关键词:强化学习、机器学习、深度学习、在线强化学习、离线强化学习、马尔科夫决策过程、认知不确定性、
乐观主义、悲观主义
来源:智源社区
作者:汪昭然、熊宇轩
编辑:蔡凯帆
导读:西北大学汪昭然老师课题组的主要研究方向为:为深度强化学习算法提供理论保障,从样本复杂性、计算复杂性等方面提升深度强化学习算法的效率。在近期的演讲中,汪老师分别介绍了在线学习环境下进行探索的「乐观主义」准则,以及提升离线学习鲁棒性的「悲观主义」准则。
深度强化学习
编者注:首先介绍强化学习、马尔科夫决策过程的相关背景知识。了解深度强化学习的核心算法马尔科夫决策过程数学原理,深度强化学习的优势和应用场景,以及深度强化学习所面临的挑战。

深度强化学习将深度学习强大的表征能力与强化学习的决策能力相结合,实现了与人类水平相当的人工智能算法。近年来,该技术在游戏人工智能、机器人控制、自动驾驶、推荐系统、计算机体系架构设计、共享出行等领域大放异彩。
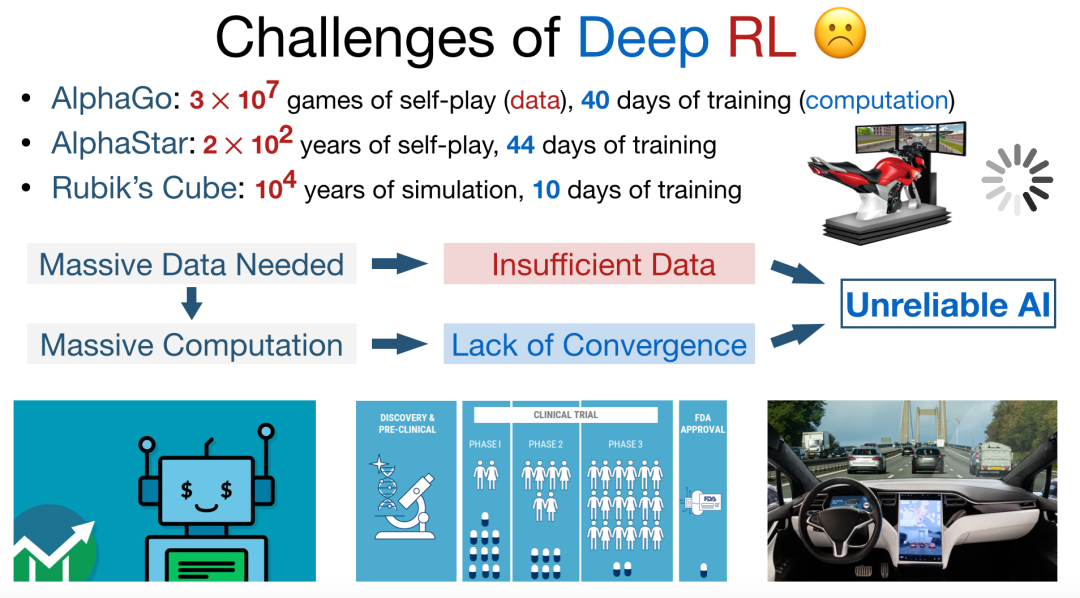
然而,深度强化学习的发展仍然面临诸多挑战。首先,训练深度强化学习模型需要使用海量数据,而我们往往很难在医疗、交通、金融等领域获取足够的训练数据。此外,训练此类模型往往需要耗费漫长的训练时间,耗费巨大的算力,否则最终的训练结果可能会收敛到较差的解上。
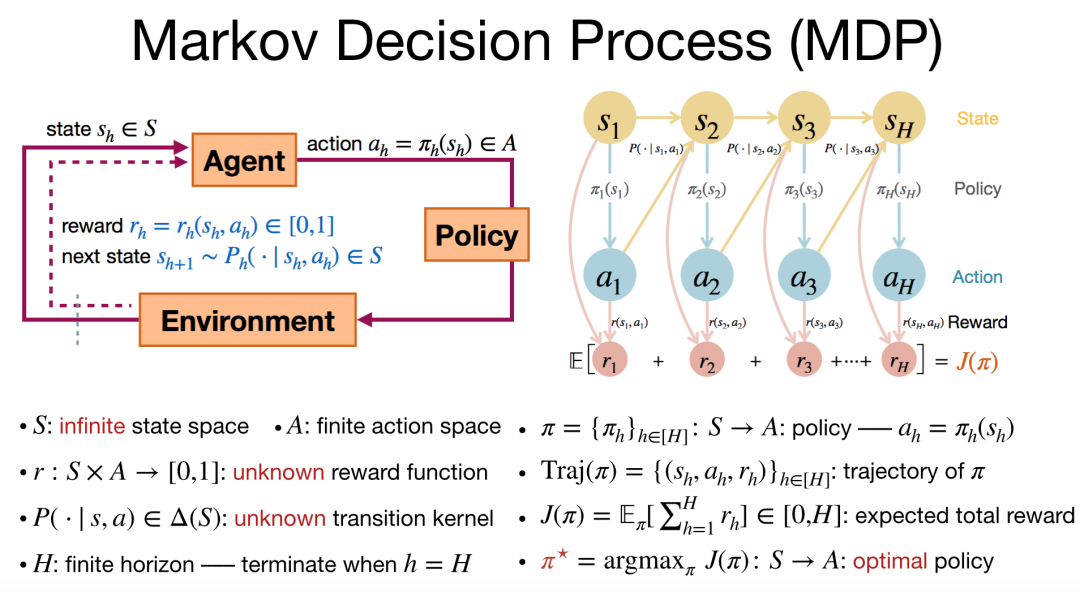
