来源:科工力量
作者:铁流
编辑:刘梓琰
日前,龙芯发布自主指令系统(LoongArch ),在国内CPU 公司争相引进X86 、ARM 、Power 、SPARC 、RISC-V 等指令集的情形下,龙芯推出自主指令系统架构显得异常特立独行。
过去这些年,国内CPU 公司引进英特尔、AMD 、IBM 、ARM 、VIA 、高通等公司的CPU ,但始终没能建立起自己的Wintel ,原因就在于始终保持着一种跟随心态,缺乏独立自主的决心和毅力。随着国际大环境风云变幻,特别是经过特朗普和拜登的教育,构建自主可控的信息技术体系和产业生态已成为共识,龙芯在此时发布自主指令系统架构可谓是恰逢其时。
龙芯自主指令系统是全新指令集
CPU 指令系统是计算机的软硬件界面,是CPU 所执行的软件指令的二进制编码格式规范。
目前,国际上曾经具有一定影响力的指令集有X86 、MIPS 、ARM 、Power 、Alpha 、SPARC 、RISC-V 等,这些指令集都是舶来品,真正由国内自主研发的只有LoongArch 和SW64 。SW64 是申威CPU 的指令集,由国内单位自主研发,神威太湖之光超算的芯片SW26010 就是基于SW64 设计的。过去,龙芯基于MIPS 指令集添加指令发展出LoongISA ,本次的龙芯自主指令系统则与MIPS 完全没有关系,是完全自主研发的全新指令集。
MIPS 是全球第一种商用的RISC 指令集,由于“历史悠久”,指令系统中有部分不适应当前软硬件设计技术发展趋势的陈旧内容,龙芯摒弃了传统指令系统中令人诟病的部分,吸纳了近年来指令系统设计领域诸多先进的技术发展成果。例如单条指令支持的立即数从MIPS 的最大16 位扩展到最大24 位,分支跳转偏移也从64K 扩展到1M 字节,以及寻址空间从固定分段改变为单一平面等,有效减少了编译结果的目标指令条数和访存次数,提高了效能。
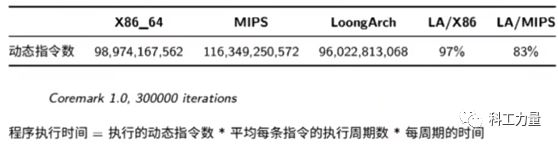
由于LoongArch 指令设计上更加优化,在把源码编译为目标程序后的指令数量上甚至比x86 略有优势。在Coremark 的测试中,程序运行过程中执行的指令总数LoongArch 为MIPS 的83% ,相当于运行效率提高了20% 。在类型更加多样的测试中,综合测试结果,LoongArch 平均比MIPS 快12% ,说明全新设计的LoongArch 是成功的,可以为CPU 带来大幅的性能提升。
编者注:
指令集越精简,同一任务指令数量越少,能效越高。
精简指令集规模较小,更接近原子操作,而复杂指令集规模较大,更加复杂。所谓原子操作,是指每条指令的工作大都可以由处理器在一个操作内完成,例如对两个寄存器做加法。
复杂指令集的指令描述某个意图,但是处理器必须执行3或4个更简单的指令来实现这个意图。例如,可以命令一个复杂指令集处理器对2个数求和,并把结果存入主内存中。为了完成这个命令,处理器首先从地址1中取得第一个数(操作1),然后从地址2中取得另一个数(操作2),然后求和(操作3),等等。
另外,LoongArch 设计时充分考虑兼容生态需求,融合了各国际主流指令系统的主要功能特性,操作系统中除了运行原生的 LoongArch 程序,还能通过翻译的方式兼容MIPS 、x86 、ARM 、RISC-V 这几种指令集的 Linux 程序。根据官方公布的PPT ,在翻译X86 时,运行效率可以达到80% 。
2020 年,龙芯委托国内第三方知名知识产权评估机构对龙芯基础架构进行深入细致的知识产权评估,将LoongArch 与ALPHA 、ARM 、MIPS 、POWER 、RISC-V 、X86 等国际上主要指令系统有关资料和几万件专利进行深入对比分析。2021 年1 月,针对被评估的基础架构版本该评估机构认为:
1 )LoongArch 在指令系统设计、指令格式、指令编码、寻址模式等方面进行了自主设计。
2 )LoongArch 指令系统手册在章节结构、指令说明结构和指令内容表达方面与上述国际上主要指令系统存在明显区别。
3 )未发现LoongArch 基础架构对上述国际主要指令系统中国专利的侵权风险。

自主CPU的两个维度:自主指令系统、自主完成前端后端设计
