

自动驾驶 ;机器学习;深度学习;神经网络;计算机视觉;图像识别;监督学习;数据融合;特斯拉 FSD
why?
自动驾驶的优势
人类驾驶一辆车,反应时间通常需要250毫秒;观察周围交通环境通过旋转头部看后视镜判断;同时人的精力有限,难免出现注意力不集中的现象;当机器在驾驶时,反应时间通常小于100毫秒,拥有360度的感知能力,同时机器永远不会累。
为什么纯视觉
很多自动驾驶车辆在车顶装上昂贵的激光雷达,就能够感知360度的环境,并测量距离。不过,如果要使用激光雷达,还需要高精地图的匹配。根据高精地图存储的车道线、红绿灯等信息,实现自动驾驶,然而打造一套全球范围的高精地图并不现实。自动驾驶框架

智能驾驶的关键技术是环境感知技术和车辆控制技术,其中环境感知技术是无人驾驶汽车行驶的基础,车辆控制技术是无人驾驶汽车行驶的核心,包括轨迹规划和控制执行两个环节,这两项技术相辅相成共同构成智能驾驶汽车的关键技术。
智能驾驶的整个流程归结起来有三个部分:
- 通过雷达、像机、车载网联系统等对外界的环境进行感知识别;
- 在传感感知融合信息基础上,通过智能算法学习外界场景信息,规划车辆运行轨迹,实现车辆拟人化控制融入交通流中;
跟踪决策规划的轨迹目标,控制车辆的油门、刹车和转向等驾驶动作,调节车辆行驶速度、位置和方向等状态,以保证汽车的安全性、操纵性和稳定性。
如果能够默契地进行,那么整个智能驾驶流程就算完成了。因此研究自动驾驶的控制技术变得具有十分重要的意义。
智能驾驶的系统将驾驶认知形式化,利用驾驶认知的图表达语言,设计通用的智能驾驶软件架构。在这一架构中,智能决策模块并不直接与传感器信息发生耦合,而是基于多传感器的感知信息、驾驶地图和车联网通信等先验信息综合形成的驾驶态势完成自主决策。智能驾驶试验平台软件运行流程:
多传感器信息处理模块,由驾驶认知的图表达语言统一输出构成驾驶态势实时信息;
- 驾驶地图的信息,则根据车辆实时位置及朝向,映射到驾驶态势中,与驾驶态势实时信息融合,形成全面反映当前驾驶态势的公共数据池;