马尔科夫决策过程是深度强化学习技术最关键的数学模型。如图 3 所示,马尔科夫决策过程包含「智能体」、「策略」、「环境」三个重要部件。在每一轮迭代中,智能体会根据策略做出动作,从而与环境进行交互,而环境受到影响后会根据转移概率生成下一个状态,同时智能体会收到相应的奖励。此后,智能体会在新的状态下更新策略,执行新一轮的动作,该过程会循环往复地进行。
在这里,我们考虑有限长度为 H 的马尔科夫决策过程。在执行每一轮策略的过程中,我们会收集(状态,动作,奖励)的轨迹数据。其难点在于,当奖励函数和转移概率未知时,如何学习出好的策略,得到最大的奖励期望。
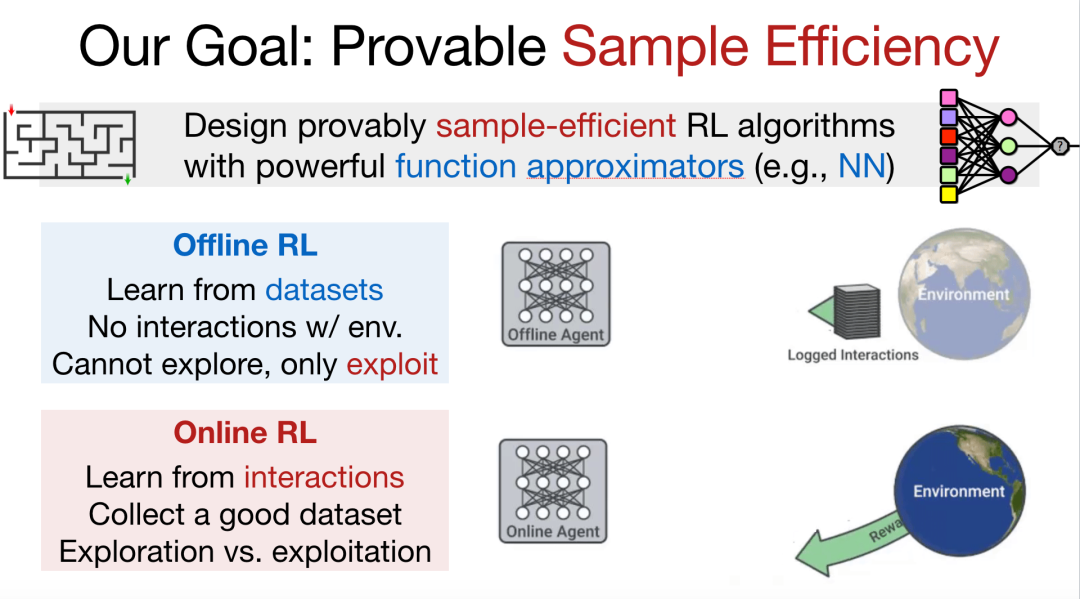
在寻找最优策略的过程中,我们重点关注算法的样本复杂性和计算复杂性。在使用神经网络等大规模函数逼近器的场景下,我们试图设计可证明的采样效率较高的强化学习算法。对于离线学习而言,给定数据集,我们无法与环境进行交互,需要在最大程度上利用数据集中的信息。然而,由于我们并不能够枚举出所有可能的情况,因此算法的鲁棒性往往仍然有很大的提升空间。对于在线学习而言,我们可以和环境进行交互,此时的重点是收集高质量数据集。有时我们需要投入更多的计算进行探索,有时则需要更加关注如何利用通过探索收集到的数据,这便是著名的「探索-利用」的折中问题。
为了解决上述问题,我们考虑在离线学习中使用「悲观主义」算法增强鲁棒性;而在在线学习中使用「乐观主义」算法加强探索,并减小遗憾值。
离线强化学习与悲观主义
