论文拆解 计算机视觉 自然语言处理
从TransForm 到 MetaFormer
Transformer 在计算机视觉任务中显示出巨大的潜力。一个共同的信念是他们基于注意力的token mixer模块对他们的能力贡献最大。然而,最近的工作表明,transformers 中基于注意力的模块可以被空间 MLP 取代,并且结果模型仍然表现得相当好。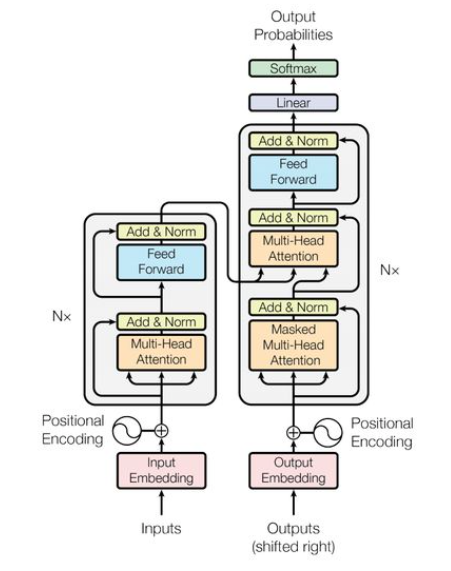
TransFormer示意图
Encoder由两个部件组成。一个是Attention模块,用于在token之间混合信息,我们称之为token mixer。另一个组件包含其余模块,如Channel MLP和剩余连接。最近的一些方法 探索了 MetaFormer 架构中的其他类型的token mixer,并展示了令人鼓舞的性能。有人用傅立叶变换代替了Attention,仍然达到了普通变换器的 97% 左右的准确率。 将所有这些结果放在一起,似乎只要模型采用 MetaFormer 作为通用架构,就可以获得可喜的结果。 因此,我们假设与特定的token mixer相比,MetaFormer 对模型实现竞争性能更为重要。