- 车联网通信信息,利于 V2X 系统使得车与车、车与基站之间能够通信互联,获得周边交通流实时路况、路口标识、交通灯标示信息以及来自外部云服务器的超视距路况信息;
决策控制模块,以这行驶环境信息数据池为基础,综合考虑交通规则、驾驶经验、全局路径等先验知识,完成决策。
此外,融合了实时信息与先验知识的行驶环境信息数据池,也能够帮助传感器信息处理模块确定感兴趣区域、帮助定位模块提高定位准确性、帮助驾驶地图模块及时更新先验信息,提升智能驾驶的性能。
[
](https://blog.csdn.net/hhaowang/article/details/97406480)
特斯拉
Model 3 ,Model Y 车辆的辅助驾驶 AutoPilot 系统—8 个环绕车身并能够覆盖 360° 的摄像头技术路线
纯视觉感知—路况信息、距离、速度、加速度
当人类驾驶时,人眼所看到的画面也是2D的,但是人脑的神经网络能够计算出距离。因此,如果机器的神经网络模拟人脑,也就能够计算出深度、速度、加速度。例如,在拥堵路段,前方车辆走走停停,距离、速度、加速度都会实时变化,如果能够始终追踪正前方的车辆,判断将会非常精准。但是毫米波雷达并非如此,毫米波雷达的感知具有比较大的随机性,可能感知到其他物体,并产生一个错误数据。纯视觉感知的3个需求: 1. 大量的视频数据,百万段规模的视频; 2. 干净的数据,包括对物体标签化,并且拥有深度、速度、加速度信息; 3. 多样化的数据,大量的边缘案例。
数据标签化:
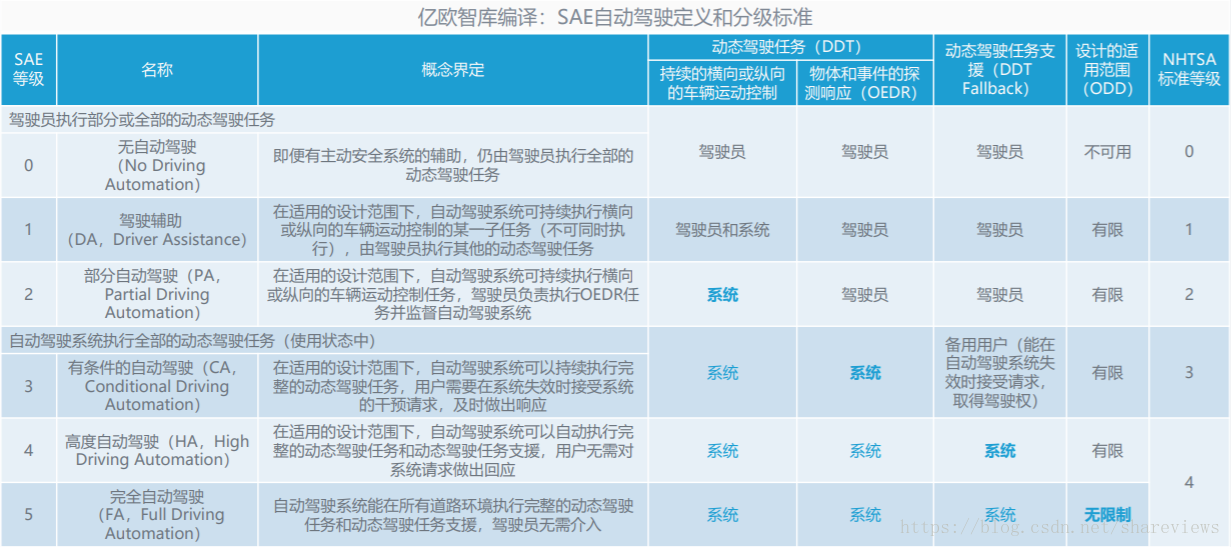
特斯拉自动数据标签化
采用数据自动标记数据的方法,当车辆感知周围环境后,用自动驾驶电脑本地处理数据。上传至服务器之后,如有不精准之处,也能用人工的方式清理、验证数据
特斯拉总结的221项数据收集触发条件(部分)