编者注:介绍针对离线强化学习的悲观主义值迭代算法。了解离线强化学习所面临的难点,并学习悲观主义值迭代算法是如何优化离线强化学习。
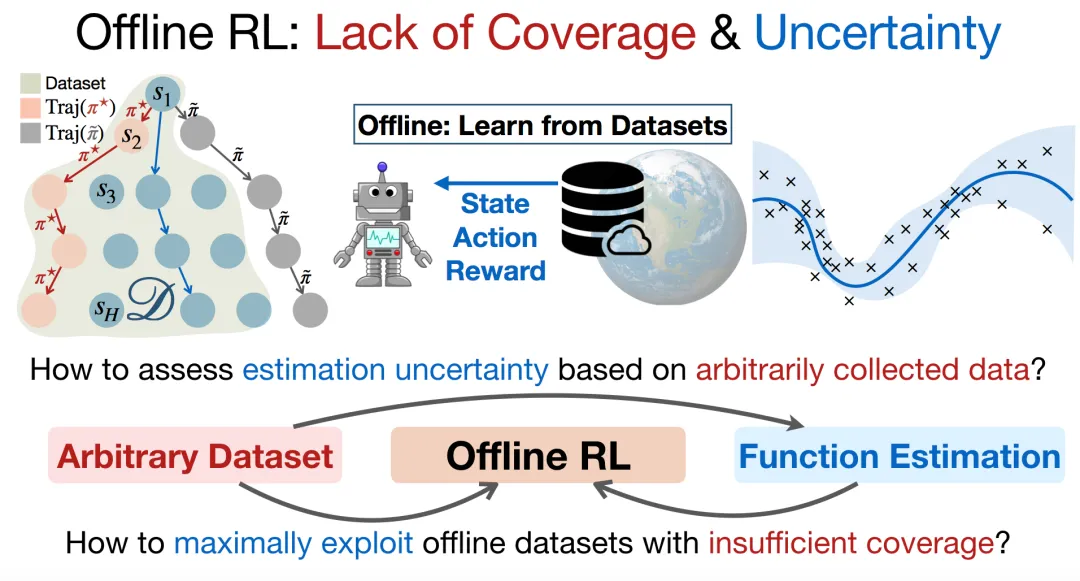
在离线学习中,我们无法与环境交互,只能使用现有的数据进行学习。然而,我们使用的数据可能并不完美。如图 5 所示,尽管收集到的数据已经包含最优策略产生的轨迹,但是可能并不包含某些次优策略产生的轨迹。在这种情况下,如果我们使用值迭代算法,可能会出现一些错误的解,即「不充分数据覆盖」问题。
为了解决「不充分数据覆盖」问题、最大程度地利用离线数据集,我们需要评估任意收集到的数据的认知不确定性(epistemic uncertainty)。由于数据的收集过程是任意的,因此评估这种不确定性也较为困难。此外,当我们能够估计这种不确定性(如图 5 中的置信带所示)时,还需要考虑如何利用它做出决策。

认知不确定性是由于我们只能使用有限的数据造成的。以多臂老虎机问题为例,认知不确定性会在决策过程中造成伪相关,即决策可能会被一些不确定性误导。例如,我们在高斯老虎机环境下可以做出多种动作,我们需要根据有限的观测数据选择其中的一个动作,此时我们对奖励的估计往往并不准确。如图 6 所示,如果我们的观测数据中有 10 条对第一个动作的记录,对其它动作均只有一次记录,其中第一个动作对应于最优策略。假设最后一个动作的奖励均值并不大,但是方差较大,尽管第一个动作的奖励均值较大,但是由于最后一个动作只有一条记录,我们可能会误以为最后一个动作的奖励值最大。此时,我们就陷入了次忧策略之中。

