混沌工程、分布式、架构、运维、系统测试、数据安全、故障注入
起源
早期Netflix公司的服务器运行在自己机房,但这会造成单点故障和其他问题。在2008年8月,数据库的问题导致了三天宕机,在此期间在Netflix无法看任何视频。Netflix工程师在2011年将服务迁移到Amazon Web Services。这种由数百个微服务组成的新型分布式架构消除了单点故障。但它也引入了新的复杂性问题,需要更加可靠和容错性更强的系统。正是在这一点上,Netflix的工程团队学到了重要的教训:通过不断失败避免失败。为此,Netflix工程师创建了Chaos Monkey,使用该工具可以在整个系统中在随机位置引发故障。正如GitHub上的工具维护者所说,“Chaos Monkey会随机终止在生产环境中运行的虚拟机实例和容器。”通过Chaos Monkey,工程师可以快速了解他们正在构建的服务是否健壮,是否可以弹性扩容,是否可以处理计划外的故障。随着Chaos Monkey的出现,一门新学科诞生了:混沌工程,被描述为“在分布式系统上进行实验的学科,目的是建立对系统承受生产环境中湍流条件能力的信心。”
简介
混沌工程,是一种提高技术架构弹性能力的复杂技术手段。Chaos工程经过实验可以确保系统的可用性。混沌工程旨在将故障扼杀在襁褓之中,也就是在故障造成中断之前将它们识别出来。通过主动制造故障,测试系统在各种压力下的行为,识别并修复故障问题,避免造成严重后果。它也可以视为流感疫苗,故意将有害物质注入体内以防止未来疾病,这似乎很疯狂,但这种方法也适用于分布式云系统。混沌工程会将故障注入系统以测试系统对其的响应。这使公司能够为宕机做准备,并在宕机发生之前将其影响降至最低。
混沌工程、故障注入、故障测试
混沌工程和其他方法之间的主要区别在于,混沌工程是一种生成新信息的实践,而故障注入是测试一种情况的一种特定方法。当想要探索复杂系统可能出现的不良行为时,注入通信延迟和错误等失败是一种很好的方法。但是我们也想探索诸如流量激增,激烈竞争,拜占庭式失败,以及消息的计划外或不常见的组合。如果一个面向消费者的网站突然因为流量激增而导致更多收入,我们很难称之为错误或失败,但我们仍然对探索系统的影响非常感兴趣。同样,故障测试以某种预想的方式破坏系统,但没有探索更多可能发生的奇怪场景,那么不可预测的事情就可能发生。
混沌工程实验步骤
1.定义并测量系统的“稳定状态”。首先精确定义指标,表明您的系统按照应有的方式运行。 Netflix使用客户点击视频流设备上播放按钮的速率作为指标,称为“每秒流量”。请注意,这更像是商业指标而非技术指标;事实上,在混沌工程中,业务指标通常比技术指标更有用,因为它们更适合衡量用户体验或运营。2.创建假设。与任何实验一样,您需要一个假设来进行测试。因为你试图破坏系统正常运行时的稳定状态,你的假设将是这样的,“当我们做X时,这个系统的稳定状态应该没有变化。”为什么用这种方式表达?如果你的期望是你的动作会破坏系统的稳定状态,那么你会做的第一件事会是修复问题。混沌工程应该包括真正的实验,涉及真正的未知数。3.模拟现实世界中可能发生的事情,目前有如下混沌工程实践方法:模拟数据中心的故障、强制系统时钟不同步、在驱动程序代码中模拟I/O异常、模拟服务之间的延迟、随机引发函数抛异常。通常,您希望模拟可能导致系统不可用或导致其性能降低的场景。首先考虑可能出现什么问题,然后进行模拟。一定要优先考虑潜在的错误。 “当你拥有非常复杂的系统时,很容易引起出乎意料的下游效应,这是混沌工程寻找的结果之一,”“因此,系统越复杂,越重要,它就越有可能成为混沌工程的候选对象。"4.证明或反驳你的假设。将稳态指标与干扰注入系统后收集的指标进行比较。如果您发现测量结果存在差异,那么您的混沌工程实验已经成功 - 您现在可以继续加固系统,以便现实世界中的类似事件不会导致大问题。或者,如果您发现稳定状态可以保持,那么你对该系统的稳定性大可放心。
