正则表达式
正则表达式
描述字符串模式(pattern)的语法,一种通用的文本模式表达方式。
理解由一个个小的模块单元构成,通过无数个单元组合来描述字符串。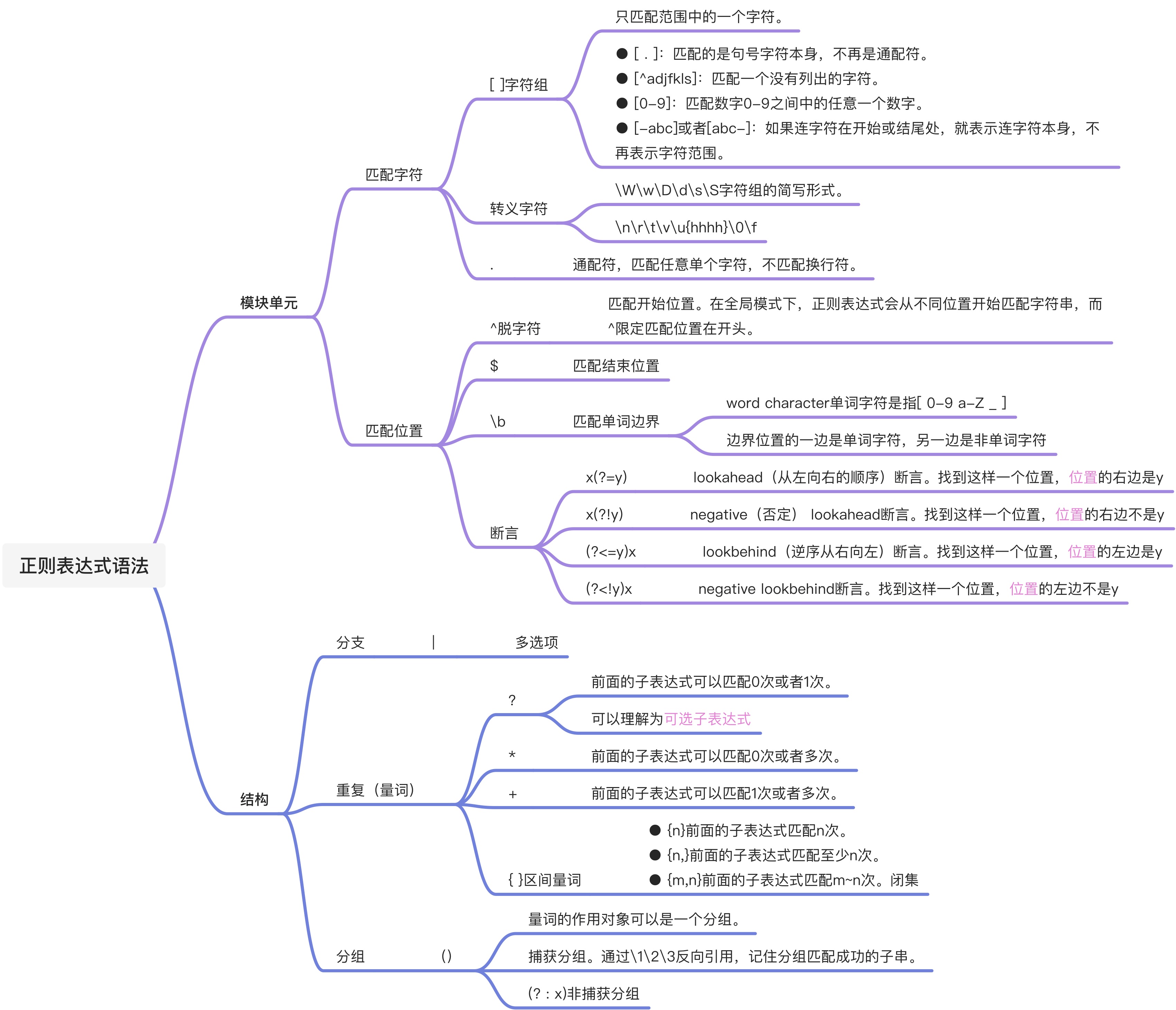
正则引擎
核心功能就是搜索符合正则表达式的文本。
理解正则引擎是算法,正则表达式和输入的字符串是数据。判断输入的字符串是否属于正则表达式,做出决策(直接输出是否匹配、替换、捕获)。类似于抽象数据类型和具体值的关系。
基本的匹配规则
正则引擎的开始状态就是字符串的某个位置。如果匹配失败,开始状态就会跳到下一个位置。
/aa/样本:‘mbaads’文字意义:1、从开始位置0匹配,第一个字符是m,匹配失败2、跳到位置1开始,第一个字符是b,匹配失败3、跳到位置2开始,第一个字符是a,匹配成功,第二个字符是a,匹配成功。
贪婪
对于量词?,*,+,{n, }约束的子表达式,当满足量词匹配下限时,优先尝试匹配更多的字符串,直到匹配上限。
关键点贪婪的关键是量词作用的子表达式优先匹配
关键点非贪婪的关键是量词作用的子表达式优先忽略,转到下一个表达式。
回溯
当遇到量词(贪婪匹配)或选择分支 |,会出现选择到底匹配哪个分支,引擎会选择一个分支,同时记住另一个分支。当剩下的子表达式失败时,就会回溯到之前选择的地方。最终引擎最终会尝试所有的分支可能,直到匹配成功。
关键点非贪婪模式,本质上是量词作用的子表达式优先选择尝试不匹配。
参考
https://stackoverflow.com/questions/1324676/what-is-a-word-boundary-in-regex 单词边界
https://stackoverflow.com/questions/60235764/what-is-runtime-compilation-in-javascript 初始化正则字面量和构造函数的区别

若有收获,就点个赞吧
0 人点赞
