人工智能,机器学习,开发应用,边缘智能
简介
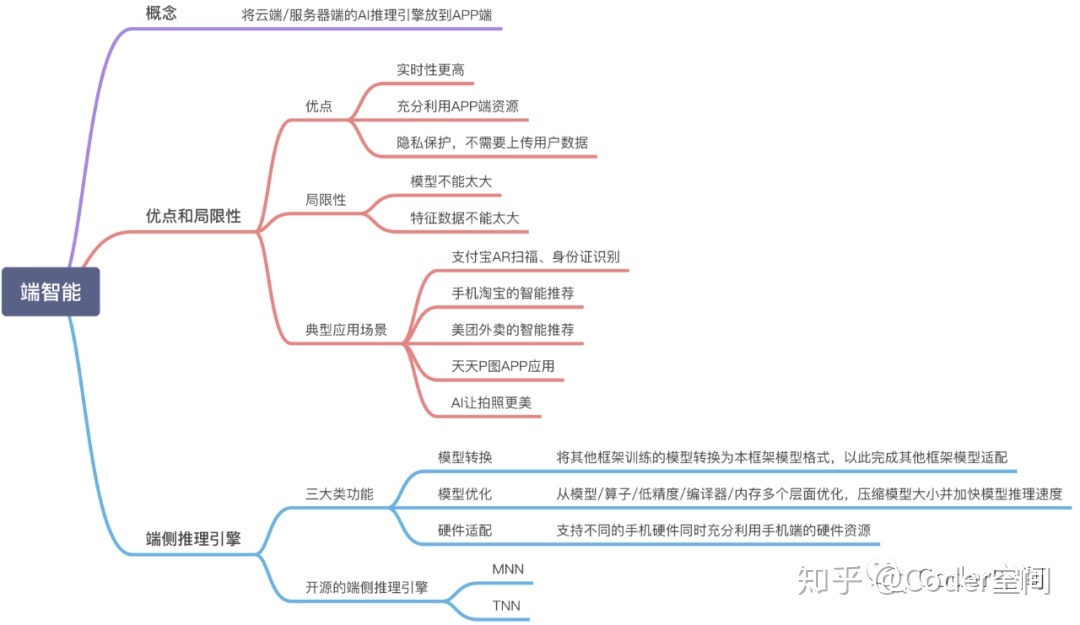
端智能(On-Device Machine Learning)是指把**机器学习的应用**放在端侧做。**这里的“端侧”,是相对于云服务而言的。**可以是手机,也可以是IOT设备等等。
端智能发展契机
端侧设备在算力,算法及框架有了突飞猛进的发展:
- 算力:CPU、GPU 性能提升,手机算力不断增长,以及专门用于 AI 的神经网络处理芯片逐渐成为标配,已经能够不同程度上支持算法模型的运行;
- 框架:面向移动端的机器学习框架的诞生让我们能更轻松的在端侧应用机器学习。在手机侧,Apple 的 Core ML,Google 的 NNAPI 提供了系统级别的支持,除此之外业内也有很多优秀的端侧框架:TensorFlow Mobile/Lite、Caffe2、NCNN、TNN、MACE、Paddle&Paddle Lite、MNN 及 Tengine 等;
- 算法:模型压缩技术不断发展,其中量化已经非常成熟,基本能够实现在不降低精度的情况下将模型缩小为原来的 1/4~1/3;此外,针对端侧的算法模型在不断的优化过后,架构设计变得越来越成熟,对于端侧设备的兼容性也愈加友好。
为什么要用端智能?
