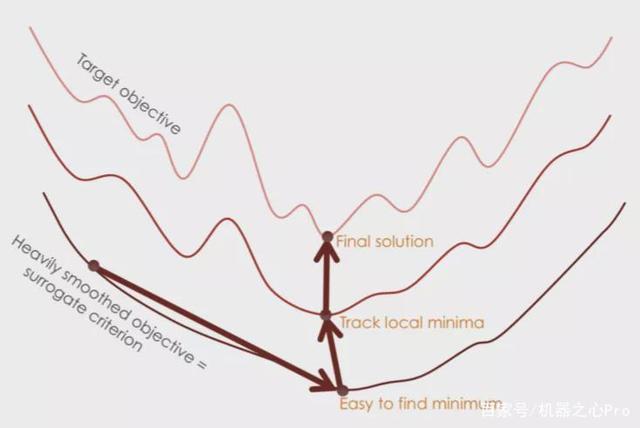
CL的有效性可以由这幅图简要说明:
从优化的角度来说:CL在初始阶段松弛了优化目标并逐渐收紧,这有利于模型逃离较差的局部最优点。
从数据的角度来说:CL是一种去噪的策略,由易到难的策略可以缓解模型在初始学习阶段受到的噪声干扰。
CL框架
整体上来说,CL框架由难度评分器(Difficulty Measurer)与训练调度器(Training Scheduler)两部分组成,前者给数据样本定级,后者按照前者的定级决定样本送入训练的顺序。
举个例子,难度评分器根据样本的难易程度对样本进行排序,训练调度器最初选择最简单的40%的样本,并随着训练步长增加每步加5%。
CL框架可以分为预定义CL(Predefined CL)与自动化CL(Automatic CL),前者的难度评分器与训练调度器的设计完全依靠人类先验知识,不涉及任何数据驱动模型或算法,后者则是两部分任意一个有涉及数据驱动模型或算法。
预定义CL
难度评分器
主要从复杂度、多样性、噪声估计等角度,利用特定领域的知识来评判样本的难度。例如:
- 从单个样本的复杂度角度,机器翻译中更长的句子对常被认为是更困难的训练样本;
- 图像语义分割任务中物体数目更多的图片会更困难;
- 从一组数据的分布多样性角度,机器翻译中含有更多更生僻的单词的句子会被认为更困难;
- 从样本的噪声估计角度,语音识别中的信噪比越低的样本会被认为更困难。
训练调度器
预定义的训练调度器本质是一个函数 h(t),将当前的训练轮数 t 映射为一个比例λt,在第 t 轮将选择λt 比例的最简单的样本作为当前采样的训练集。
局限性
- 忽略了模型的状态和反馈,导致算法不够灵活,无法根据数据和模型动态调整以达到更好的效果;
- 需要人为决定样本难度,不仅耗时、不在更广的领域普适,且人工认定的难度并不一定有利于模型的学习。
自动化CL
自步学习 Self-Paced Learning
自步学习(Self-paced learning)**让机器学习模型本身作为难度评分器**,将**当前模型损失较高的样本作为更困难的样本**。这种策略与人类自学很相似:学生可以根据自己的学习进度(模型状态)来调整自己的学习节奏(先学更简单的学习材料)。自步学习是一个相对独立的研究领域,在这篇文章中把它归类为自动课程学习的一大类方法。自步学习定义如下:
自步学习赋予每个样本 (x,y) 一个损失权重 v,并优化下列目标函数:
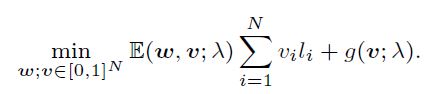
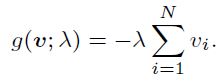
其中 N 为训练集样本数,w是机器学习模型 fw 的参数,l 是损失函数,λ是age parameter,用于控制learning pace以及选择的最简单的样本的比例,逐渐增大。g(v; λ)是对于样本权重向量 v 的l1正则项,用于自动调控不同样本的权重。
