正则匹配
time 38s
global -g (修饰符)
ignoreCase -i
mutli-line -m
原字符
word \w
\d \D digit [0-9]
\s \S space \n 换行 \t 制表 \v 垂直换行 \f 换页符
\b \B bridge 单词边界非单词边界,单词的两边
. 除了\n \r
记住正则全拼是什么意思
var reg=/\w/gim;var str='sdjflsdfj134';console.log(str.match(reg));

正向预查
time 20m43s
正向预查(先行断言)(先行否定断言)
/x(?=y)/
es6新特性
time 21m38s
1声明正则的变化方式
2字符串上的正则方法进行了调整
3新增修饰符 u y s;
声明正则的变化方式
time 23.22
es6写法new RegExp
var reg = new RegExp('xyz', 'ig');var reg = new RegExp(/xyz/ig);// var reg=/xyz/ig;var str = 'xyzyxyzyxyzxyyxzyxyz';console.log(str.match(reg));//[ 'xyz', 'xyz', 'xyz', 'xyz' ]
字符串上的正则方法进行了调整
time 32.53
console.log(RegExp.prototype);
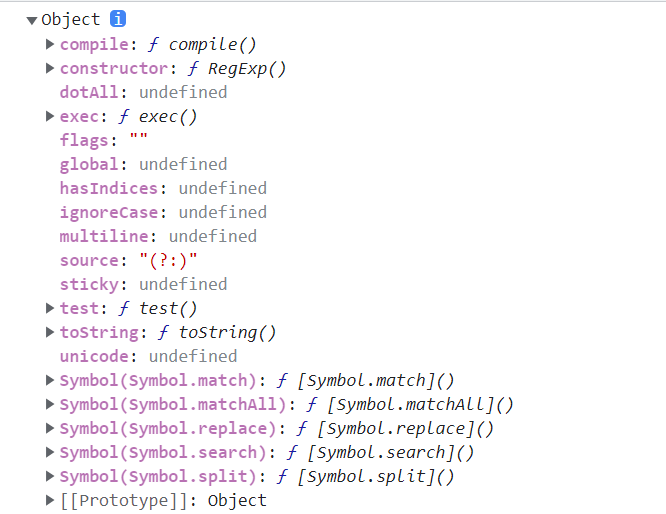
Symbol对象(Symbol.match)键名:键值function
对应都是一个方法,match方法
就是str.match方法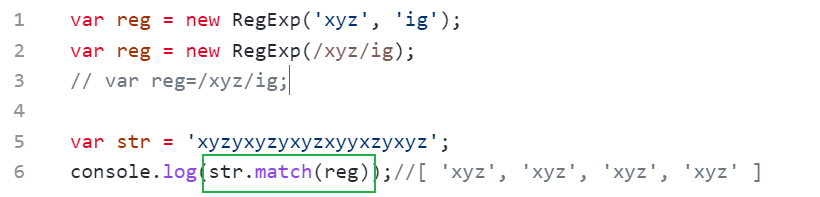
time 41m37s
console.log(RegExp.prototype[Symbol.match]);console.log(String.prototype.match)
把string.match用的match方法移动到了RegExp.prototype上,String.match其实是在调用RegExp.prototype[Symbol.match]的方法
把以上字符串上面的方法移动到了
新增修饰符 u y s
time 42m29s
修饰符
var reg=new RegExp('xyz','ig');console.log(reg.global);//trueconsole.log(reg.ignoreCase);//trueconsole.log(reg.multiline);//false
y修饰符
time 44m
var reg=new RegExp('xyz','ig');console.log(reg.global);//trueconsole.log(reg.ignoreCase);//trueconsole.log(reg.multiline);//false/*y修饰符 (sticky)*/console.log(reg.sticky);//false
var reg=new RegExp('xyz','igy');console.log(reg.__proto__);

y与g区别
time 53m11s
y匹配aaa,a是匹配时第一个出现的所以匹配aaa,之后剩下aa_a,继续匹配,a不是第一个出现的了,前面有_a有,就不匹配了
第一个值必须粘上第二个值才行,第二个匹配的方式必须紧贴第一个方式
var str = 'aaa_aa_a';var reg1 = /a+/g;var reg2 = /a+/y;console.log(reg1.exec(str));console.log(reg2.exec(str));console.log(reg1.exec(str));console.log(reg2.exec(str));console.log(reg1.exec(str));console.log(reg1.exec(str));

flag
time 54min
var reg=/\wabed/giy;console.log(reg.source);//\wabedconsole.log(reg.flags);//giy
u修饰符
time55.45
码点
time 56.27
字符串,每一个字符串都是按照一定编码格式进行编码,进行储存,再进行解析的,以UTF-16的方式进行编码储存
unicode分区定义 :是一个字符编码的总集,包含很多编码,UTF-16、UTF-32都是Unicode的一部分,每个区可以放2*16的字节长度(BMP),这叫做一个基本平面,有17个平面
U+0000到U+FFFF 16进制,常用字符,在第一个平面内,这个BMP平面内,这个范围就是码点
也有不常用字节,不常用的汉字,可能不在这个范围之内,四个字节
U+D800 U+FFFF
/*2个字节,7是多余的,所以多余一个7*/console.log('\u20bb7');//₻7console.log('\u20bb');//₻/*四个字节表示特殊字符,2个字节装不下* 当码点数大于800时,是没有需要组合表示,es5不支持,es6支持*/console.log('\uD842\uDFB7');//𠮷
{}解析
es6优化,有{}包裹
time 1h11m
/*2个字节,7是多余的,所以多余一个7*/console.log('\u20bb7');//₻7console.log('\u20bb');//₻console.log('\u{20bb7}');//𠮷/*四个字节表示特殊字符,2个字节装不下* 当码点数大于800时,是没有需要组合表示*/console.log('\uD842\uDFB7');//𠮷
匹配
time 1h16m
console.log(/^\uD83D/.test('\uD83D\uDC2A'));//true
这是es5的错误,应该预计是false,false是合理的,因为uD83D不是一个值,\uD83D\uDC2A是一个值,es5把它看成两个值了
console.log(/^\uD83D/u.test('\uD83D\uDC2A'));//false
通过u修饰符的方式,可以解决这个问题
不能匹配
time 1h24m
var s='\uD842\uDFB7';console.log(s);// 𠮷 nodejs运行 不规则字符,粘贴后也是𠮷console.log(/^.$/.test(s));

nodejs运行结果
es6 u使得.可以匹配特殊字符
var s='\uD842\uDFB7';console.log(s);//console.log(/^.$/.test(s));//falseconsole.log(/^.$/u.test(s));//false
{}代表量词
time 1h32m
console.log(/a{2}/.test('aa'));//true
通过u使得{}内的变成字符编码
time 1h35m
console.log(/a{2}/.test('aa'));//trueconsole.log(/\u{20bb7}/u.test('𠮷'));//true
s修饰符
time 1h38m35s
s dotAll
.可以匹配任何字符,在es2018已经实现了
.不能代表字符,\n \r U2028 U2029
console.log(/foo.bar/.test('foo\nbar'));//falseconsole.log(/foo.bar/s.test('foo\nbar'));//true/*s让.可以代表一切字符*/console.log(/foo.bar/s.dotAll);//true

若有收获,就点个赞吧
0 人点赞