常见故障模式
- 当服务不可用时的不正确回滚设置;
- 不当的超时设置导致的重试风暴;
- 由于下游依赖的流量过载导致的服务中断;
- 单点故障时的级联失败等。
混沌工程原则
以下原则描述了应用混沌工程的理想方式,这些原则基于上述实验过程。对这些原则的匹配程度能够增强我们在大规模分布式系统的信心。
- 建立稳定状态的假设
要关注系统的可测量输出, 而不是系统的属性。对这些输出在短时间内的度量构成了系统稳定状态的一个代理。 整个系统的吞吐量、错误率、延迟百分点等都可能是表示稳态行为的指标。 通过在实验中的系统性行为模式上的关注, 混沌工程验证了系统是否正常工作, 而不是试图验证它是如何工作的。 - 多样化现实世界事件
混沌变量反映了现实世界中的事件。 我们可以通过潜在影响或估计频率排定这些事件的优先级。考虑与硬件故障类似的事件, 如服务器宕机、软件故障 (如错误响应) 和非故障事件 (如流量激增或伸缩事件)。 任何能够破坏稳态的事件都是混沌实验中的一个潜在变量。 - 在生产环境运行实验
系统的行为会依据环境和流量模式都会有所不同。 由于资源使用率变化的随时可能发生, 因此通过采集实际流量是捕获请求路径的唯一可靠方法。 为了保证系统执行方式的真实性与当前部署系统的相关性, 混沌工程强烈推荐直接采用生产环境流量进行实验。 - 持续自动化运行实验
手动运行实验是劳动密集型的, 最终是不可持续的。所以我们要把实验自动化并持续运行,混沌工程要在系统中构建自动化的编排和分析。 - 最小化“爆炸半径”
在生产中进行试验可能会造成不必要的客户投诉。虽然对一些短期负面影响必须有一个补偿, 但混沌工程师的责任和义务是确保这些后续影响最小化且被考虑到。
混沌工程实验评估
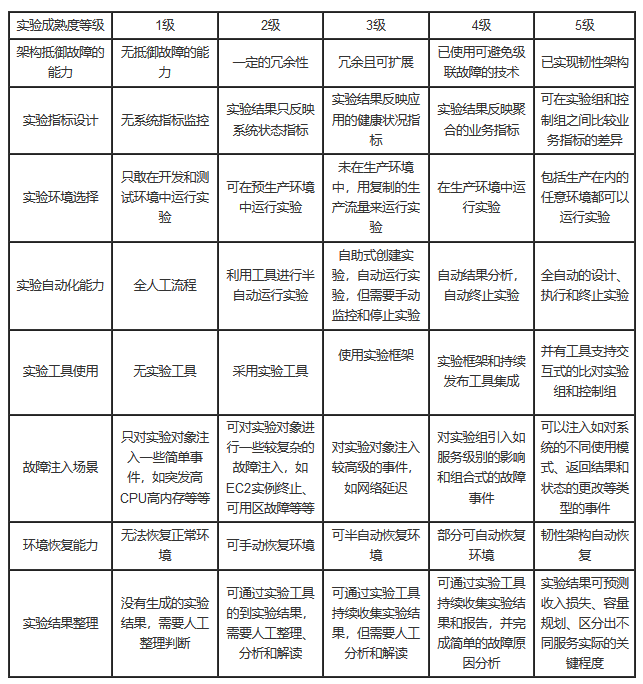
在执行混沌工程实验时,我们需有一个通用的标准来,判断这个实验可不可行,做得好不好。混沌工程的可行性评估模型,结合了亚马逊和Netflix的混沌工程成熟度模型,从成熟度等级和接纳指数两个维度来衡量混沌工程实验成功实施的可行性:
成熟度等级
成熟度可以反映出混沌工程实验的可行性、有效性和安全性。成熟度的级别也会因为混沌工程实验的投入程度而有差异。这里将成熟度等级分为1、2、3、4、5级进行描述,等级越高成熟度越好,混沌工程实验的可行性、有效性和安全性会更有保障。
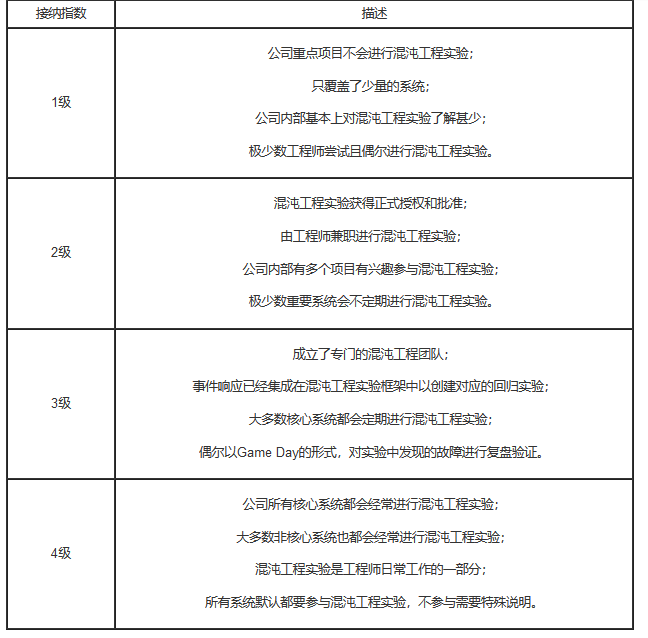
接纳指数
接纳指数通过对混沌工程实验覆盖的广度和深度来描述对系统的信心。暴露的脆弱点就越多,对系统的信心也就越足。类似成熟度等级,对接纳指数也定义了1、2、3、4级进行描述。
解决的问题
了解并改进系统
混沌工程本身并不是要破坏系统。它从来就不是破坏系统的工具,而是学习系统的路径。我们可以从实际问题中学习经验,但这非常痛苦。 “混沌工程让你有机会把问题提前,并将一切置于你的掌控之中。”更有趣的混沌工程实验不应该基于重要并且明显的假设,例如'如果这个机架出现故障,该服务延迟会增大但仍然可用',而应是基于对系统深入理解后作出的假设。混沌工程的实施过程有助于将专家直觉转化为明确的,可测试的假设,暴露出有价值的信息,这些信息不仅仅是以局外人的角度来看待系统本身
