/*
广播变量应用场景:
1、task需要使用Driver数据的时候【好处: 能够减少数据占用内存空间】
task任务个数设定:
工作中一般设置task个数为cpu核数的2-3倍(官网建议)
因为如果设置超过这个数,需要运行多批次才能完成任务
如果设置少了,又有cpu空闲,浪费资源
如果刚好设置为与cpu核数相同,那么就会每个cpu性能不一,在一个时段内完成的内容不同,也会造成浪费
广播变量:少了executorcores官方建议倍数,这里是5core3倍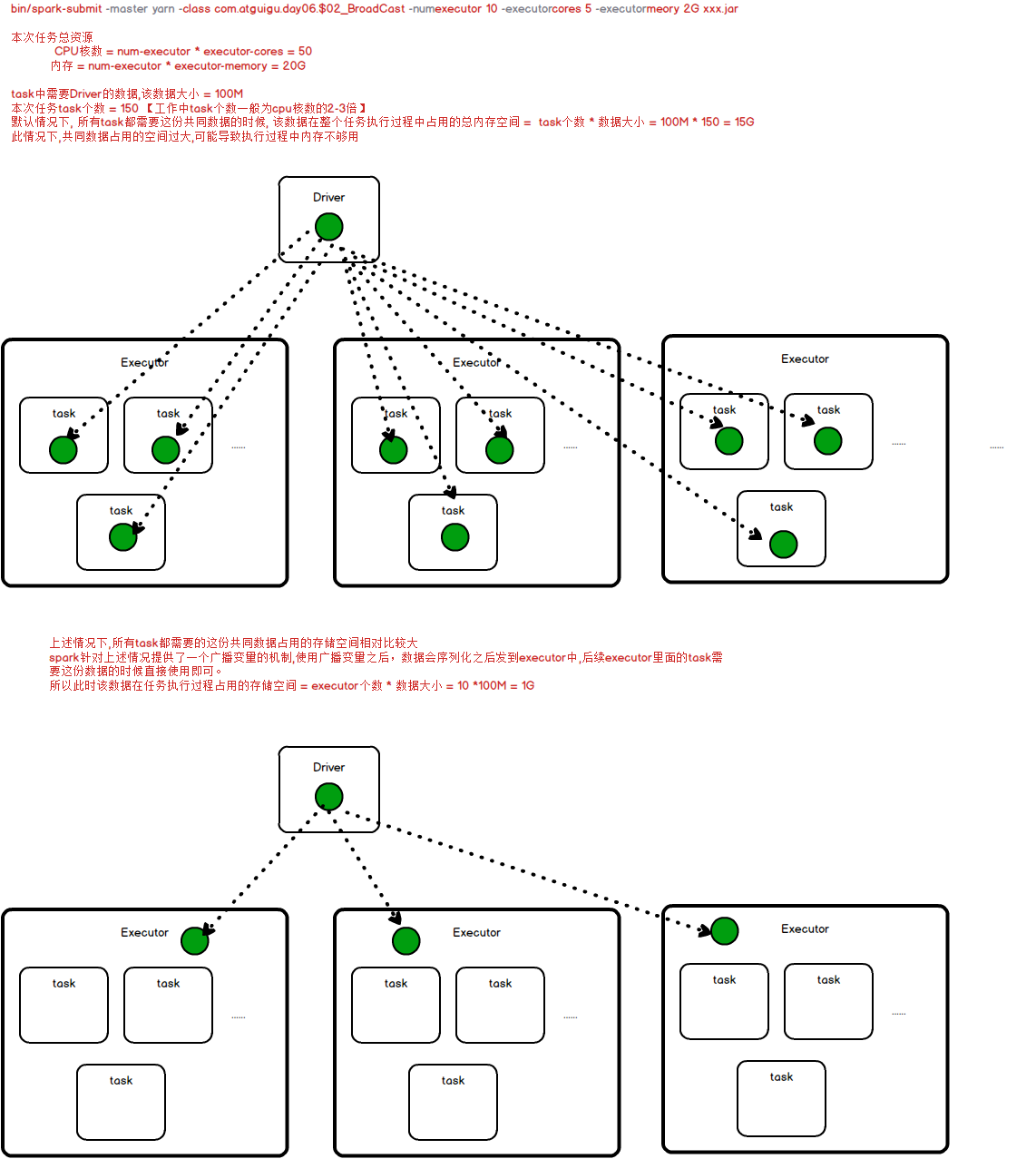
2、大表join小表 【好处: 能够减少shuffle操作】
1)使用join的时候涉及到两个rdd的数据聚合操作,产生两个shuffler
2)使用广播减少shuffler:
将driver的广播数据收集好
之后将数据传递到一个rdd中进行自定义操作,不涉及两个rdd,不会落盘
如何使用:
1、广播数据: val bc = sc.broadcast(数据)
2、task取出数据使用: bc.value
*/
task使用driver的数据
package tcode.day06import org.apache.spark.{SparkConf, SparkContext}object $02_BroadCast {/*** 广播变量应用场景:* 1、task需要使用Driver数据的时候【好处: 能够减少数据占用内存空间】* 2、大表join小表 【好处: 能够减少shuffle操作】* 如何使用:* 1、广播数据: val bc = sc.broadcast(数据)* 2、task取出数据使用: bc.value**///task需要使用Driver数据的时候【好处: 能够减少数据占用内存空间】def main1(args: Array[String]): Unit = {val sc = new SparkContext(new SparkConf().setMaster("local[4]").setAppName("test"))val rdd = sc.parallelize(List("jd","taobao","tm","pdd"))val map = Map("jd"->"http://www.jd.com","taobao"->"http://www.taobao.com","tm"->"http://www.tm.com","pdd"->"http://www.pdd.com")//使用广播变量之后, map数据占用的内存大小 = executor的个数 * map数据大小// 广播的内容不是rdd而是数据,所以需要先collect收集再广播,这里的map就是数据,不需要collectval bc = sc.broadcast(map)val rdd2 = rdd.map(x=> {//取出广播变量的值val value = bc.valuevalue.getOrElse(x,"")})//此时map数据占用的内存大小 = task的个数 * map数据大小//val rdd2 = rdd.map(x=> map.getOrElse(x,""))println(rdd2.collect().toList)}------------------------------------------------------------------------------Thread.sleep(10000000)}}
