Kecharts是什么
在贝壳,有店东、圈经、CA等多种服务角色依赖数据信息作业,各种各样的数据被用于管理、分析和制定目标。但是,房产垂直领域的数据非常庞杂,数据体量也在急剧增长,图表的应用场景越来越复杂,除了pc和移动端的数据看板,还出现了线下门店大屏场景。
与此同时,数据展示一直处于无可视化规范的状态,导致频频出现“数据堆叠”“数据出界”“数值无单位”等可读性低的问题。因此,把这些复杂、抽象的数据,通过更直观更容易理解的可视化方式展示出来,建立一套专注于房产领域的可视化组件规范,变得尤为重要。
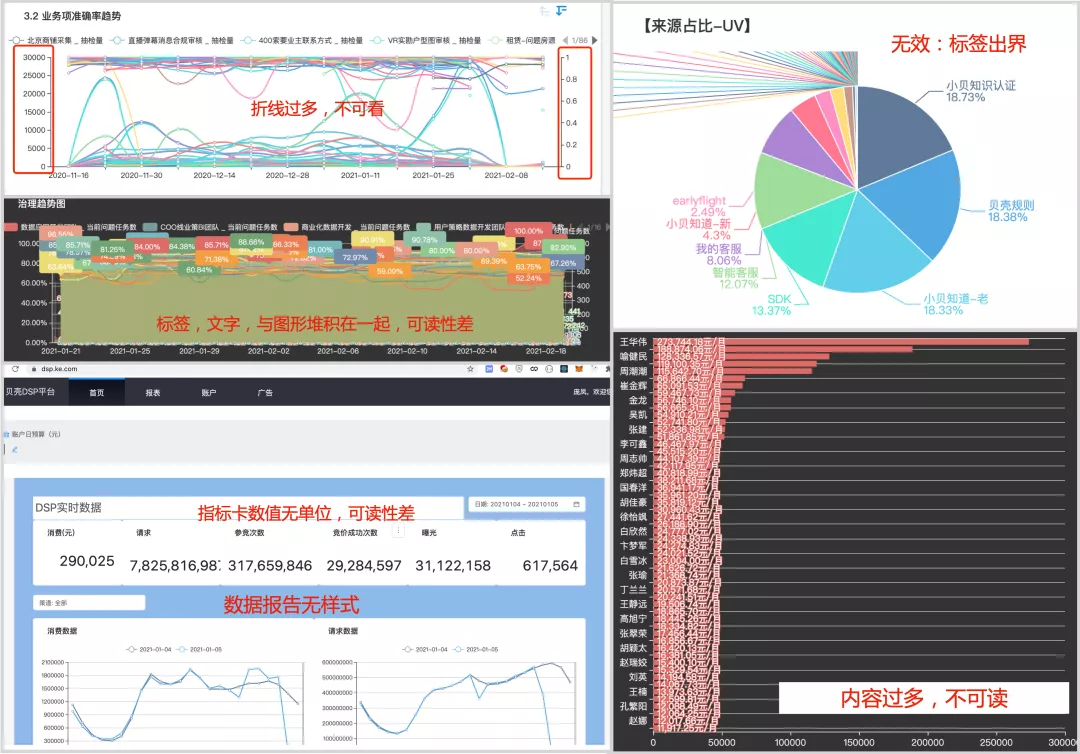
图1 数据部分展示现状
Kecharts项目从汇总和梳理数据展示问题出发,聚焦并抽象问题点,旨在建立起统一的可视化规范。同时,我们还对极端数据的展示进行计算规则处理,从人工配置的效率考量,系统性地帮助用户进行高效分析和决策。
1.从不统一到有规范
数据规范的第一步,解决“知道什么数据用什么图表,了解颜色的使用规范、数据排版展示的要点、适配性原则”等基础规范,从配色、布局、基础展示规则上,满足数据展示的美观度和可读性。
2.极端情况的处理规则
最难解决但也最有价值的痛点是:数据体量大、维度多带来的“不确定性问题”,想要把海量、高维的数据以准确有效的方式展示,需要建立高质量的交互和配图规则。因此,我们在梳理基准展示规范的基础上,也对极端情况进行了一系列的规则处理。