我们考虑采用「悲观主义」算法通过惩罚「认知不确定性」来消除上述伪相关现象,以更大的概率选择较为确定的动作,并且获得较大的奖励值。具体而言,在值迭代算法中,我们首先估算出 Q 函数,接着用估算出的 Q 函数减去对不确定性的惩罚项(置信带的宽度),从而得到悲观的值函数。我们期望通过这种悲观主义算法提升离线学习的鲁棒性,避免由于伪相关陷入次优策略。

通过使用上述悲观主义,在不需要满足任何对数据覆盖的假设时,我们可以以较大概率选择到最优策略。悲观主义算法适用于线性函数、核函数、神经网络等函数逼近器,理论上可以达到关于 H 的多项式的误差界的保障。其中,H 为马尔科夫决策过程的长度, 为函数空间复杂度的度量,T 为数据集的轨迹总数。
在线强化学习与乐观主义
编者注:介绍针对在线强化学习的乐观主义值迭代算法。了解在线强化学习所面临的难点,并学习乐观主义值迭代算法是如何优化在线强化学习。
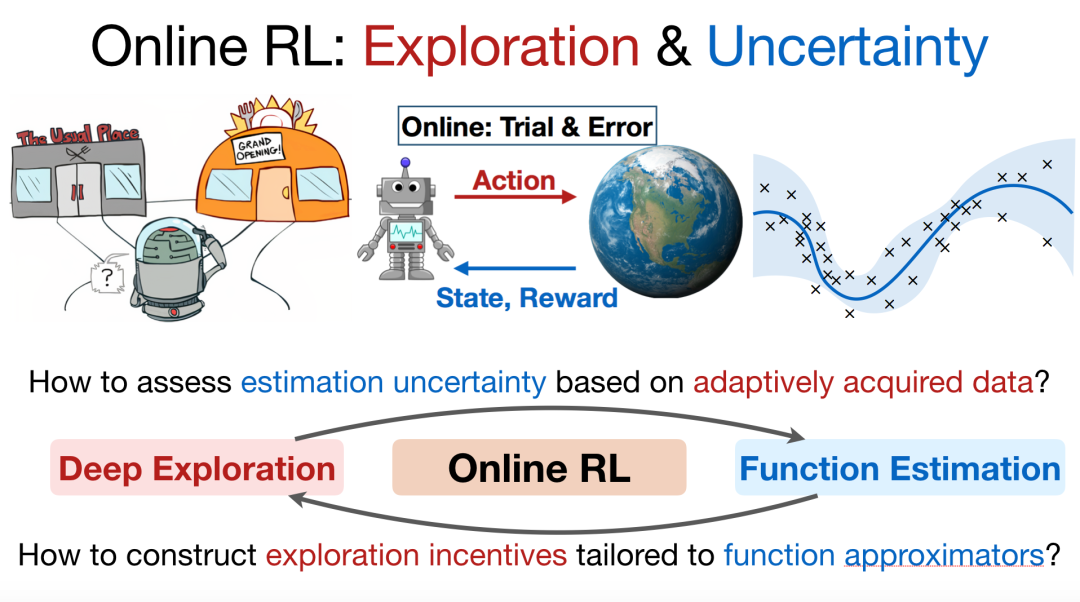
在在线学习任务中,此时我们需要在平衡探索与利用的条件下,尽可能多地对环境进行探索。而为了实现有效的探索,我们同样需要对不确定性进行评估。如图 9 所示,机器人可以选择前往之前经常去的餐厅,也可以选择前往新的餐厅就餐,此时如何选择新的餐厅就存在很大的不确定性。我们需要基于自适应的学习到的数据,为机器人探索新的动作施加具有一定不确定性的奖励。