模型可以放到端上跑,不一定代表它必须要放到端上跑。那我们为什么一定要做端智能呢?**端智能相比云端智能具有低延时,保护数据隐私,节省云端计算资源等优势。**
- 低延时,一些场景有很强的实时性。比如Snapchat中的人脸贴纸功能,需要对视频流的每一帧进行处理,然后渲染。这就要求图像处理的模型(例如人脸关键点的检测模型)运行在端上。
- 数据隐私,中国对于数据隐私性的重视在加强,国外就更不用说了,例如欧洲有极其苛刻的数据隐私保护法律。而端智能可以做到数据不离端而进行推理甚至模型训练,相比于云端机器学习有天然的隐私性优势。
- 算力,一组数据比对:2018年,世界上最快的计算机“Summit”的算力是143.5 PFLOPS . 而在2018年,华为卖出了1700万台P20 。每台P20中的麒麟970 NPU的算力是1.92 TFLOPS 。这些NPU合起来的算力就有32640 PFLOPS,相当于227个“Summit”。端侧设备的算力不容小觑。可以说,它是一个算力的海洋。
一些缺点:
当然,端智能并非万金油,必然有一些缺点:
- 设备资源有限,端侧算力、存储是有限的,不能做大规模高强度的持续计算。
- 算法规模小,端侧算力小,而且单用户的数据,在算法上并不能做到最优。
- 用户数据有限,端侧数据不适合长期存储,同时可用数据有限。
流程
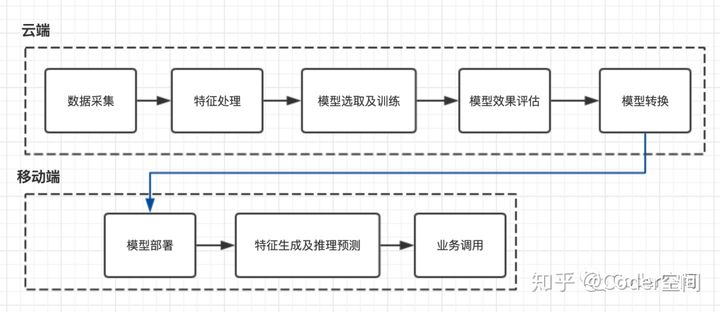
一套完整的“端智能”体系是需要很多基础设施的,比如说:数据埋点和用户数据采集,构建特征工程,模型分布式训练, 端侧推理引擎的优化等等。当智能基础能力的基建做好了,要把智能能力应用到业务上时,需要的更多则是业务理解和周边功能的完善了。**“端”作为智能化的最后一环,主要是使用AI推理引擎完成模型推理**。目前国内比较热门的端侧推理引擎就是阿里MNN及腾讯TNN。这类端侧推理框架主要完成三大类功能:
- 模型转换(model converter),将其它框架训练好的模型转换为本框架模型格式。
- 模型优化(model optimization),从模型/算子/低精度/编译器/内存多个层面优化,压缩模型大小,加快模型推理速度。
- 硬件适配(heterogeneous computing),支持不同的手机硬件,同时充分利用手机端的硬件资源。
阿里MNN

这是 MNN 整体架构图,左边离线部分包含模型转换和模型压缩,将各种训练框架模型转换成 MNN 的模型;右边是线推理部分,MNN 目前支持 CPU,以及 GPU 对应的 OpenCL,Vulkan 等 backend 。以图上为例, Pixel 2 手机支持 CPU ARM 和 Vulkan backend ,小米6支持 CPU ARM,OpenCL , Vulkan backend ,Mate20 支持 ARM82 架构的 CPU backend,以及 OpenCL , Vulkan backend 。在预推理环节,**根据模型结构信息,以及设备的硬件信息找到一种最快运行方式。**比如Pixel2上使用CPU和 Vulkan运行,小米6使用CPU和OpenCL运行,Mate20上使用ARM82指令和 OpenCL运行。这是粗粒度的 CPU和 GPU运行方式选择,更细一点比如同样 CPU运行,有winogrand,strassion矩阵计算算法会根据模型和硬件特性选择不同分块,这样实现最快运行。
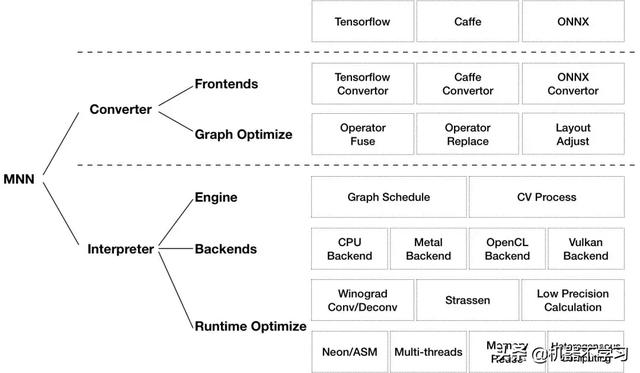
