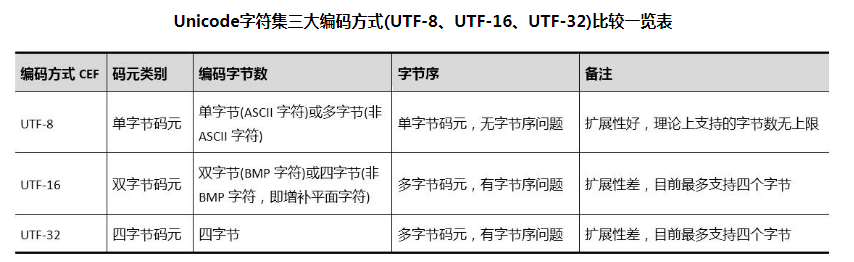
Unicode字符集
传统的字符编码模型,字符集和字符编码是一一对应的,耦合的程度很高。字符集是封闭的,不允许添加新字符。如果要扩展字符,必须重新指定标准。
Unicode字符集模型采用分层的概念,字符集、字符编码方式是分离的、无相关性。字符集可以有多种编码方式。
模型的结构
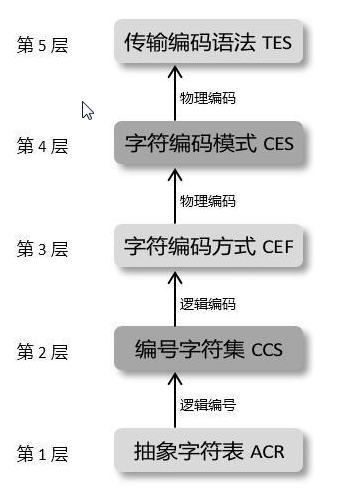
抽象字符表ACR
无序的抽象字符的集合。抽象字符是字形的特征描述,但是没有给出具体的实现。
编号字符集CCS
给每个字符编号。由此产生编号空间。编号空间的每一个位置称为码点(code point)。不是所有的码点对应者字符。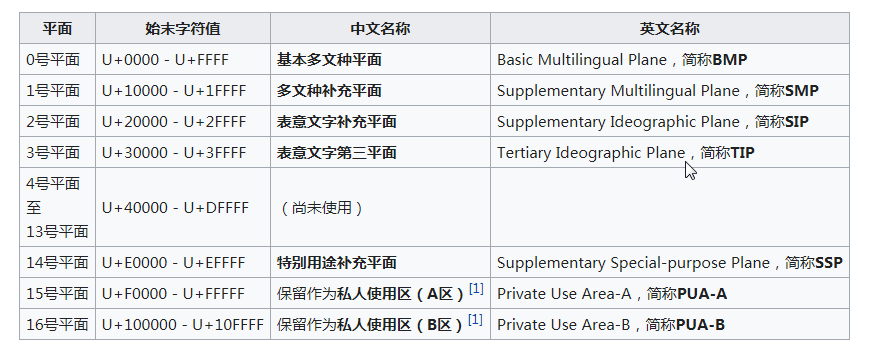
码点
目前的Unicode字符分为17组编排,每组称为平面(Plane),而每平面拥有65536个码点。然而目前只用了少数平面。
关键点在编程中,直接使用码点值来表示字符。
BMP
基本覆盖全世界范围内常用的字符。
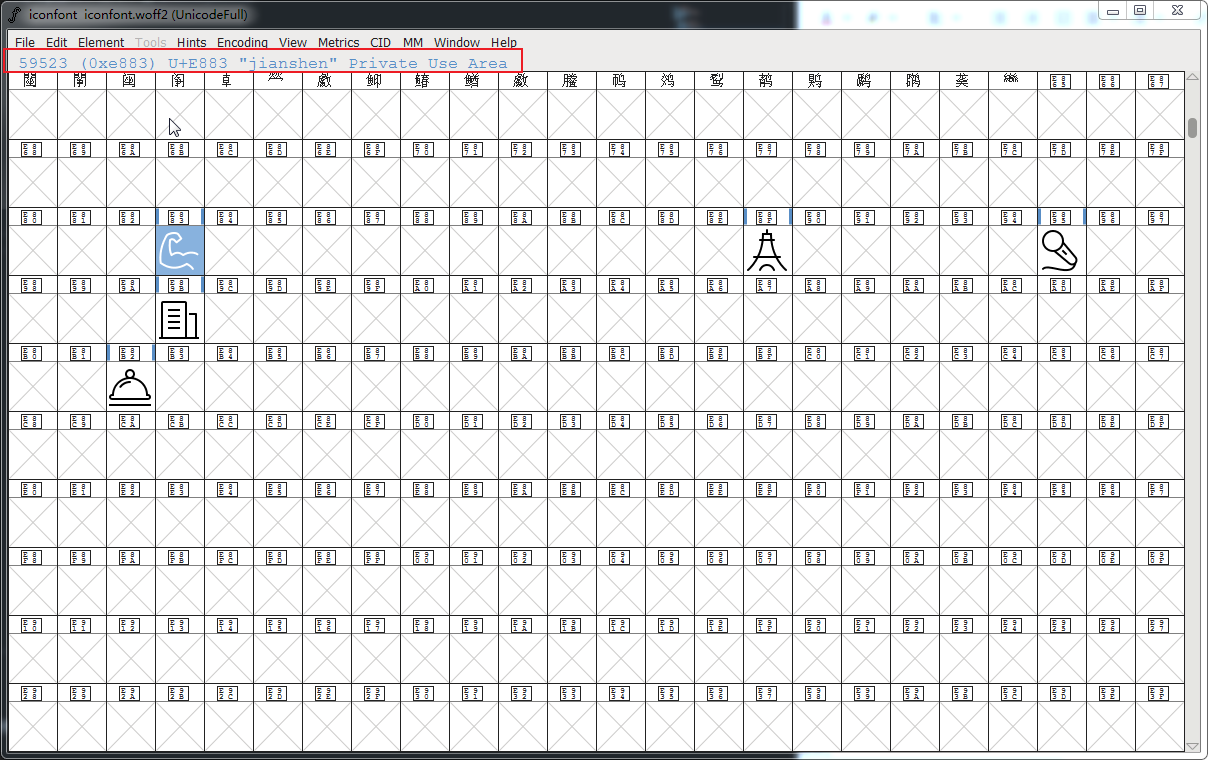
- E000-EFFF码点(十进制57344~63743)是私人使用的。FontAwesome字体图标就是使用的私有区的码点。
代理区
U+D800…U+DFFF(十进制55296~57343),共2048个码点,这些码点被称之为代理码点,目的是用基本平面BMP中的两个码点“代理”表示BMP以外的其他增补平面SP中的字符。
字符编码规则CEF
字符编码模式CES
码元序列映射为字节序列。因为不同的系统平台在处理多字节的数据时,存在读取顺序是从低地址,还是高地址的问题。
关键点码元序列仍然是与计算机系统平台无关的逻辑意义上的编码过程。CES就是跟特定平台相关的物理意义上的编码过程。
传输编码语法TES
对字节序列进一步处理。比如:加密、压缩,保证传输的安全、可靠、节约。

若有收获,就点个赞吧
0 人点赞