3.人员可配的高效性
数据往往是由平台自上而下传达到城市,再由专业的商业分析师对数据进行分析和处理,很多数据需要人工绘制和展示。因此,Kecharts在设计数据规则展示的同时,也要考虑数据的可配置输出规则,尽可能减少人工操作成本,降低由于人工分析水平不同导致的报告质量方差。
建立图表可视化
基础规范
建立基础可视化规范,是为了将图表展示拉到基准线水平,也是当前要做的第一步。基础的规范建立,可以让图表迅速换身衣服,第一时间提升用户的感受。所以,第一步首先解决配色的使用、基础的布局、图形的基本表达等方面的规范问题,满足数据的基础美观度。
1. 配色-更科学的配色带来崭新的视觉感受


图2 配色色板图示(局部)
优化前,Kecharts各种配色之间关联性低,与整体平台的表现层形式不统一。优化后色板的样式与KeDesign无缝融合。现有配色方案饱和度更协调,阅读体验更友好。由于数据体量大,我们尝试将8种常用色扩展成10种常用色以及24种扩展色来更好地满足业务需求。并且根据不同品牌主色,进行明度调整。除此之外还增加了更沉稳的商务主题以及暗黑主题配色,满足特殊业务场景的使用。
图3 配色的概念图
2. 布局-更合理的布局带来清晰准确的表达
【基础布局】:图表的构成,由一系列独立的图形与法元素结合而成,如包含标题区、操作功能区、面包屑、图例区、单位区和图表区,通过合理的基础布局增强图表的秩序性和一致性,同时规范标题、图例等元素的展示适配规则。
