定义
网络中的链路预测(Link Prediction)是指如何通过已知的网络节点以及网络结构等信息预测网络中尚未产生连边的两个节点之间产生链接的可能性。这种预测既包含了对未知链接(exist yet unknown links)的预测也包含了对未来链接(future links)的预测。<br /> 链路预测是属于数据挖掘方向的。属于图挖掘范畴。<br /><br /> 构成图最重要的两个东西,**节点(node)**,**关系(relation)**。当一个结构:**node--relation--node**出现的时候,就组成了图结构的最基本的单位。node, relation都可以有自己的**属性(property)**。property这个东西是一个很神奇的东西,基本上所有的信息都保存在property里面,不仅如此,有时候可以**把某些类型的关系与节点中的,某些属性单独提取出来作为一种新的类型的关系或者节点**<br /> 简单的说,就是在已知的结构中,预测现在不相连的节点,是否相连。
算法简述
基于马尔科夫链和机器学习
Sarukkai应用马尔科夫链进行网络的链路预测和路径分析。
R. R. Sarukkai, Link prediction and path analysis using markov chains, Computer Networks 33 (2000) 377.
Zhu等人将基于马尔科夫链的预测方法扩展到了自适应性网站(adaptive web sites)的预测中。
J. Zhu, J. Hong, J. G. Hughes, Using markov chains for link prediction in adaptive web sites, Lect. Notes Comput. Sci. 2311 (2002) 22.
属于应用节点属性的链路预测。
虽然应用节点属性等外部信息的确可以得到很好的预测效果,但是很多情况下这些信息的获得是非常困难的,甚至是不可能的。比如很多在线系统的用户信息都是保密的。另外即使获得了节点的属性信息也很难保证信息的可靠性,即这些属性是否反映了节点的真实情况,例如在线社交网络中很多用户的注册信息都是虚假的。更进一步,在能够得到节点属性的精确信息的情况下,如何鉴别出哪些信息对网络的链路预测是有用的,哪些信息是没用的仍然是个问题。因此与节点属性信息相比较,已观察到的网络结构或者用户的历史信息更容易获得也是更可靠的。
基于最大似然估计
Clauset, Moore和Newman[31]认为很多网络的连接可以看作某种内在的层次结构的反映,基于此,他们提出了一种最大似然估计的算法进行链路预测,这种方法在处理具有明显层次组织的网络,如恐怖袭击网络和草原食物链,具有较好的精确度。<br /> 但是,由于每次预测要生成很多个样本网络,因此其计算复杂度非常高,只能处理规模不太大的网络。Guimera和Sales-Pardo[14]假设我们观察到的网络是一个随机分块模型(Stochastic Block Model)[32]的一次实现,在该模型中节点被分为若干集合,两个节点间连接的概率只和相应的集合有关。<br />[14] R. Guimera, M. Sales-Pardo, _Missing and spurious interactions and the reconstruction of complex networks_, Proc. Natl. Sci. Acad. U.S.A. 106 (2009) 22073.<br />[31] A. Clauset, C. Moore, M. E. J. Newman, _Hierarchical structure and the prediction of missing links in networks_, Nature 453 (2008) 98.<br />[32] P. W. Holland, K. B. Laskey, S. Leinhard, _Stochastic blockmodels: First steps_, Social Networks 5 (1983) 109.
基于节点相似性
此方法的一个重要前提假设就是两个节点之间相似性(或者相近性)越大,它们之间存在链接的可能性就越大。因此如何定义节点的相似性就成为该方法的一个核心问题。<br /> 相似性既可以是非常简单的共同邻居的个数,也可以是包含了复杂数学物理内容的诸如随机游走的平均通讯时间[21]或者是基于图论的矩阵森林方法 [22]。因此这个简单的框架事实上提供了无穷无尽的可能性。<br />[21] F. Fouss, A. Pirotte, J.-M. Renders, M. Saerens, _Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation_, IEEE Trans. Knowl. Data. Eng. 19 (2007) 355.<br />[22] P. Chebotarev, E. Shamis, _The matrix-forest theorem and measuring relations in small social groups_, Automat. Remote Contr. 58 (1997) 1505.<br />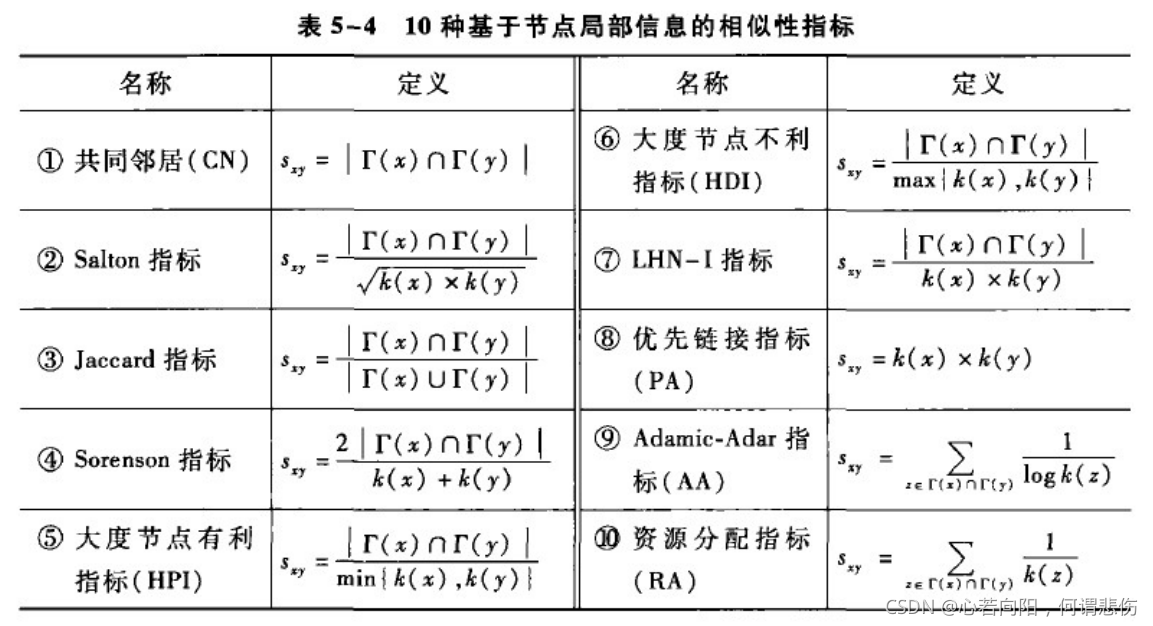
应用领域
- 社交网络应用,例如:好友推荐
- 电商领域应用,例如:商品推荐
- 生物学应用,例如:蛋白质结构探索

若有收获,就点个赞吧
0 人点赞
