军事,技术预见,博弈对抗,仿真推演
摘要
未来战争中智能技术的应用,无人系统如智能弹群、无人机群等多智能体将投入作战,要求智能体具有快速作战决策能力。由于无人系统的计算资源有限、内存空间小、数据传输受限,多智能体系统的自主性、协同性及群智决策等算法应实现轻量化、开销最小化。从多智能体群智决策存在的挑战出发,提出了基于深度网络的强化学习群智决策模型,讨论了其中涉及的关键技术,创新地从OODA 决策循环4个关键环节提出轻量化思路。
多智能体系统(Multi-Agent System,MAS)
如导弹集群,无人机群等,通过**多个智能体作战单元协调工作构成集群系统**,可以更好的适应不同任务的要求。多个智能体集结而成的系统,不仅仅是无人作战单元数量上的扩充和功能上的简单相加,而是在统筹协调下有机地集成到一个系统之中,高度融合、整体联动,实现群智感知、群智认知、群智决策和作战协同。
博弈的困难与方法
军事博弈的困难在于,军事博弈对抗具有多场景、多目标、多层次、多要素的特点,是非完全信息博弈对抗,因此无法进行有效空间搜索和决策,且在对抗过程中需要远期计划,同时需要保证极高的实时性,这对深度学习技术提出了新的挑战。由于信息的不确定性,无法使用深度学习方法进行端对端有效的监督学习,针对非完全信息博弈对抗特点,使用强化学习方法是目前的最优选择,而**强化学习无法像监督学习一样针对明确目标和有用信息进行快速学习,其学习效率较慢**。
群智博弈对抗决策模型

在博弈对抗仿真环境中,多个智能体分别进行学习训练,**每个智能体行为决策生成最优子策略**,再通过多目标的群智决策优化模型,“协商”得到多智能体系统的最终决策。多智能体作用于环境和改变状态,通过效用评价函数,环境反馈即时奖励和累积奖励给MAS。
群智博弈对抗决策关键技术
1)复杂对抗空间的多层次态势感知。
态势感知的目标是根据对抗空间现有状态,给出双方最终战果的概率预测。对多层次局部态势作出判断,结合战场高层次语义理解,给智能体决策提供更多信息;设计一个有效结合复杂静态数据和动态序列数据的感知模型和相应的学习算法,实现多层次态势感知。
- 基于动力学模型的多分枝态势分析。
根据无人作战单元的动力学特性,建立智能体行为特征模型;AI接收实时态势数据,结合装备特征库对敌方目标分群;以执行任务过程中遇到事件为分枝节点,生成主分枝和旁路分枝,输出多分枝态势图。AI基于多分枝态势分析不断随机“试错” 以训练出适应环境的决策网络模型。
- 基于多算子策略的网络监督学习与强化学习协调优化方法。
利用神经网络模型进行端到端的训练,输出算子协同行动最优策略;基于智能体协调优化技术从单一算子的行动决策实现多算子的协同行动决策,实现多目标智能化快速匹配与融合处理的自主决策。
- 多智能体协同任务规划决策方法。
强博弈对抗需要对多层次、多平台、多武器、多目标的火力打击分配任务进行合理建模和求解。根据当前感知信息进行态势判断,制定最优行为决策策略,作出多层级任务规划;采用行为树跳转的方法实现多智能体任务动态重组;按照作战能力和目标特性,制定作战单元和目标分配方案。
博弈对抗策略轻量化思路