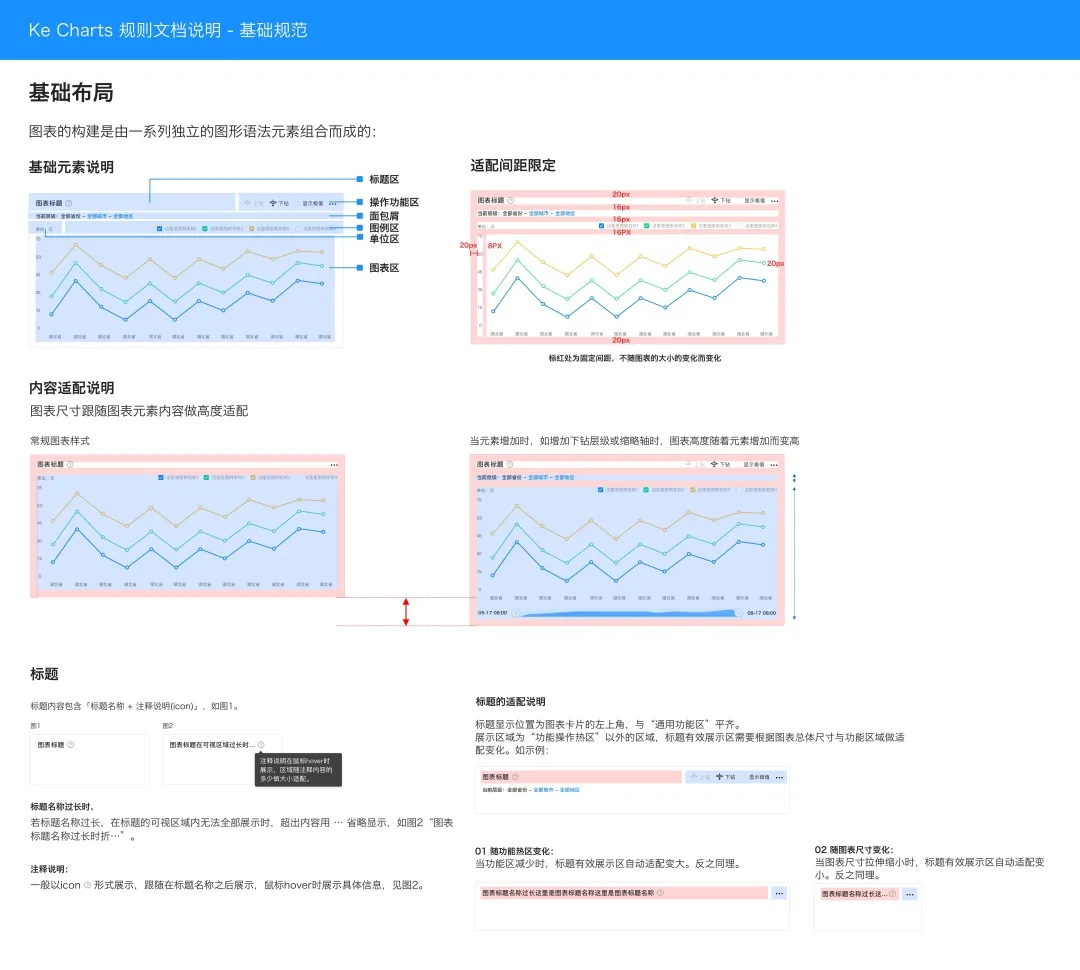
图4 数据基础布局规范(局部)
【精细图形】:整体的图形展示细节也做了统一调整,从整体排布、字体、字号、圆角、描边粗细、数据轴、标签等方面进行了优化设计,使整个图表看起来更加精细。
基础的配色、字号、布局调整之后,基本满足了数据的展示基准,从基础合理性展示和视觉感提升上,有了一定的改良。
图5 基准规范后的对比
3.适配-更灵活的规则带来细腻的交互体验
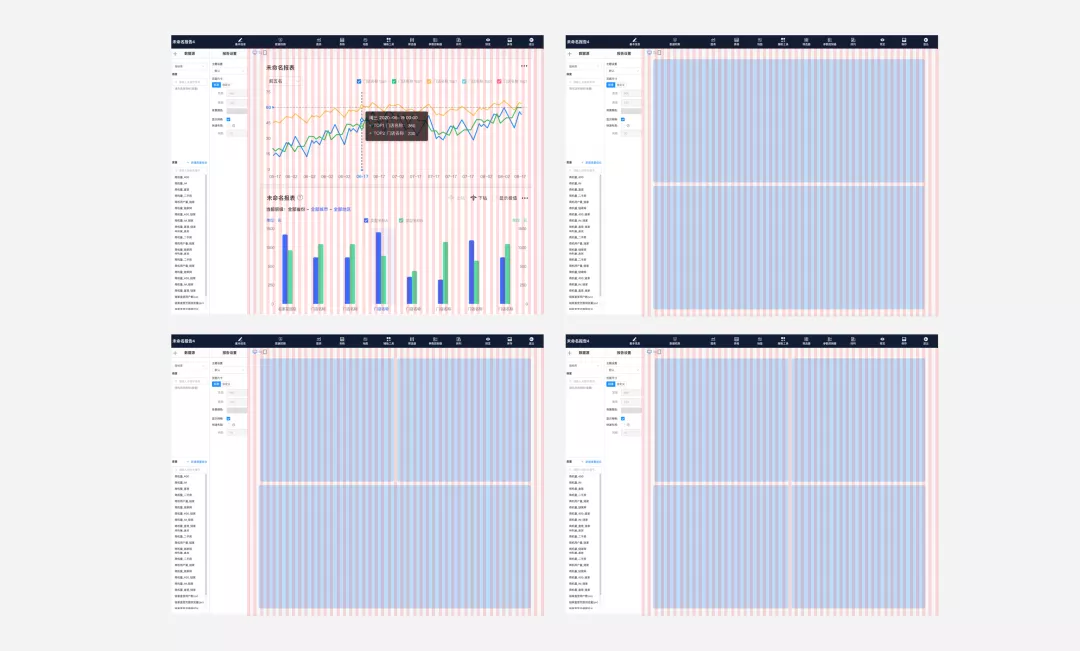
图6 栅格化设计图示
【定义图表的适配规则】:定义四种图表卡片的适配方案,当图表放大或缩小到某一区间时,内部布局会根据图表大小变化进行有权重的删减,使图表在多种区间内能够将核心数据表达的更清晰。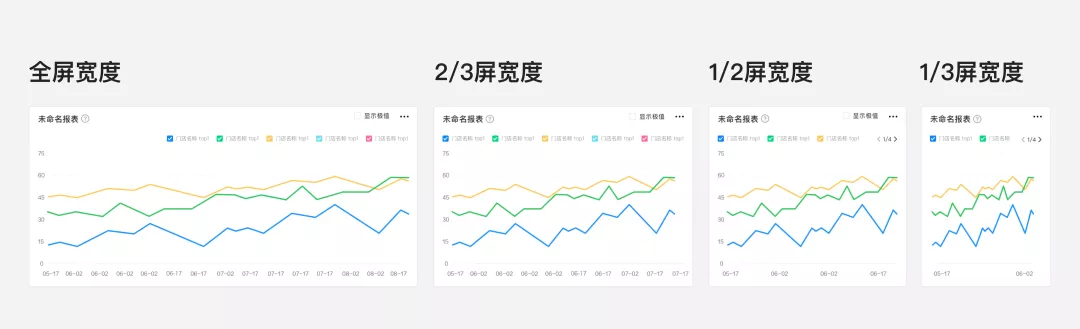
图7 栅格化设计图示
极致探索
极端情况规则
满足了数据的基准展示,并没有达到完整的可视化展示规范,海量和高维带来的展示问题依旧存在。所以,在建立基准规则的基础上,结合贝壳数据的特色,需要集中处理极端情况带来的问题,从基准线提升到具有易用性的“标准线”。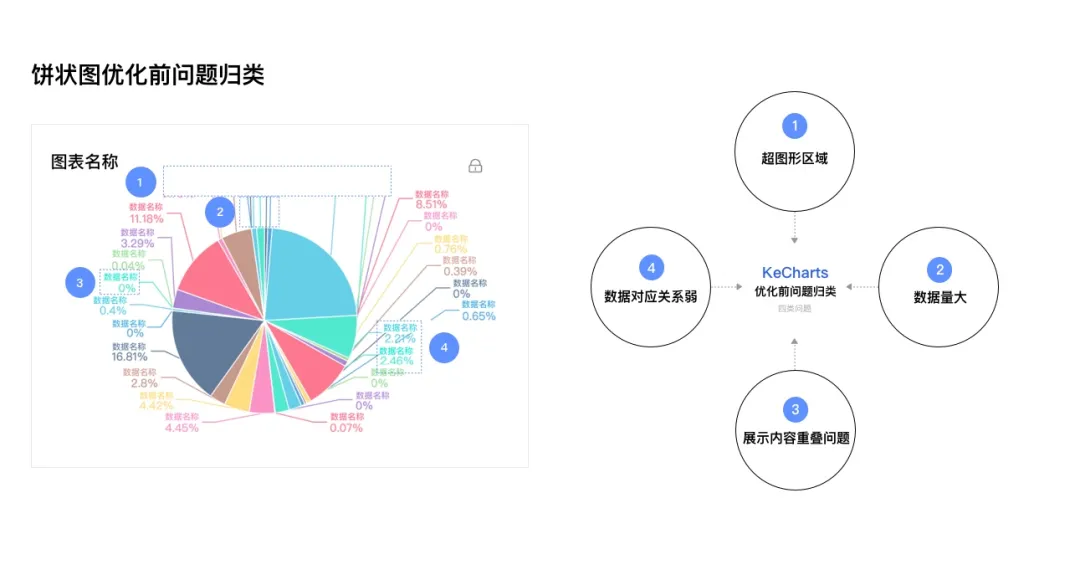