在实际使用中,特斯拉的自动标签化的方法还能够应对沙尘、雨、雾、雪等极端天气。在过去四个月时间里,特斯拉的研发人员总结出了221个收集数据的触发条件,Andrej在演讲中展示了其中一部分,其中包括视觉、雷达传感器不匹配,视频出现抖动,监测到画面闪烁等等。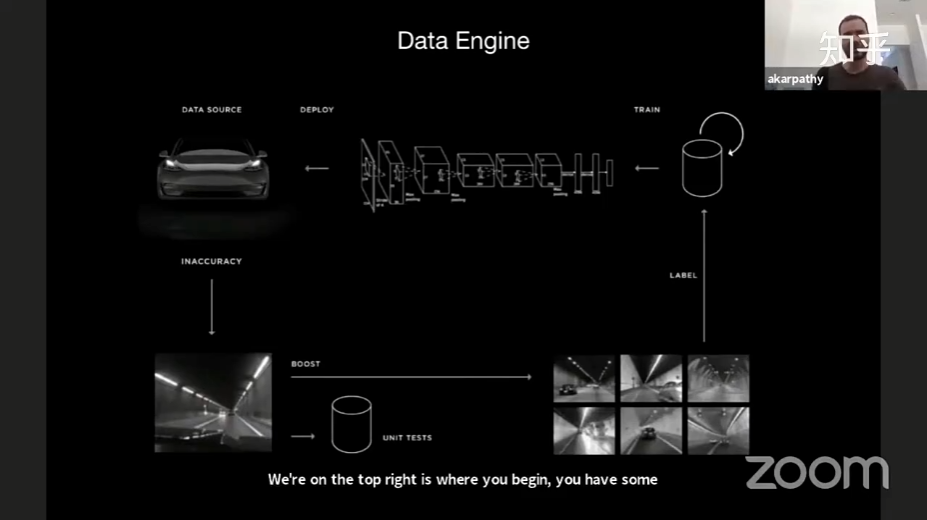
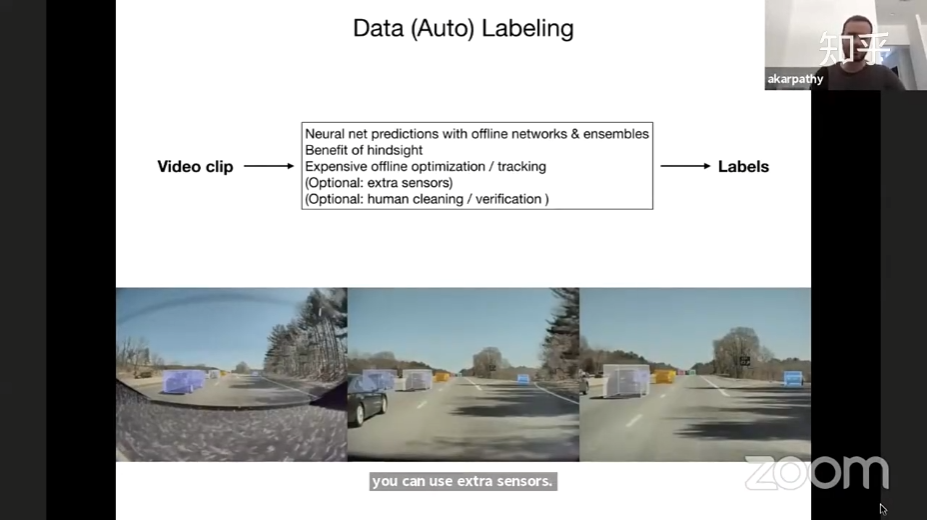
特斯拉数据引擎
在过去四个月时间里,特斯拉完成了广泛的数据收集,最终在特斯拉数据引擎中完成了七种影子模式和七个循环的验证。“最开始,我们用视频数据集训练神经网络,训练之后分发到特斯拉汽车的影子模式中。在车辆端,需要不断验证神经网络的准确性。如果在行驶中出现了221个触发条件中的一个,系统就会自动收集视频片段,自动标签化物体之后合并至一个训练集中。我们一遍又一遍重复这个循环,让神经网络变得越来越好。”
特斯拉数据集
在完成七轮影子模式的循环验证之后,特斯拉一共处理了100万条10秒短视频,这些视频全部来自特斯拉车身拍摄的画面。同时,特斯拉为60亿个物体做了标签化处理,同时包含精准的深度和速度信息。这些数据一共有1.5PB网络结构—数据融合
网络结构
在框图上部,摄像头感知的画面输入,图像解压后就会进行数据融合处理。首先会在摄像头上融合信息,然后在所有时间上融合信息。利用Transformer架构、循环神经网络,或者直接用3D卷积,都能够取得很好的效果。在融合完成之后,又会形成分支,分离成为主干,再次分离形成终端。分离成终端是因为研发人员可能对大量的输出结果感兴趣,但是不可能用一个神经网络单独输出每一项结果。同时,分支结构的另一个好处是它在终端解耦所有信号,所以当研发人员正在处理特定对象的速度、加速度等信息时,就能够拥有小神经网络,不用触及其他信号就能完成工作。使用上述方案,特斯拉能够规避「突然减速」等问题和基于雷达的系统的信号中断,提供平稳的驾驶状态。
如何运行、训练大量的数据?
