是什么?
分布式系统基础架构
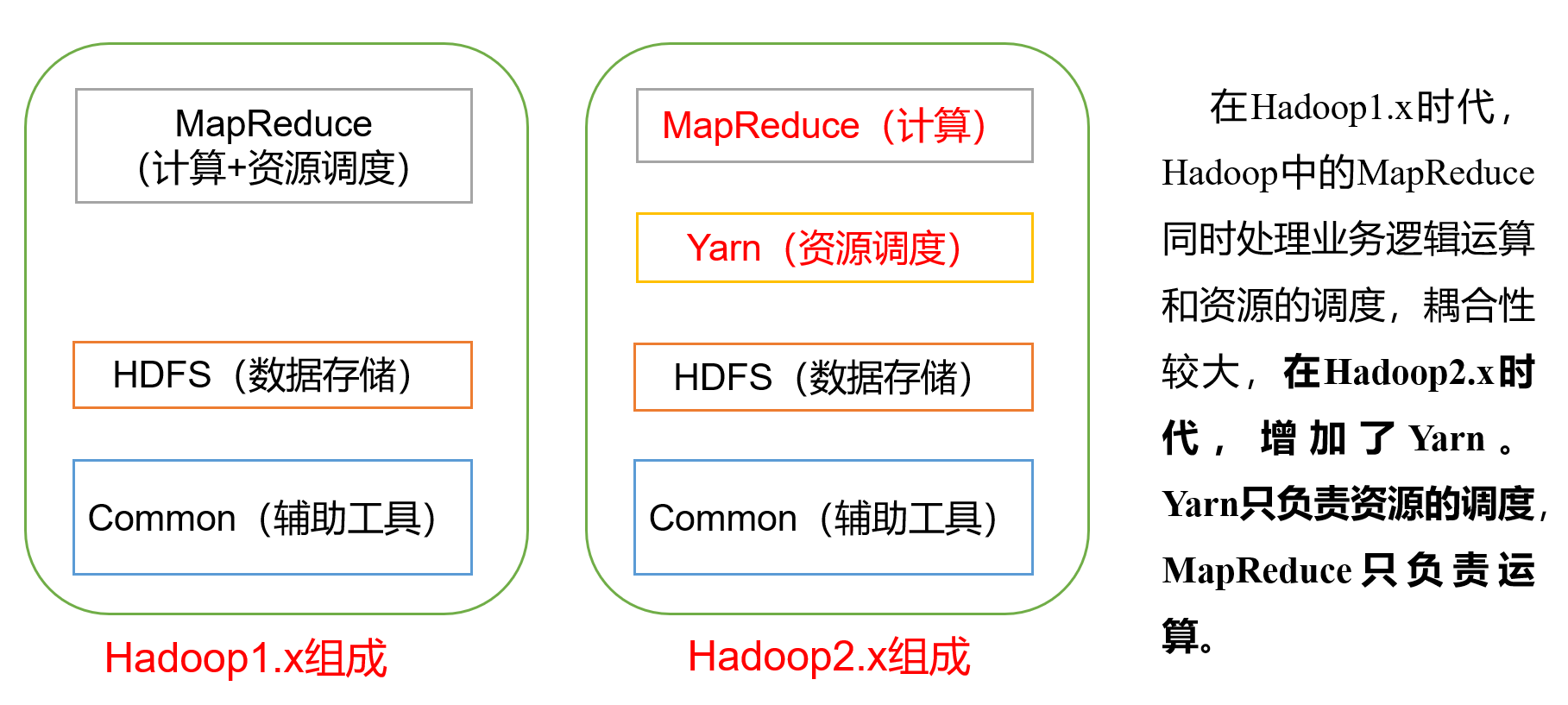
可以做什么?
- 海量数据存储
- 海量数据分析计算
广义上是?
现在指的是Hadoop生态圈,包括有例如spark等框架
环境搭建
JDK安装
Hadoop安装
编写集群分发脚本
分发环境变量配置文件
[atguigu@hadoop102 module]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh
SSH无密登录配置
集群配置(下面的配置文件)
配置历史服务器
启动历史服务
mapred —daemon start historyserver
配置日志的聚集
集群时间同步
配置文件:(官网可以查阅)
(1)核心配置文件[core-site.xml]
配置core-site.xml
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!--指定HDFS中NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop102:9820</value></property><!--指定Hadoop运行时产生文件的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><!-- 通过web界面操作hdfs的权限 --><property><name>hadoop.http.staticuser.user</name><value>atguigu</value></property><!-- 后面hive的兼容性配置 --><property><name>hadoop.proxyuser.atguigu.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.atguigu.groups</name><value>*</value></property><!-- 配置该atguigu(superUser)允许通过代理的用户--><property><name>hadoop.proxyuser.atguigu.users</name><value>*</value></property></configuration>
(2)HDFS配置文件[hdfs-site.xml]
配置hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value></property><property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value></property><!-- 测试环境指定HDFS副本的数量1 --><property><name>dfs.replication</name><value>3</value></property></configuration>
(3)YARN配置文件[yarn-site.xml]
配置yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- Reducer获取数据的方式,指定yarn走shuffle--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定YARN的ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><!-- 环境变量通过从NodeManagers的容器继承的环境属性,对于mapreduce应用程序,除了默认值hadoop op_mapred_home应该被添加外。属性值 还有如下--><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!--解决Yarn在执行程序遇到超出虚拟内存限制,Container被kill,生产环境不需要关闭 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property><!--后面hive的兼容性配置 --><!-- yarn容器(container)允许分配的最大最小内存 ,生产环境中默认即可--><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value></property><!-- yarn容器允许管理的物理内存大小,生产环境中分配所有内存的80% --><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><!-- yarn允许使用的cpu大小,生产环境中分配为最大核数的%80--><!-- 默认值为-1,意思是:--><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>2</value></property></configuration>
(4)MapReduce配置文件[mapred-site.xml]
配置mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MR运行在Yarn上--><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
3)在集群上分发配置好的Hadoop配置文件
xsync /opt/module/hadoop-3.1.3/etc/hadoop/
(5)workers(决定群起)
说明:群起命令需要读取这个配置文件,不设置则,则start-dfs.sh群起不会启动105,需要另外启动
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers在该文件中增加如下内容:hadoop102hadoop103hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
xsync /opt/module/hadoop-3.1.3/etc

若有收获,就点个赞吧
0 人点赞