Github上的图,如图所示,MNN 可以分为 Converter 和 Interpreter 两部分。Converter 由 Frontends 和 Graph Optimize 构成。前者负责支持不同的训练框架,MNN 当前支持 Tensorflow(Lite)、Caffe 和 ONNX;后者通过算子融合、算子替代、布局调整等方式优化图。Interpreter 由 Engine 和 Backends 构成。前者负责模型的加载、计算图的调度;后者包含各计算设备下的内存分配、Op 实现。在 Engine 和 Backends 中,MNN应用了多种优化方案,包括在卷积和反卷积中应用 Winograd 算法、在矩阵乘法中应用 Strassen 算法、低精度计算、Neon 优化、手写汇编、多线程优化、内存复用、异构计算等。
腾讯TNN
TNN对2017年开源的ncnn框架进行了重构升级。通过GPU深度调优、ARM SIMD深入汇编指令调优、低精度计算等技术手段,在性能上取得了进一步提升。

以下是MNN, ncnn, TNN框架在多款主流平台的实测性能:
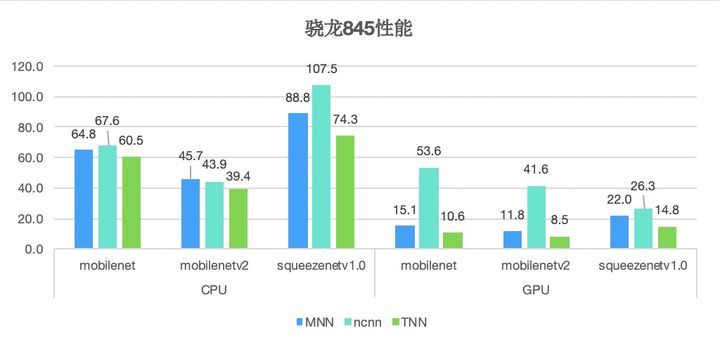
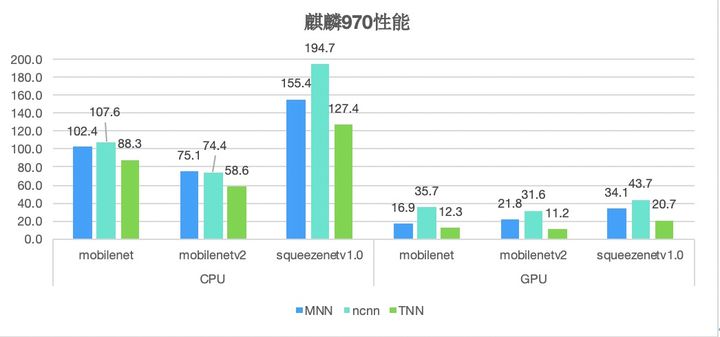
低精度计算的运用对TNN的性能提升发挥了重要作用。
在神经网络计算中,浮点精度被证明存在一定冗余,而在计算、内存资源都极为紧张的移动端,消除这部分冗余极为必要。TNN引入了INT8、 FP16、 BFP16等多种计算低精度的支持,相比大部分仅提供INT8支持的框架,不仅能灵活适配不同场景,还让计算性能大大提升。TNN通过采用8bit整数代替float进行计算和存储,模型尺寸和内存消耗均减少至1/4,在计算性能上提升50%以上。同时引入arm平台BFP16的支持,相比浮点模型,BFP16使模型尺寸、内存消耗减少50%,在中低端机上的性能也提升约20%。
通用、轻便是TNN框架的另一大亮点。
长久以来,不同框架间的模型转换都是AI项目应用落地的痛点。TNN设计了与平台无关的模型表示,为开发人员提供统一的模型描述文件和调用接口,支持主流安卓、iOS等操作系统,适配CPU、 GPU、NPU硬件平台。企业一套流程就能部署到位,简单易用、省时省力。同时, TNN通过ONNX可支持TensorFlow, PyTorch, MXNet, Caffe等多种训练框架,目前支持ONNX算子超过80个,覆盖主流CNN网络。TNN所有算子均为源码直接实现,不依赖任何第三方,接口易用,切换平台仅需修改调用参数即可。
端智能与边缘计算
边缘计算包括边缘智能,端智能属于边缘智能的范畴。边缘智能应该是充分利用终端设备、边缘节点和云数据中心层次结构中可用数据和资源的范例,从而优化DNN模型的整体训练和推理性能。这表明边缘智能并不一定意味着DNN模型完全在边缘训练或推理,而是可以通过数据卸载以cloud-edge-device协作的方式来工作。
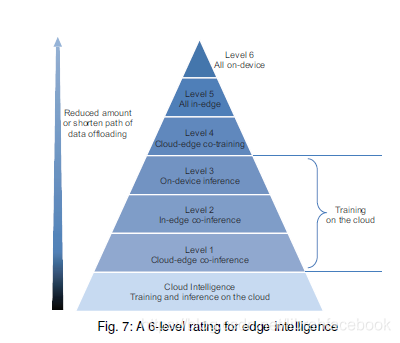
根据数据卸载的数量和路径长度,将边缘智能分成6个等级。
- 云智能(完全在云中训练和推理DNN模型)
- Level-1(Cloud-Edge协作推理和Cloud训练)
- Level-2(In-Edge协作推理和Cloud训练)
- Level-3(On-Device推理和Cloud训练) 端智能
- Level-4(Cloud-Edge协作训练和推理)
- Level-5(In-Edge训练和推理)
Level-6(On-Device训练和推理)
当边缘智能的等级越高,数据卸载的数量和路径长度会减少,其传输延迟也会相应减少,数据隐私性增加,网络带宽成本减少。然而,这是通过增加计算延迟和能耗的代价来实现的。
端智能与5G