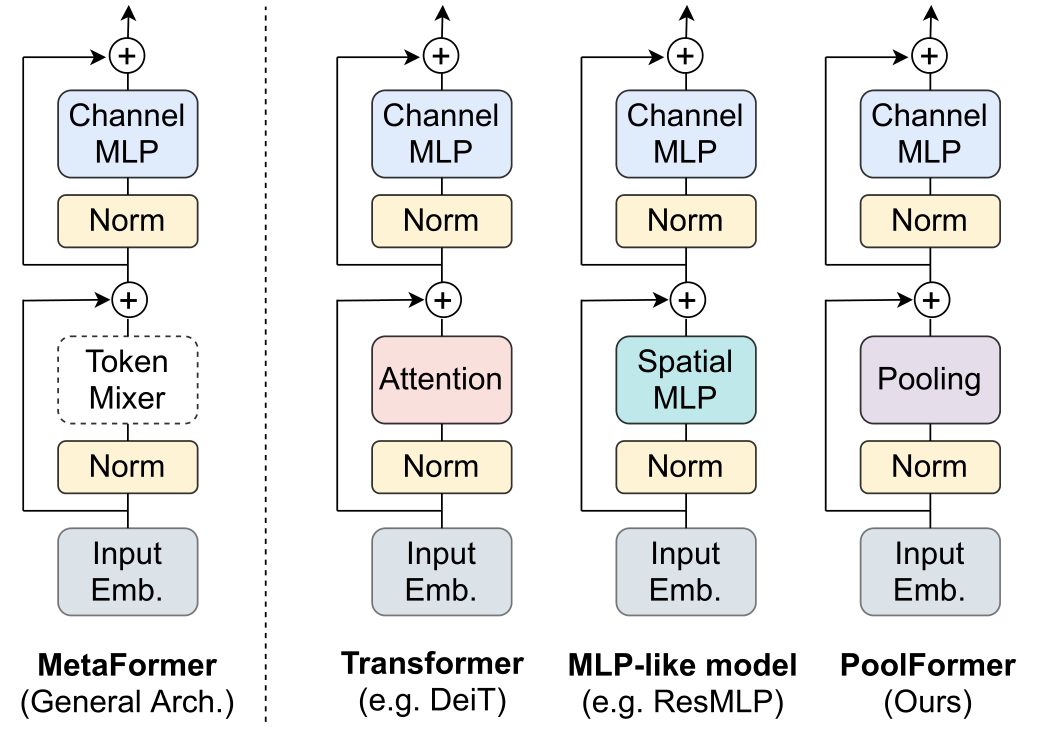
通用模块示意图
Token mixer详解
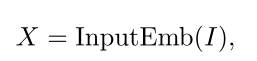
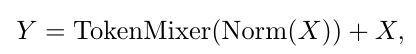
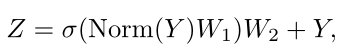
I:输入
Z:本层输出
Norm:归一化函数
σ:非线性激活函数
PoolFormer
从Transformer的介绍开始,许多工作都非常重视Attention,并着重于设计各种基于注意的token mixer组件。相比之下,这些作品很少关注一般的结构,即MetaFormer。
在这项工作中,我们认为,这种MetaFormer通用架构主要有助于近期transformer和MLP类模型的成功。为了证明这一点,我们特意使用了一个非常简单的操作符pooling作为token mixer。Pooling没有可学习的参数,它只是使每个token平均聚合其附近的token特征。