图8 以饼状图为例的极端情况分析
1.解决数据量过载导致的不确定问题
【过滤数据】:首先从底层数据进行过滤,过滤底层占比0%的数据,减少数据呈现量。将占比为0%的大部分数据在图表的可视化展示中去除,转移到图例中展示,满足了用户需要完整数据的诉求外还大幅度提升了图表的可视化程度。
【元素优化】:优化标签、线条、指示等元素的展示规范,从定义边界位置、规范标签的展示内容上,对图表内元素的极端情况做适配处理。
【智能检测】:为了消除信息过载带来的标签碰撞,我们制定了标签的智能检测规则,当两个标签重叠超过1/3时,自动化地隐藏部分标签,被隐藏的部分可以通过悬停展示详细信息,不经意间大幅度的提升图表的展示美感和用户的浏览体验。

图9 饼状图为例的处理过程
2.拓展通用性极端处理规范
从单点问题扩展为通用性规范处理,在不同类型图表的极端情况处理过程中,从全局的角度出发,对极端情况下出现的核心问题做汇总并抽象,在颜色、碰撞、超图形等方面,输出极端情况处理规范。

图10 通用性智能检测规则(局部)
提升人工配置
的高效性
数据分析和传达的过程,依托于人工过滤、处理、绘制和展示,考虑数据的配置输出,人为水平难以把控,尽可能减少人工不必要的操作成本,从而提升数据报告产出的质量。
在配置自由度时结合产品定位、属性和功能进行思考。用户希望数据通过配置层处理后转化为可视化图表。普通用户期望通过简单的操作快速搭建数据看板;高级用户希望对可视化图表有精细化的自定义需求。
