1、集群能同时运行job(多个行动算子)的个数有限
当多个job需要花费大量时间来计算处理数据的时候(比如一个job处理一亿条数据)
此时所有job都会占用满资源,进而导致后面的job数据无法计算
而导致了数据积压
此时需要调小receiver接收速率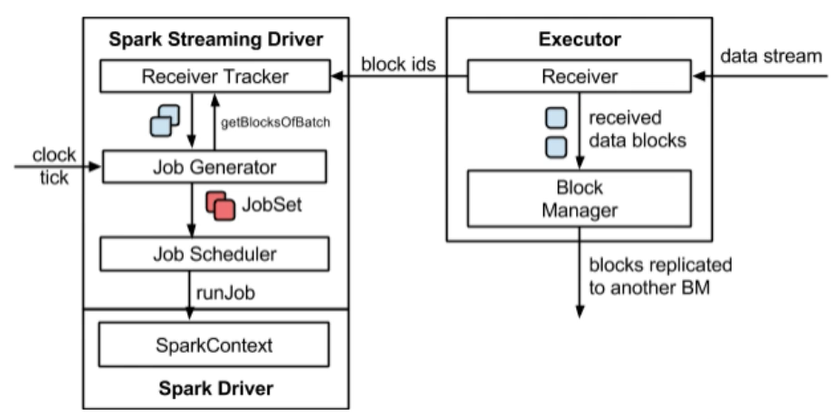
2、但是当生产者生产速度过大的时候,又需要receiver消费更多的数据
此时需要开启背压机制:
spark.streaming.backpressure.enabled

若有收获,就点个赞吧
0 人点赞