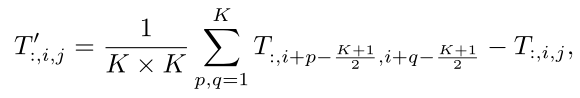
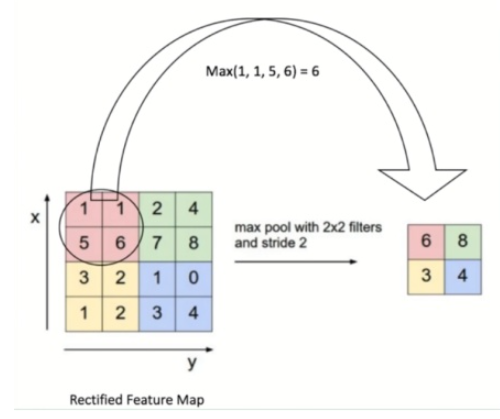
Avgpooling 图解
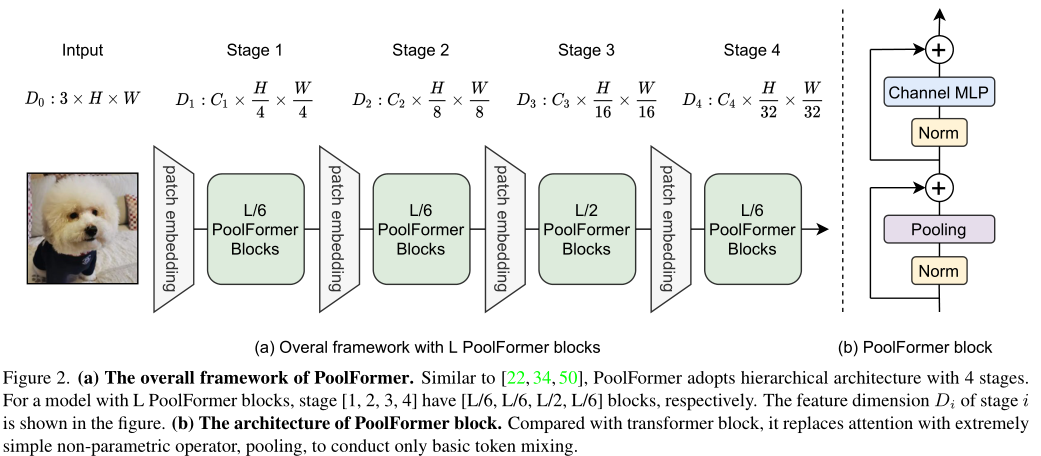
PoolFormer结构
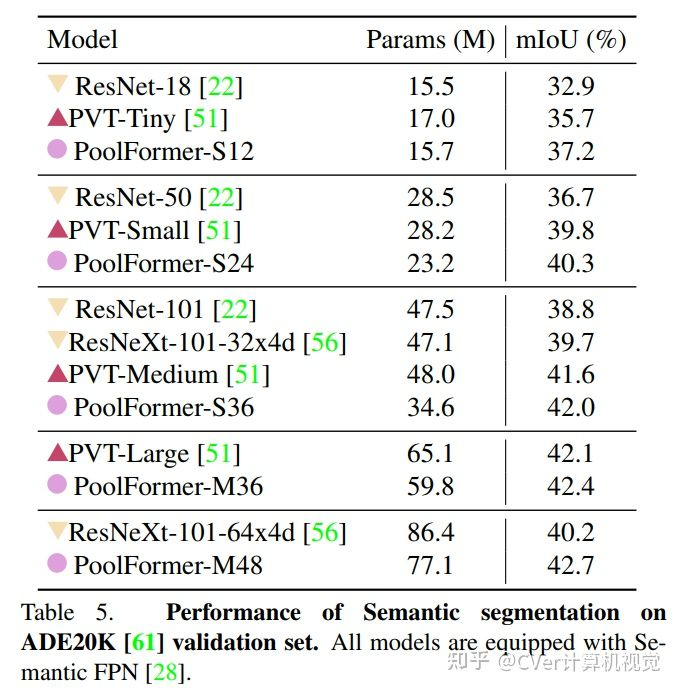
实验结果
例如,在 ImageNet-1K 图像分类上,PoolFormer 实现了 82.1% 的 top-1 准确率,以 35%/52% 的参数减少了 0.3%/1.1% 的准确率,超过了经过良好调整的视觉Transformer/MLP-like 基线 DeiT-B/ResMLP-B24 MAC 减少 48%/60%。
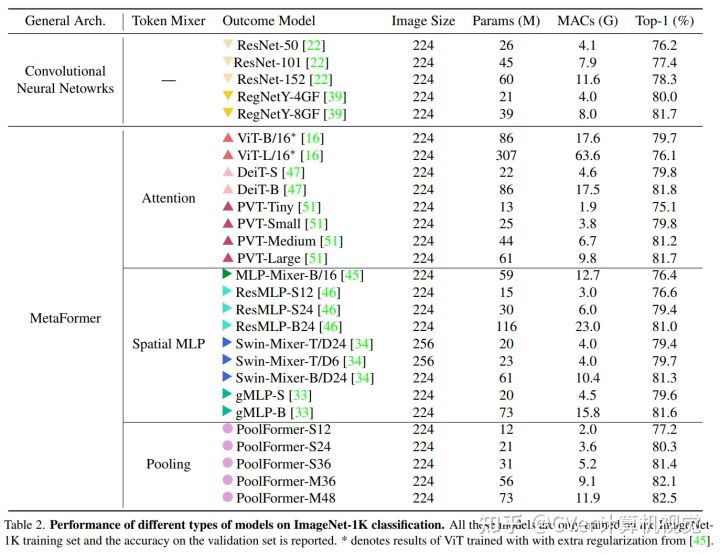
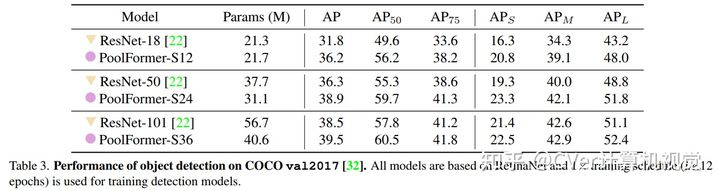
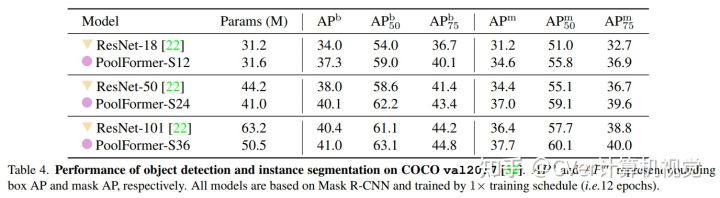

若有收获,就点个赞吧
0 人点赞