任务
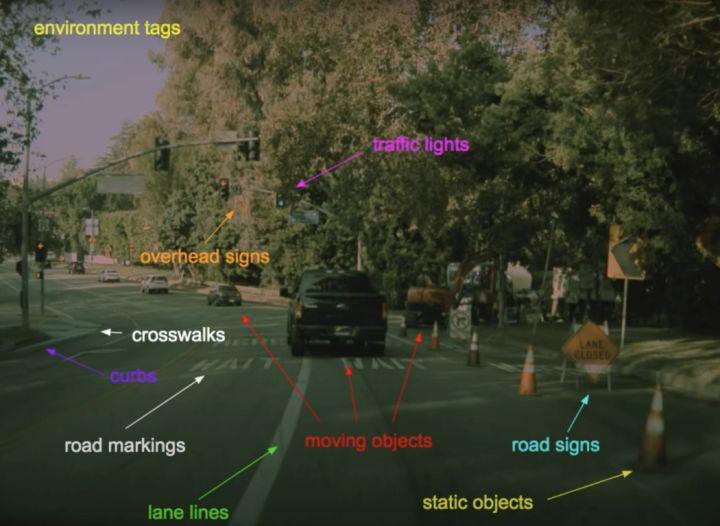
- 每个尺寸(1280,960,3)的图像都通过这个特定的神经网络。
- 主干是一个修改过的ResNet 50 ——具体的修改是使用“空洞卷积”。
- 这些头基于语义分割—— FPN/DeepLab/UNet 架构。然而,它似乎不是“最终任务” ,因为2D 像素和3D 之间的转换很容易出错。
有些任务在多个摄像头上运行。例如,深度估计是我们通常在双目摄像头上做的事情。拥有两个摄像头有助于更好地估计距离。特斯拉使用神经网络进行深度回归来做这件事。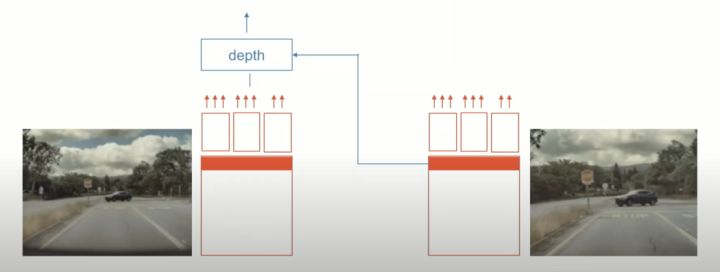

可选地,这个神经网络可以是循环的,因此它涉及到时间。
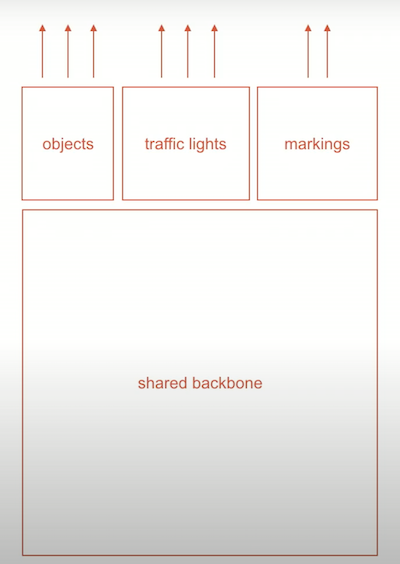
这意味着每向前传递一次,就有4096张图像被处理。为了解决这个问题,特斯拉在 HydraNet 架构上下了大赌注。每个摄像头都是通过一个单一的神经网络处理的。然后将所有的信息组合成中间神经网络。令人惊奇的是,每一个任务只需要这个庞大网络的一小部分。例如,目标检测只需要前置摄像头,前面的主干和第二个摄像头。当然不是所有的任务都按同样的方式处理。特斯拉的主要问题是,它使用8个摄像头,16个时间步长(循环架构) ,batch size为32

训练
网络训练用的是 PyTorch。需要多个任务,并且要花费大量的时间来训练所有48个神经网络头。事实上,训练需要GPU 70,000小时才能完成,差不多是8年。特斯拉正在改变训练模式,从“轮询”(round robin)到“工人池”(pool of workers)。idea是: 下面左边—— 一个漫长而不可能的选择。中间和右边,是他们使用的替代品。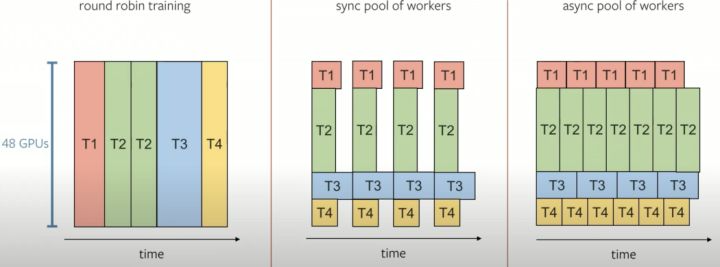
小结
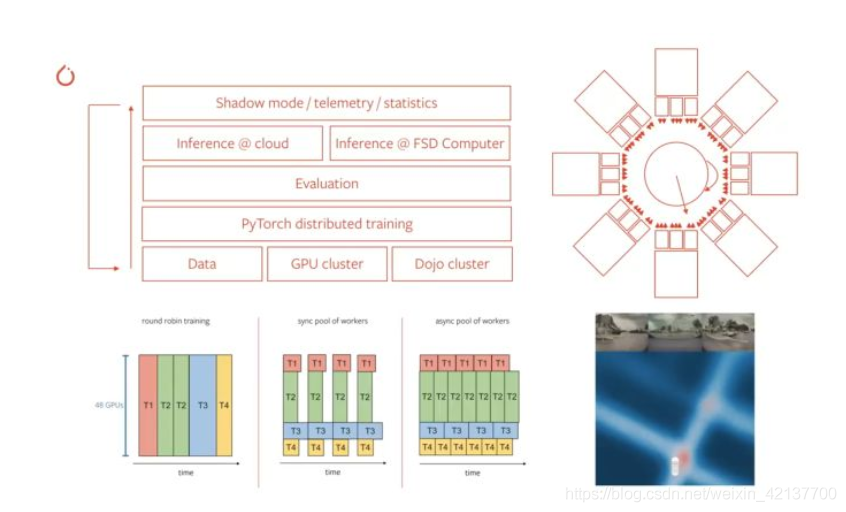 从下到上:
从下到上:
- 数据——特斯拉从这些车辆中收集数据,并由一个团队给数据打上标签。
- GPU 集群—— Tesla 使用多个 GPU (称为集群)来训练和运行它们的神经网络。
- DOJO ー Tesla 使用一种他们称之为 DOJO 的东西来训练整个架构的一部分来完成特定的任务。这和他们在推理中所做的非常相似。
- 分布式训练ーー特斯拉使用 PyTorch 进行分布式训练。
- 评估——特斯拉用损失函数评估网络训练。
- 云计算推断——云计算处理允许特斯拉同时改进其车队。