大表join小表
//大表join小表 【好处: 能够减少shuffle操作】def main(args: Array[String]): Unit = {val sc = new SparkContext(new SparkConf().setMaster("local[4]").setAppName("test"))val studentRdd = sc.parallelize(List(("1001","zhangsan",20,"A"),("1002","lisi",20,"B"),("1003","wangwu",20,"A"),("1004","zhaoliu",30,"C"),("1005","qianqi",40,"B")))val classRdd = sc.parallelize(List(("A","大数据班"),("B","java班"),("C","python班")))//需求: 获取每个学生的信息以及所在班级名称// 没使用广播:需要join,会产生两个shuffler/* val stuRdd = studentRdd.map{case (stuId,name,age,classId) => (classId,(stuId,name,age))}val rdd: RDD[(String, ((String, String, Int), Option[String]))] = stuRdd.leftOuterJoin(classRdd)rdd.map{case (classId,((stuid,name,age),className)) => (stuid,name,age,className.getOrElse(""))}.foreach(println(_))*///广播小表数据后,不需要join// 广播的内容不是rdd而是数据,所以需要先collect收集再广播val classMap = classRdd.collect().toMapval bc = sc.broadcast(classMap)// 普通jion与广播的区别,// 广播是将数据放进广播里,执行的时候可以直接将数据传递进一个rdd中,进行自定义操作,不涉及两个rdd所以不会落盘// join是两个rdd的操作,需要写好落盘过程studentRdd.map{case (stuid,name,age,classid) =>val className = bc.value.getOrElse(classid,"")(stuid,name,age,className)}.foreach(println(_))

若有收获,就点个赞吧
0 人点赞