首先看自主指令系统。
过去,一些国内厂商宣称自己获得了ARM v8 授权,一些ARM CPU 的支持者因此就称国产ARM CPU 符合自主要求。半个月前,ARM 发布了其下一代芯片架构ARM v9 ,并声称是10 年来最重要的创新,是未来3000 亿ARM 芯片的基础。在ARM v9 发布后,国内购买ARM v8 授权的ARM CPU 厂商何去何从就是一个问题了。
诚然,关于某些国内厂商能够继续购买ARM v9 指令集授权的报道充斥网络,但只要查一下新闻源头可以发现源头是2019 年的一篇外媒报道,国内媒体是拿2019 年的报道拼接套娃,就ARM 官网上关于发布ARM v9 的网页看,文末的合作伙伴有谷歌、英伟达、恩智浦、富士通、红帽等国外企业,也有台积电、联发科、OPPO 、VIVO 、小米等中国企业,然而,一些国内厂商并不在合作伙伴名单内。
退一步说,即便这次侥幸买到了ARM v9 授权,那么,将来ARM 发布V10 、V11 、V12…… 国内ARM CPU 企业是不是还要继续买V10 、V11 、V12 授权…… 如果是这种“ 买无止境” ,那么,国产ARM CPU 所标榜的“ 自主” 又从何谈起呢?
因此,自主CPU 必须基于自主指令系统,基于ARM 授权开发的CPU 根基不牢,是在沙滩上建房子,自主性无从谈起。
编者注:
使用ARM指令集,缺陷在于被别人卡住喉咙,哪天不合作了就会出问题。
其次是自主设计。这里的自主设计包含自主完成前端设计和后端设计。芯片设计到流片,基本分两大部分,前端和后端。
前端是RTL design ,根据design specification ,做设计,形成 verilog 代码,然后用eda tool 做 functional verification ,反复做迭代修改,直到通过检验。后端设计分两部分,logic design 和 physical design 。logic design 接受前端的Verilog 文件,用 synthesis 工具 生成门级网表,然后再用eda 工具做logic equivalence check ,迭代直到通过。physical design 接受门级网表用place&route 软件生成physical layout ,并用tools 对layout 进行physical verification ,包括RC extraction 和 post-layout verification 等等,迭代直到通过。通过后生成GDSII ,发送代工厂流片,叫tape-out 。
当下,从国外购买各种IP 和设计外包是行业常态,比如华为麒麟芯片、紫光虎贲芯片的CPU 核、GPU 核基本从ARM 、Imagination 等外商购买,又比如飞腾把后端设计外包给世芯。
之所以出现购买IP 和设计外包的情况,根源还是自己基础不牢,技术不扎实,又不愿意一步一个脚印提升技术水平,想要尽快出成绩。而技术提升恰恰是需要循序渐进的,前端设计一代产品更新源代码替换一般不会超过25% ,必须一代一代逐代演进。后端设计中的定制模块设计,通常先流一次片,用于验证功能,没有问题,再当做一个模块或者IP 集成到芯片中,保证不容易出错,因此,后端需要经验丰富的人,这都是拿钱和流片,以及时间去学习积累出来的,而国内一些CPU 公司为了抓住国家政策红利,自然会选择购买IP 或外包设计尽快出成绩。
在采用外购的IP ,或将设计外包之后,一方面会带来自身技术底子不扎实的问题,一个最明显的现象就是后继乏力,发展后劲不足,比如在CPU 的IPC 提升上,技术引进CPU 明显不如龙芯,于是只能靠采用更先进的台积电工艺来提升性能。另一个是必然带来巨大政治风险,一旦遭遇制裁,后果不堪设想。最近,飞腾被美国列入实体清单,而飞腾的后端设计恰恰外包给了世芯,由于世芯在中国台湾岛内上市,且飞腾是世芯的第一大客户,去年占其业绩比重约39% ,世芯在第一时间召开了在线说明会。根据世芯官方消息,飞腾被列入实体清单后,为该公司提供最后阶段设计的世芯后续出货将受阻,而飞腾委托世芯设计及量产制造的尖端制程芯片,已被台积电暂停接单,并待后续调查状况后再行决定。
结语