自步学习算法通常采用交替优化策略,每轮先固定w优化 v(这一步通常可以直接计算解析解),再固定 v 优化w。
个人理解:把两个式子合并变成 vi(li-λ) ,然后λ可以看作一个阈值,即learning pace,小于这个阈值的损失l对应的样本都被归类为easy,随着λ阈值逐渐增大,easy的样本也就越来越多,即扩大了选择的最简单的样本的比例。如第一句话所说,本质上是一个基于数据的难度评分器+人工预设的训练调度器。
迁移教师方法 Transfer Teacher method
此类方法用一个较强大的教师模型作为难度评分器,**教师模型预先在当前数据集或其他大规模数据集预训练好**,并**将它的知识迁移到学生模型(即待训练的机器学习模型)的课程设计中**。相比自步学习,这类方法**弥补了 “训练初始阶段机器学习模型本身尚不成熟,导致难以判断难度” 的缺陷**,转而选用一个成熟的教师模型来评估样本的难度。**在训练调度器上,此类方法与自步学习相同,依旧采用预定义的训练调度器。**
强化学习教师方法 RL Teacher method
此类方法采用强化学习框架作为教师,以基于学生模型的反馈来动态选择训练数据(或决定训练数据权重)。此类方法属于数据级别广义课程学习方法,它模拟了人类教育中最理想的 “教学相长” 现象:**学生基于教师为其量身定制的学习材料而获得最大的进步,同时教师也可以通过学生的反馈来动态调整教学策略,提升教学水平。**从思想上,强化学习框架的要素在课程学习中的对应如下:
- 强化学习的动作即为在训练集里挑选数据(或给予数据权重);
- 强化学习的状态为学生模型当前的状态反馈、以及其他训练状态信息(如训练轮数);
- 强化学习的奖励可根据优化目标定义为与学习效率或效果有关的函数(如模型在验证集上的准确率增量)。
相比其他的课程学习方法,此类方法的设计更具灵活性,但其缺点在于深度强化学习框架计算开销大,且较难训练。
CL与其他ML概念对比
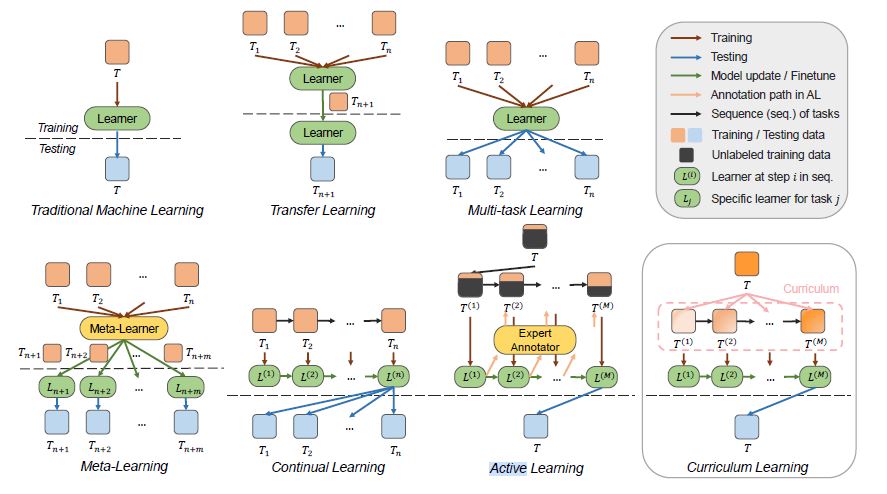
- 元学习与CL看似结构差异很大,但实际上干得事情差不多,都是优化算法超参数设置,只不过元学习是learning to learn,CL是learning to teach。
- 连续学习看似与CL结构差不多,但实际上差别较大,连续学习中的T都是预设好的,CL中T则是随课程设置动态变化的。(原文是这么写的,但个人觉得CL就是特殊的连续学习)
- 主动学习跟CL想法差不多,都是给样本排序,不过主动学习需要人工介入,模型筛选出其认为重要的无标记样本丢给专家贴标签,然后再拿进来训练,再找一些样本丢给专家,依次循环。
参考文献
A survey on Curriculum Learning
TPAMI 2021 | 清华大学朱文武团队:首篇课程学习综述 (baidu.com)

若有收获,就点个赞吧
0 人点赞