- 推理@FSD ——特斯拉制造了自己的计算机,拥有自己的神经处理单元(NPU)和用于推理的GPU。
- 影子模式——特斯拉从车辆中收集结果和数据,并将它们与预测进行比较,以帮助改进标注: 这是一个闭环系统!
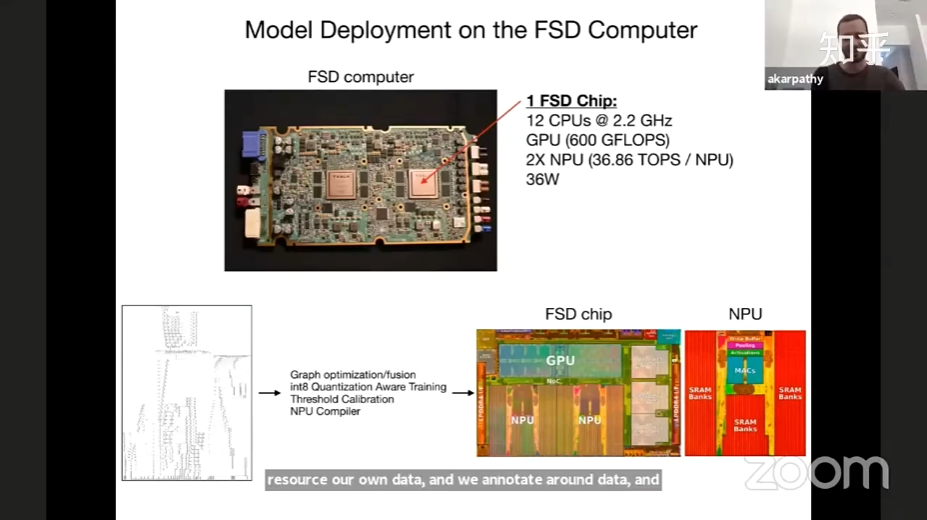
硬件环境—算力

特斯拉超级计算机
要处理如此多的数据,特斯拉搭建了一个世界排名第五的超级计算机。这个集群使用了720个节点,每个节点8个英伟达A100 Tensor Core GPU(共5760个GPU),实现了1.8 exaflops的性能。采用10PB NVME存储,读写速度能够达到1.6TB/s。未来,特斯拉会让这台超级电脑运行Dojo项目,特斯拉希望通过Dojo不断训练其神经网络,帮助特斯拉Autopilot不断进化。特斯拉超级计算机Dojo(Dogo:日语直译为道场,意译为训练场)。在马斯克的规划中,Dojo超级计算机的算力要达到每秒钟exaFLOP的级别,也就是百亿亿次浮点运算,是现在的一万倍。
结果
发布和验证
前方车辆快速刹车时,视觉传感器和毫米波雷达出现了截然不同的表现。
图中黄色线条代表毫米波雷达感知的距离、速度、加速度图像(从上至下),蓝色线条代表纯视觉传感器的感知结果。可以发现,毫米波雷达在其中有多次出现距离突然降低为0、速度突然提升、加速度突然为0的情况。这是因为突然减速之后,毫米波雷达并不能很好追踪前方车辆,因此多次重启,就像是车辆在短时间内重复消失,又出现了6次,这很可能误导自动驾驶系统。 由纯视觉传感器感知的信息和毫米波雷达的信息大致重合,但是没有出现距离、速度、加速度突变的情况,表现非常稳定
从下到上:
- 数据——特斯拉从这些车辆中收集数据,并由一个团队给数据打上标签。
- GPU 集群—— Tesla 使用多个 GPU (称为集群)来训练和运行它们的神经网络。
- DOJO ー Tesla 使用一种他们称之为 DOJO 的东西来训练整个架构的一部分来完成特定的任务。这和他们在推理中所做的非常相似。
- 分布式训练ーー特斯拉使用 PyTorch 进行分布式训练。
- 评估——特斯拉用损失函数评估网络训练。
- 云计算推断——云计算处理允许特斯拉同时改进其车队。
- 推理@FSD ——特斯拉制造了自己的计算机,拥有自己的神经处理单元(NPU)和用于推理的GPU。
- 影子模式——特斯拉从车辆中收集结果和数据,并将它们与预测进行比较,以帮助改进标注: 这是一个闭环系统!
现状