一种指令系统承载了一个软件生态,如X86 指令系统和Windows 操作系统形成的Wintel 体系,以及ARM 指令系统和Android 操作系统形成的AA 体系。为了可以对接X86 和ARM 生态,兆芯通过合资的方式使其在中国大陆市场可以销售X86 芯片,华为、飞腾、华芯通使用购买指令集授权的方式获得ARM 授权,但事实证明,华为、飞腾、华芯通的道路行不通。在ARM 的地基上,建不起自主技术体系的高楼大厦。国外CPU 厂商以指令系统作为控制生态的手段,需要获得“授权”才能研制与之相兼容的CPU 。采用授权指令系统可以研制产品,但不可能形成自主产业生态,就像中国人可以用英文写小说,但不可能基于英文形成中华民族文化。
指令系统是软件生态的起点,只有从指令系统的根源上实现自主,才能打破软件生态发展受制于人的锁链。龙芯自主指令系统的推出是龙芯筹谋已久的成果,绝非某些厂商用来应对危机公关的“按揭开源”产品。因为3A5000 就是基于LoongArch 设计,且已经有样片,将在2021 年投放市场,从确定新指令集到基于新指令集设计一款CPU ,再到完成流片,需要漫长的周期。从龙芯最初基于MIPS 添加指令,到发展出基于MIPS 的LoongISA ,再到最新的LoongArch ,龙芯的目的是非常明确的,也是显而易见的,那就是尽一切可能掌握主导权,坚定不移走自主之路。
必须说明的是,龙芯和华为、飞腾一样,在当下都很难顶住美国禁令。
诚然,华为和飞腾ARM 芯片绝版的最主要原因是失去台积电流片渠道,但两者在设计上都依赖海外技术输入,华为的鲲鹏芯片设计很大程度上得益于华为开设在美国的研究所,而飞腾在后端设计上则外包给世芯,这都是非常危险的,因为美国可以轻易中止技术输入。可以说,华为和飞腾在ARM 授权、CPU 设计、CPU 制造三个环节都被卡脖子。
龙芯虽然已经实现了自主指令系统和CPU 自主设计,不需要从国外研究所获取技术,也不需要把后端设计外包给世芯这样的境外厂商,但在流片渠道上同样脆弱。由于在半导体设备、材料、EDA 等多方面受制于人,国内尚无法做到全产业链,而美国的实体清单恰恰是“100-1=0 ”。
补充
指令集对CPU性能的影响
指令系统指的是一个CPU所能够处理的全部指令的集合,是一个CPU的根本属性。
比如我们现在所用的CPU都是采用x86指令集的,他们都是同一类型的CPU,不管是PIII、Athlon或Joshua。我们也知道,世界上还有比PIII和Athlon快得多的 CPU,比如Alpha,但它们不是用x86指令集,不能使用数量庞大的基于x86指令集的程序,如Windows98。
之所以说指令系统是一个CPU的 根本属性,是因为指令系统决定了一个CPU能够运行什么样的程序。所有采用高级语言编出的程序,都需要翻译(编译或解释)成为机器语言后才能运行,这些机器语言中所包含的就是一条条的指令。
CISC(Complex Instruction Set Computing,复杂指令集)
一开始,计算机的指令系统只有很少一些基本指令,而其他的复杂指令全靠软件编译时通过简单指令的组合来实现。
举个最简单的例子:
- 一个a乘以b的操作就 可以转换为a个b相加来做,这样就用不着乘法指令了。当然,最早的指令系统就已经有乘法指令了,因为用硬件实现乘法比加法组合来得快得多。
- 由于那时的计算机部件相当昂贵,而且速度很慢,为了提高速度,越来越多的复杂指令被加入了指令系统中
- 很快又有一个问题:一个指令系统的指令数是受指令操作码的位数所限制的,如果操作码为8位,那么指令数最多为256条(2的8次方)。
- 那么怎么办呢?指令的宽度是很难增加的,聪明的设计师们又想出了一种方案:操作码扩展。前面说过,操作码的后面跟的是地址码,而有些指令是用不着地址码或只用少量的地址码的。那么,就可以把操作码扩展到这些位置。
就这样,慢慢地,CISC指令系统就形成了,大量的复杂指令、可变的指令长度、多种的寻址方式是CISC的特点,也是CISC的缺点:因为这些都大大 增加了解码的难度,而在现在的高速硬件发展下,复杂指令所带来的速度提升早已不及在解码上浪费点的时间。除了个人PC市场还在用x86指令集外,服务器以 及更大的系统都早已不用CISC了。x86仍然存在的唯一理由就是为了兼容大量的x86平台上的软件。