文中从指挥决策OODA环入手,对每个环节给出轻量化思路。
观测O
战场环境复杂,变化迅速,深度强化学习需要不断与环境交互学习,但深度强化学习算法学习速度慢,若环境出现新的状态,还需要重新学习。为更加有效地利用环境信息和智能体状态信息,提出引入**注意力机制的价值网络模型**。
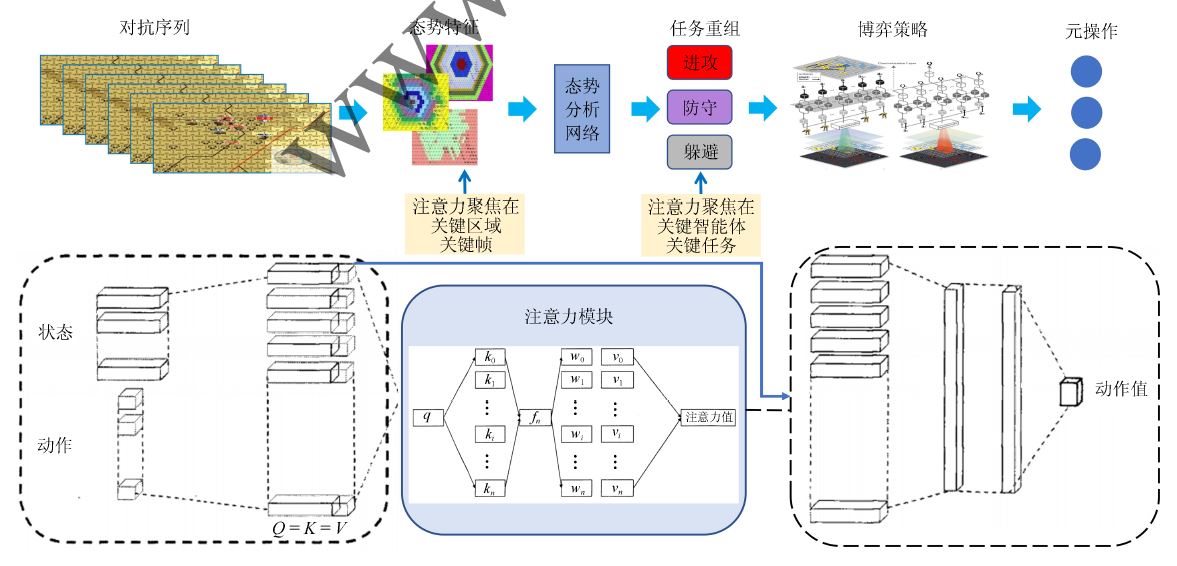
判断O
非完全信息博弈过程中由于战争迷雾的存在,无法了解全部信息,所以在进行决策时,需要对未知区域、未知对抗单元进行有效的预估,从而制定较为合理、准确的决策。由于对抗博弈是连续性的,在态势判断时需要**综合过去和现在的信息**,通过信息综合处理,估计未来态势。人类指挥员对战场态势和威胁的整体判断,依靠直觉和先验知识,经过思维分析而作出的快速反应,是一种“直觉决策”,或者说是大脑无意识存储在**长时记忆中的信息被某种外部刺激突然激活所带来的即时反馈**。这里就是提出用LSTM方法。
决策D
对于**不确定环境下的多智能体协同决策**,面临的另一个挑战是**策略搜索空间巨大**。可以采用分布式局部感知马尔可夫决策过程(Dec-POMDPs) 通用模型,但求解Dec-POMDPs 问题计算复杂度高,内存占用大。有必要研究一种**适用于智能武器装备小内存环境的轻量级策略求解方法**,提出一种整合最优Q 值函数求解和分层策略搜索的启发式方法。
- 最优Q值函数求解。启发式搜索的精确性+蒙特卡洛方法的一般性,联合历史信息、动作,进行扩展搜索树获得联合观测结果,得到整合最优的Q值函数。只按需求解,时间与内存占用少。
- 分布式策略训练。针对不同单元,不同对抗任务分别设置不同的奖励函数分别训练,最后整合。
- 分层协调优划。把整体任务分成不同层次的子任务,每个博弈回合中,每个子任务在各自规模较小的空间内求解,最后整合。
行动A
面向复杂多变的战场环境,多智能体系统作为一个协同作战单元,**应具备任务规划和任务重组能力,提出基于行为树跳转的任务动态重组方法**。针对任务分解构建行为树,动态平衡不同任务或任务组合的复杂度,实现任务的可重组和跳转;设计具有多层级任务可重组能力的AI 框架,解决可重组任务在学习空间中的平衡问题;研究可重组任务的回报函数与决策风格之间的关系,以及对AI 任务规划能力的影响。行为树(Behavior Tree) 是一种包含了层级节点的树结构,通过逻辑分离、逻辑关联、逻辑抽象, 可以有效地管理行为逻辑,协同多智能体决策行为。**AI 的上层是一系列的行为树,每个行为树表示一个作战任务**,如侦查、机动、夺控、攻击等。**多个行为树可以按策略重组**,**组合成能满足不同需求的AI**。树的叶子节点就是AI 实际上要执行的动作,中间节点决定了AI 如何从根节点根据不同的情况沿着不同的路径到达叶子节点的过程。行为树是多层级的,通过调用不同功能的子行为树,可以创建相互连接的子行为树库来构造出一个复杂的AI。由多个AI 组合而成的多智能体系统也可以看成是一个超级AI。**大概意思就是把让AI做简答题变成让AI做选择题。**

若有收获,就点个赞吧
0 人点赞