如今自动驾驶在全球范围内已经进入了快速发展期,但L1级仍是ADAS(高级驾驶辅助系统)量产主力,未来2~3年L2将会是量产的主力。梁锋华表示,曾经汽车豪华品牌都是从国外往中国过渡,现状自动驾驶行业,中国绝对是主力。今年中国L2的搭载量预计突破80万,中国品牌占据绝大部分份额。而L3-L4级自动驾驶系统还处于研发和小规模测试阶段。 百度Apollo:公布了一套自动驾驶纯视觉城市道路闭环解决方案——百度Apollo Lite。Apollo Lite是目前国内唯一的城市道路L4级视觉感知解决方案,能够支持对10路摄像头、200帧/秒数据量的并行处理,单视觉链路最高丢帧率能够控制在5‰以下,实现全方位360°实时环境感知,前向障碍物的稳定检测视距达到240米。 威马:威马汽车通过线上的形式发布了ldea L4全新科技战略目标,目的在于实现“人-车-环境”相互融合的智能科技生态圈。对于出身在华夏大地的威马汽车,中国品牌对国内主要城市道路会更为熟悉,加上威马汽车与百度联手,也成为了首个应用Apollo前沿技术的新能源品牌。威马汽车将会逐步下放L4级别的自动驾驶技术,推动高级自动驾驶前装量产,使L2+级自动驾驶逐步成长为L4级别。 华为:华为自动驾驶技术的北汽新能源极狐阿尔法S,在上海进行了公开试乘。试乘的视频可以看出来,自动驾驶过程中十分顺畅,成熟度较高,能够做到在闹市无干预自动驾驶一千公里,具备了 L4 级别能力。配置3个激光雷达(左前、右前以及中间)、13个摄像头、6个毫米波雷达、1个车顶惯导、1个域控制器。 阿里巴巴:阿里达摩院自主研发出了一款用于车载摄像头的ISP处理器,每秒可处理200万像素图像,且可同时支持6个摄像头传输的数据。因此,搭载了该处理器的车载摄像头能够在夜间“看”的更为清晰。阿里自动驾驶走的是多传感器融合的方案,包括激光雷达、摄像头、毫米波雷达、惯导等。目前,该产品已应用在阿里自动驾驶物流场景中。围绕物流场景,以L4级自动驾驶为切入点,通过车路协同和单车智能协调发展,阿里正在打造自己的自动驾驶版图。参考文献
https://www.youtube.com/watch?v=NSDTZQdo6H8
https://blog.csdn.net/shareviews/article/details/83028038?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-5.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-5.control
https://baijiahao.baidu.com/s?id=1637189730551992846&wfr=spider&for=pc

若有收获,就点个赞吧
0 人点赞