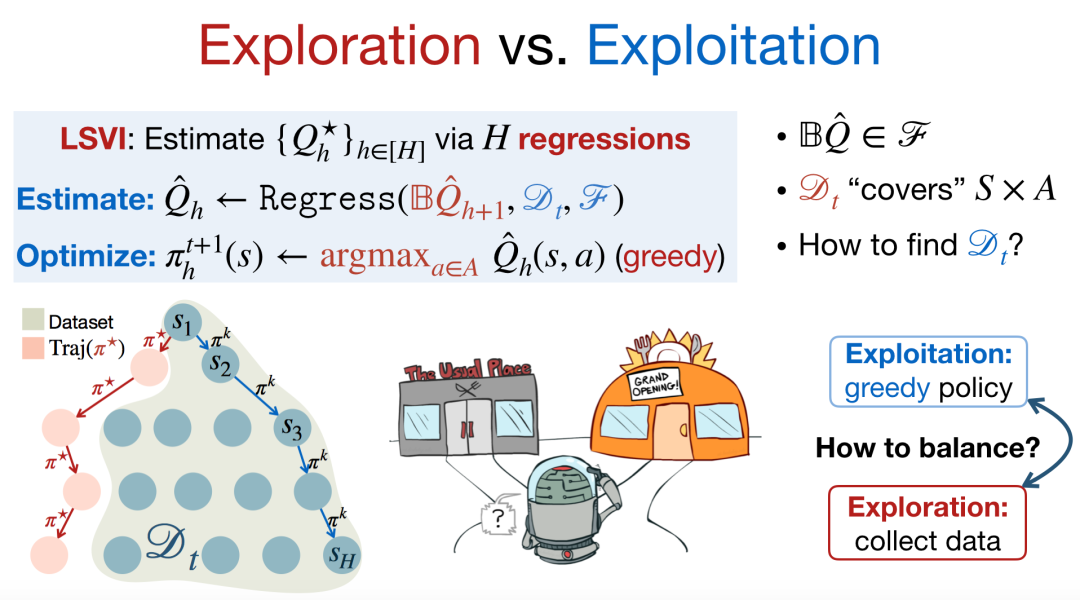
此时,我们可以与环境进行交互从而收集数据,然而当前已经探索的数据可能并不包含最优策略产生的轨迹,此时最关键的问题是如何平衡探索与利用。
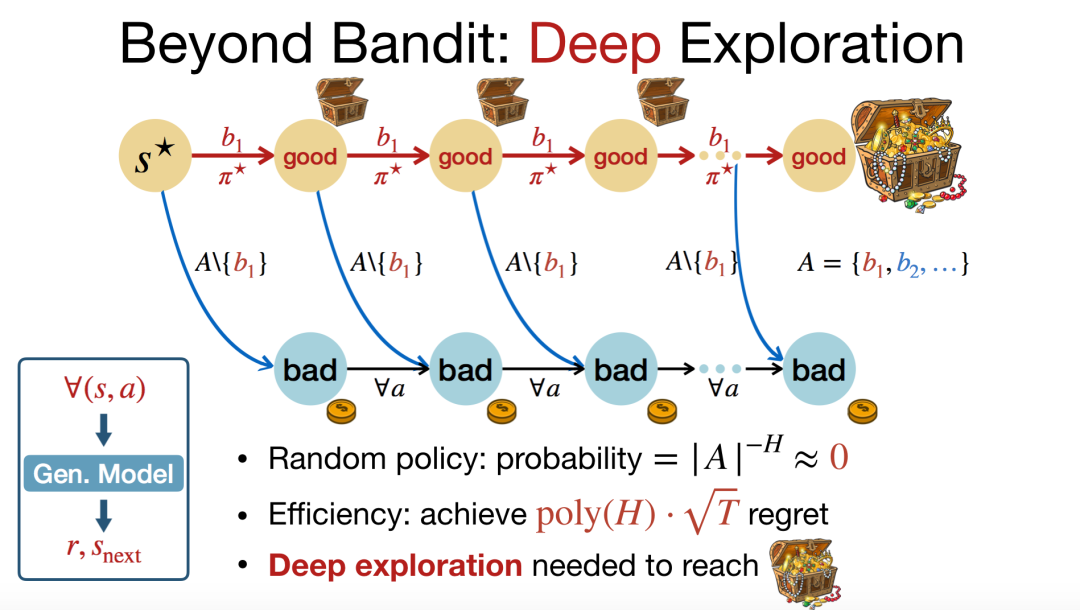
研究人员在多臂老虎机场景下对探索问题进行了大量的研究。然而,在马尔科夫决策过程场景下,由于我们需要进行深度探索,研究探索问题仍然面临着较大的挑战。如图 11 所示,假设我们一直采取第一个动作,则需要直到最后一步才能收获大量奖励,而如果我们采取第二个动作,则会在每一步都收获较小的奖励,但最终累积的奖励值仍然较小。在最优策略中,我们应该一直采取第一个动作,但实际上这种深度探索是很难实现的。如果我们采用随机策略进行探索,最终获得较大奖励的概率非常低,它是关于 H 的指数函数。理想情况下,我们希望奖励是关于 H 的多项式函数。

在传统的强化学习研究中,我们会构造一个仿真器,它会给出在任意状态下做出任意动作对应的奖励值以及下一个状态。然而,在实际场景下,构造出理想的仿真器是不可行的。与离线学习情况相反,我们在传统的值迭代算法的基础上加入了对不确定性的评估,并通过将估算出的 Q 函数与置信带宽度相加,从而鼓励智能体多做探索。

可以证明,通过使用乐观主义算法,我们可以使算法的遗憾值是关于 H 的多项式函数。
小结
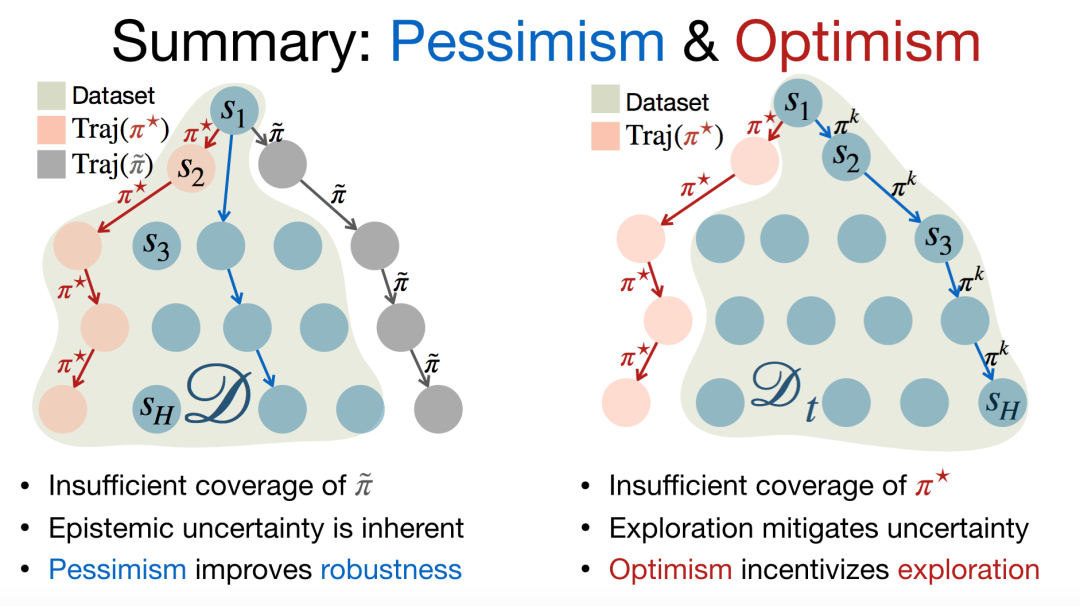