实现韧性架构
在处理大规模系统时,即100%的健康运行几乎是不可能实现的。因此,运维的新常态便是接受部分故障。处在部分故障中的系统要求仍能正常运行对外提供服务,这就需要架构本身具备 Resilient 能力。混沌工程就是利用实验提前探知系统风险,通过架构优化和运维模式的改进来解决系统风险,真正实现上述韧性架构,降低企业损失,提高故障免疫力。
应用场景
**混沌工程比较适合对数据安全性要求较高的场景。**此外,如果业务对故障容错有所承诺,也需要通过混沌工程验证系统是否可以支持容错。量化到具体指标来看,如果开发人员确定系统会宕机并且清楚宕机之后会造成较大损失,可以通过“支持快速终止实验”和“最小化实验造成的‘爆炸半径’”等方式实施混沌工程。具体应用场景案例如下:
- 提升系统容错能力以及稳定性
- 评估系统容灾红线
- 验证云服务的动态扩展能力
- 验证监控和告警的有效性以及指标是否全面
- 故障突袭,提升相关人员定位,故障问题的能力
误区
实际混乱,随机性强
将混沌工程视为实际混乱是一种误解。事实上,大量测试是非随机的。相反,混沌工程会在实施前进行深入思考,组织有计划和受控制的实验,旨在揭示系统在失败时的表现。
技术能力够强才可使用
不少人觉得,只有团队的技术能力够强,才可以使用混沌工程。不少人观察到,混沌工程是 Netflix 最先提出的,且在其他大型互联网公司被广泛使用,就得出这样一个结论:必须具有 Netflix 级别的先进技术(因此具有高度的可靠性),才能在生产系统上进行混沌工程实验。但现实是,混沌工程的诞生是源于 Netflix 上云转型,即决定搬出数据中心并大规模迁移上云。没有云的支撑,没有云原生实践的大量投入,混沌工程无从谈起,更不会应运而生。我们现在知道,当时的 Netflix 在可用性方面,并没有什么突出的业界声誉。他们通过(安全地)对其系统进行混沌工程实验,并从中学到了有关系统行为的新知识,再将这些新知识付诸改造实践,才逐步拥有更稳定的系统,进而在可用性实践上获得了业界的瞩目。这是一个逐步积累的过程,也是一个去除技术债的过程。我们都可以从现在开始,开始实践混沌工程,累积相应的经验,有一天也能达到 Netflix 的可靠性水平。
高度监管行业不能使用
不少人觉得,高度监管行业如银行、医疗机构等等,不应使用混沌工程,万一出问题就是大事故。对于此类公司而言,发生可用性事件的后果,肯定比 Netflix 宕机要严重得多,但这并不意味着这些公司不会发生可用性事件。这类公司其实更应该使用混沌工程来更好地了解其复杂的系统。被誉为“金融科技黄埔军校”的 Capital One,英国史达琳银行,澳洲国家银行,美国医疗信息技术供货商(塞纳公司),美国联合健康集团都已经实施了混沌工程。这些组织已经将其作为上云转型的重要环节,同时也通过混沌工程实验来更好地了解系统本身的复杂性。
参考
[1] https://zhuanlan.zhihu.com/p/90294032
[2] https://github.com/wizardbyron/principlesofchaos_zh-cn/blob/master/README.md
[3] https://zhuanlan.zhihu.com/p/55612414

若有收获,就点个赞吧
0 人点赞