我们尽量用智能处理代替人工对数据无效数据的筛选,对数据的展示做智能的适配,如指标卡的展示,前置设置了一系列的展示模版,在用户选择指标数据的同时,会根据指标的数量做自动化贴合排布。与此同时,保留了一定的人工可配置自由度,支持用户可自由配置指标卡的细节展示等。

图11 指标卡用户配置示意
因此,针对大量杂乱的数据,数据的呈现通常需要两层呈现给用户。第一层是数据库和数据源,会自动过滤掉存在的垃圾数据和无效数据。第二层是数据分发层,尽可能的通过自动化的配置去辅助操作员进行数据的分发和最终数据面板的呈现效果。通过简化操作流程和匹配人为操作习惯,降低学习成本,提升操作效率,为操作者提供“顺其自然的设计”。
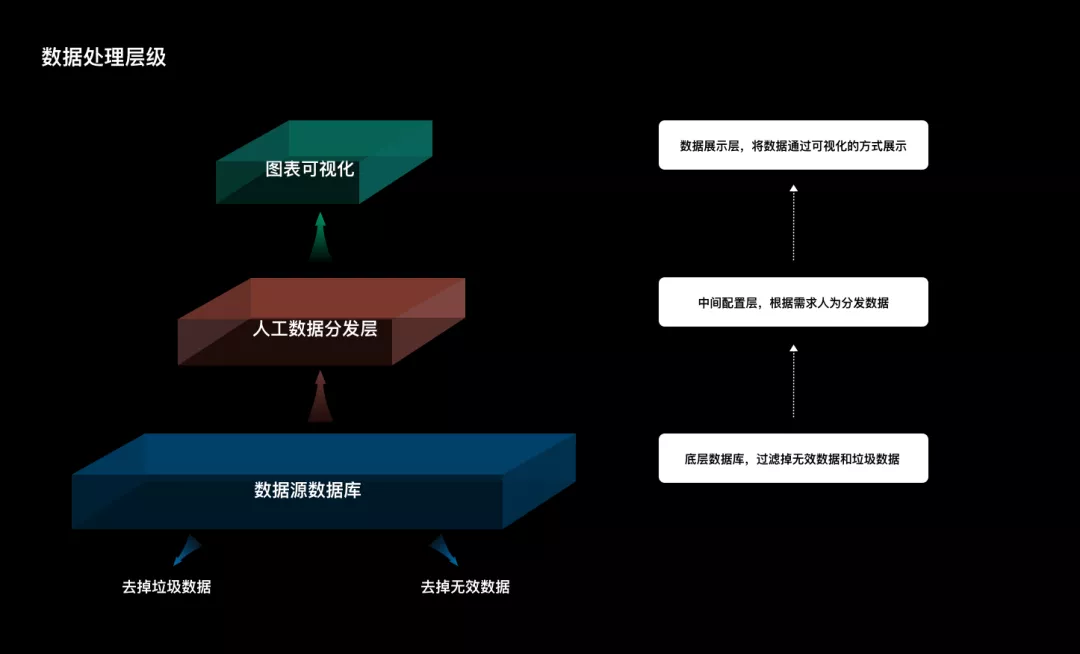
图12 数据处理分层图示
结语
Kecharts的初衷是保证数据的真实、高效展示数据、遵循美学原则。我们遵循数据能够真实呈现的原则,在可视化表达中确保不遗漏、不误导,确保数据准确性。同时,在准确的基础上,做到清晰有效的可视化设计,保证传达的有效性,让使用者能够高效准确的完成分析决策。Kecharts规范的拓展与探索会持续进行,未来将覆盖报表、大屏、大数据可视化等多种场景,期待KEDC后续的文章吧。

若有收获,就点个赞吧
0 人点赞