在离线情况和在线情况下,我们应该使用对偶的思路来设计悲观主义、乐观主义算法。在离线情况下,我们面临的主要挑战是数据的不充分覆盖问题。此时,我们收集到的数据可能并不包含某些次优策略的轨迹,我们出的决策很可能被误导。然而,我们希望决策仅仅会被最优策略轨迹所影响。此时,我们需要对认知不确定性进行评估,应用悲观主义的值迭代算法,从而对于认知不确定性更加鲁棒。在在线情况下,我们重点关注如何收集更好的数据。我们需要首先估计不确定性,再基于这种不确定性向值迭代算法中加入乐观主义的激励项,从而使算法能够探索具有较大不确定性的空间,观测到包含最优策略的轨迹。
此外,我们还可以基于悲观主义/乐观主义设计策略优化算法,甚至拓展到博弈的情况下(例如,Actor-Critic 框架),求解相关均衡。在具有一些约束的情况下,我们可以将悲观主义/乐观主义加入到「原始-对偶」优化问题中。在满足约束的条件下,实现探索与利用的均衡,并找到最优的策略。
未来的研究方向

我们希望在悲观主义/乐观主义算法的基础上,构建适用于各种场景的算法。例如,在金融应用中,我们希望控制风险、增强算法的安全性;在自动驾驶任务中,我们希望增强算法的鲁棒性。我们可以为算法人为地设计一个「对手」,并对博弈问题进行求解,从而实现鲁棒的强化学习。此外,在多智能体场景下,我们希望在智能体的合作过程中实现算法的可扩展性,在制定决策时兼顾效率和公平性,激励智能体做出满足人类要求的动作。

若有收获,就点个赞吧
0 人点赞