在CISC微处理器中,程序的各条指令是按顺序串行执行的,每条指令中的各个操作也是按顺序串行执行的。顺序执行的优点是控制简单,但计算机各部分的利用率不高,执行速度慢。
RISC(Reduced Instruction Set Computing,精简指令集)
1975年,IBM的设计师John Cocke研究了当时的IBM370CISC系统,发现其中占总指令数仅20%的简单指令却在程序调用中占了80%,而占指令数80%的复杂指令却只有20%的机会用到。由此,他提出了RISC的概念。
RISC体系结构和设计思想是80年代初出现的,RISC与CISC指令系统是完全不同,完全决裂的指令系统。
它的基本思路是:抓住CISC指令系统指令种类太多(其中80%以上都是程序中很少使用的指令)、指令格式不规范、寻址方式太多的缺点(例如,VAX 780的指令操作类型超过1000种,而Alpha只有不到50种指令),通过减少指令种类、规范指令格式和简化寻址方式,大量利用寄存器间操作,大大简化处理器的结构、优化VLSI器件使用效率,从而大幅度地提高处理器性能、并行处理能力和性价比。
事实证明,RISC是成功的。80年代末,各公司的RISC CPU如雨后春笋般大量出现,占据了大量的市场。到了90年代,Intel推出了Pentium处理器,从Pentium pro构架开始,也开始使用一种混合的CISC/RISC构架(注意:这里X86架构上有改变,但仍然是IA-32,是32位处理器,直到AMD推出了X86-64及Intel跟随推出IA-32e之后,才有64位技术)。
RISC的最大特点是指令长度固定,指令格式种类少,寻址方式种类少,大多数是简单指令且都能在一个时钟周期内完成,易于设计超标量与流水线,寄存器 数量多,大量操作在寄存器之间进行。
指令集如何面向开发者?
编写软件,通常用高级语言,C,C++,java,python这种,但是CPU只能识别二进制指令,因此需要一个东西把高级语言代码转化成二进制机器码,也就是编译器,而不同的指令集,需要对应能把高级语言转化成CPU指令的编译器。
汇编语言,就是做编译器的。
指令集可以针对某些方面特化性优化,使得算这些方面相对别的很快。
主频?
主频是CPU一秒钟内改变状态的次数。
举例来说3GHz的主频,一个事情一秒钟需要CPU改变三次状态,那么CPU1秒钟可以做10亿次这种事情。
但是有些架构(指令集)做这件事只需要CPU改变两次状态,所以即使该CPU 2GHz,那么速度也是1秒钟10亿次。
没有查到主频占用率的说法,脑补一下计算机要同时算ABC三个任务,A任务一次需要CPU改变两次状态,B一次,C一次,因此A任务占了一半的主频?
一个形象的说法:
CPU的主频就好比汽车的速度,速度越快,运输的时间越短。同样的,主频越高,完成计算的时间也越短。
但这是对相同架构的CPU来说的,就好比同等载货量的汽车这个结论才是对的。如果是一辆2吨汽车跑80公里,和一辆5吨汽车跑60公里,很显然只有运2吨以下货物,才是80公里的2吨车时间短,否则通常都是5吨车耗时更短。类似的,CPU有一个IPC性能,全称是Instructions Per Clock,每时钟周期指令数量,这个性能如果足够高,是可以弥补频率低的劣势甚至反超的。苹果新出的M1就是一个这样的CPU。
除了载货量本身,为了提高运输速度,还可以用多辆汽车一起运输,电脑上叫多处理器。很显然,4辆跑60公里的2吨汽车,运货通常比2辆80公里的2吨汽车耗时短,除非一次就能全部运完。这就是双路处理器和四路处理器的区别的。
现在很多CPU是多核心,可以理解为一辆车挂多个车厢,很显然挂的车厢越多,运货的时间越短。所以8核CPU比6核性能高,6核比4核性能高…不过挂的车厢多了,往往就跑的慢点。同样的8核CPU往往频率比6核低。
除了CPU本身以外,周边设备也会影响性能。汽车运货也一样,手工装卸货物的,肯定没有用叉车装卸速度快,正如内存性能对CPU性能的影响。
最后,运货时间要看全部因素综合,货车载货量、速度、车厢数量、装卸设备速度等等,光速度快不见得就时间短。同样的,CPU完成一项计算任务要用多长时间,要综合IPC性能、主频、核心数量、内存性能来看,光主频高也是没用的。

若有收获,就点个赞吧
0 人点赞