端智能的一个特色是离线,因此单独讨论端智能和5G的话,是没有什么关联的,甚至可以说是冲突的。但是,**5G 的高速连接和超低时延,目的在于帮助规模化实现分布式智能,也就是云-端智能一体化。**具体解释如下:5G 给端和云之间的连接提供了更稳定,更无缝的的支撑,此时网络就不再是端云互通的瓶颈了,但**伴随万物互联时代的到来,数据规模将会进一步暴增,进入超大数据规模的时代,此时服务端的算力就会成为瓶颈,那么此时在端侧对于数据的预处理和理解也就更加重要,这就需要端智能的介入。**
落地案例
淘宝-手淘
目前,MNN 已经在手淘、猫客、优酷、聚划算、UC、飞猪、千牛等20+集团App中集成,在拍立淘、直播短视频、互动营销、实人认证、试妆、搜索推荐等场景使用,每天稳定运行上亿次。2018年双十一购物节中,MNN 也在猫晚笑脸红包、扫一扫明星猜拳大战等场景中使用。
腾讯
TNN已于2020年3月中旬在腾讯内部开源,为腾讯QQ、QQ空间、腾讯微视、腾讯云、天天P图等多款产品和服务中持续提供技术能力,释放出更多效能。腾讯优图实验室副总经理吴永坚介绍,腾讯优图后续将在现有CV业务的基础上研发更多的AI推理模型,如语音、NLP等相关业务,同时开展针对CPU、GPU服务器端的服务,为业界公司提供更广泛的优化服务。
字节跳动-西瓜视频
**借助端智能对视频预加载进行优划。**作为西瓜视频的核心场景,其播放体验至关重要。为了实现较好的视频起播效果,该场景上了视频预加载策略:在当前视频起播后,预加载当前视频后的 3 个视频,每个 800K。上述方案足够粗暴简单,但也存在不少局限,即带宽和播放体验平衡不够:某些情况下用户不会看完 800K 的缓存视频,简单浏览标题或前几秒内容后就划到下一个,造成带宽浪费;或者当用户想要认真观看视频时,有可能因为没有足够的缓存,容易导致起播失败或者卡顿,进而影响用户体验。此外上线预加载方案的时候,数据分析师也提到:减少预加载大小虽然可以降低成本,但是卡顿劣化严重,短期采用 3*800K 的固定方案,长期推动动态调整预加载大小方案上线。不难发现,最理想的预加载策略就是使预加载大小和播放大小尽量的匹配,用户在起播阶段会看多少,就预加载多少,这样既能提高播放体验,又能减少带宽浪费。那如何来做呢?基于端侧 AI 的能力,对用户操作行为进行实时分析,进而实现调整预加载策略,在提高用户播放体验的同时,避免带宽浪费。
趋势
这两年有一个明显趋势就是深度学习从实验室往产业落地方向演进,海量终端设备成为落地最佳载体,手机是覆盖用户最多的设备,很容易做到规模化应用。除了这个大的趋势,影响端智能演进还有三个关键要素,分别是**算力、算法和场景**。
- 算力:手机的算力不断增长,每年 CPU/GPU 性能也有非常大的提升, NPU 更是已经成为标配,并且有数量级上性能提升。
- 算法:模型压缩技术不断成熟,其中量化已经非常成熟,基本可以实现不降低精度的情况下将模型缩小为 1/4 甚至更小,另外小模型的架构设计也越来越成熟,面向移动端的各种网络模型不断出现,面向移动终端有限资源的算法模型设计也逐步成熟。
- 场景:就手机本身来说,AI 成为手机的热点和卖点,像 AI 摄像,人脸解锁等已经成为手机的基础功能。从 App 应用场景来说,近来刷爆我们朋友圈的应用都是跟 AI 相关的,有 Face App ,垃圾分类识别,以及 Zao App 。目前有些软件更多的是使用云端 AI 能力,需要把人脸照片上传至服务端做换脸,容易出现数据隐私问题。如果用端 AI 来做,不用上传你人脸图片,很自然解决数据隐私问题,只是现在端上算力不够,做不到这样的应用。
参考资料
听说,你还不了解“端智能”? - 知乎 (zhihu.com)
深度学习框架大PK:TNN决战MNN,ncnn依旧经典 - 云+社区 - 腾讯云 (tencent.com)
深度学习推理引擎:MNN pk TNN - 尚码园 (shangmayuan.com)

若有收获,就点个赞吧
0 人点赞
