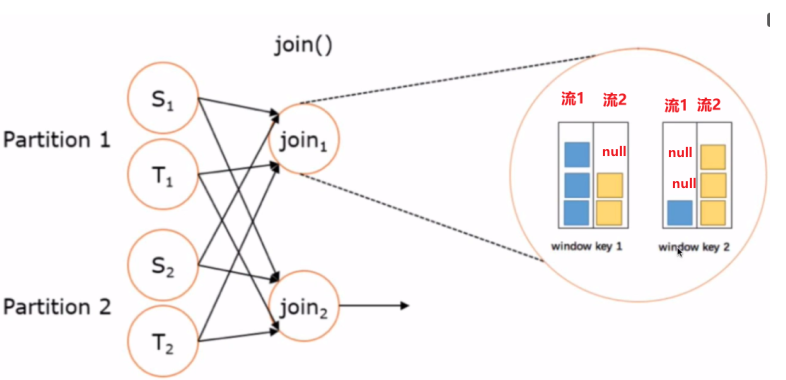
双流join
在Flink中, 支持两种方式的流的Join: Window Join和Interval Join,相当于inner join
还支持cogroup,相当于full join
cogroup
无论join不join得上,都会进行输出
Window Join
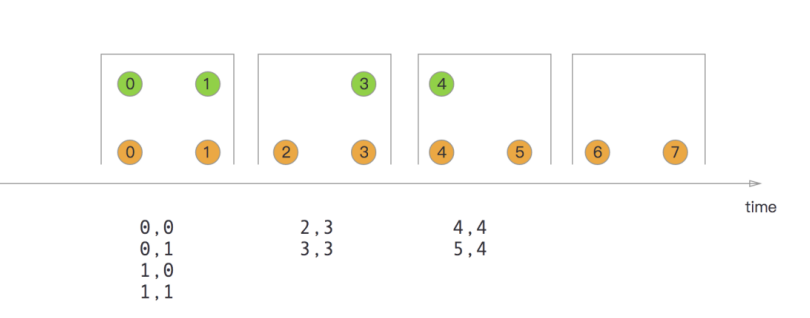
窗口join会join具有相同的key并且处于同一个窗口中的两个流的元素.
注意:
1. 所有的窗口join都是 inner join, 意味着a流中的元素如果在b流中没有对应的, 则a流中这个元素就不会处理(就是忽略掉了)
2. join成功后的元素的会以所在窗口的最大时间作为其时间戳. 例如窗口[5,10), 则元素会以9作为自己的时间戳
滚动窗口Join
| public class Flink01Join_Window_Tumbling **{
public static void main(String[] args) {
**StreamExecutionEnvironment env = StreamExecutionEnvironment._createLocalEnvironmentWithWebUI_(_new Configuration());
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> s1 = env<br /> .socketTextStream**_(_"hadoop162"**, 8888**_) _**_// 在socket终端只输入毫秒级别的时间戳<br /> _.map**_(_**value -> **_{<br />__ _**String**_[] _**datas = value.split**_(_","_)_**;<br /> **return new **WaterSensor**_(_**datas**_[_**0**_]_**, Long._valueOf_**_(_**datas**_[_**1**_])_**, Integer._valueOf_**_(_**datas**_[_**2**_]))_**;**_})<br />__ _**.assignTimestampsAndWatermarks**_(<br />__ _**WatermarkStrategy<br /> .<WaterSensor>_forMonotonousTimestamps_**_()<br />__ _**.withTimestampAssigner**_(_new **SerializableTimestampAssigner<WaterSensor>**_() {<br />__ _**@Override<br /> **public long **extractTimestamp**_(_**WaterSensor element, **long **recordTimestamp**_) {<br />__ _return **element.getTs**_() _*** 1000;<br /> **_}<br />__ })<br />__ )_**;SingleOutputStreamOperator<WaterSensor> s2 = env<br /> .socketTextStream**_(_"hadoop162"**, 9999**_) _**_// 在socket终端只输入毫秒级别的时间戳<br /> _.map**_(_**value -> **_{<br />__ _**String**_[] _**datas = value.split**_(_","_)_**;<br /> **return new **WaterSensor**_(_**datas**_[_**0**_]_**, Long._valueOf_**_(_**datas**_[_**1**_])_**, Integer._valueOf_**_(_**datas**_[_**2**_]))_**;<br /> **_})<br />__ _**.assignTimestampsAndWatermarks**_(<br />__ _**WatermarkStrategy<br /> .<WaterSensor>_forMonotonousTimestamps_**_()<br />__ _**.withTimestampAssigner**_(_new **SerializableTimestampAssigner<WaterSensor>**_() {<br />__ _**@Override<br /> **public long **extractTimestamp**_(_**WaterSensor element, **long **recordTimestamp**_) {<br />__ _return **element.getTs**_() _*** 1000;<br /> **_}<br />__ })<br />__ )_**;s1.join**_(_**s2**_)<br />__ _**.where**_(_**WaterSensor::getId**_)<br />__ _**.equalTo**_(_**WaterSensor::getId**_)<br />__ _**.window**_(_**TumblingEventTimeWindows._of_**_(_**Time._seconds_**_(_**5**_))) _**_// 必须使用窗口<br /> _.apply**_(_new **JoinFunction<WaterSensor, WaterSensor, String>**_() {<br />__ _**@Override<br /> **public **String join**_(_**WaterSensor first, WaterSensor second**_) _throws **Exception **_{<br />__ _return "first: " **+ first + **", second: " **+ second;<br /> **_}<br />__ })<br />__ _**.print**_()_**;**try _{<br />__ _**env.execute**_()_**;<br /> **_} _catch _(_**Exception e**_) {<br />__ _**e.printStackTrace**_()_**;<br /> **_}<br />__ }<br />__}_** |
| —- |
滑动窗口Join
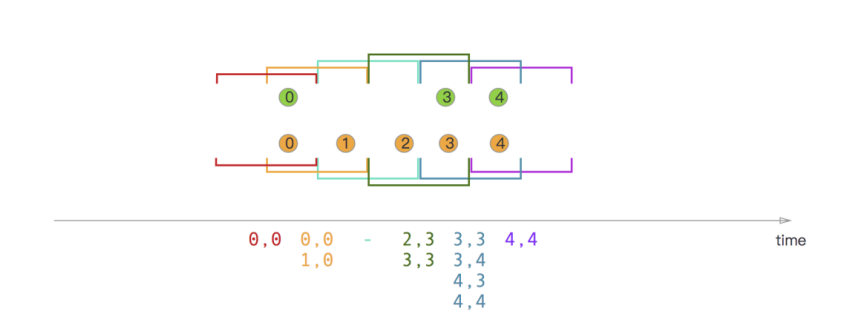
会话窗口Join

Interval Join
间隔流join(Interval Join), 是指使用一个流的数据按照key去join另外一条流的指定范围的数据.
如下图: 橙色的流去join绿色的流.范围是由橙色流的event-time + lower bound和event-time + upper bound来决定的.
orangeElem.ts + lowerBound <= greenElem.ts <= orangeElem.ts + upperBound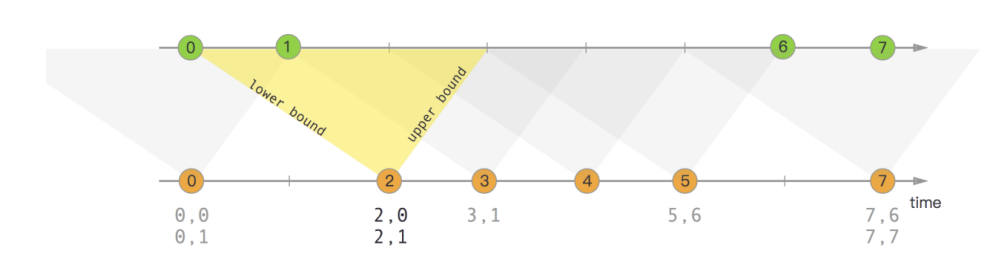
| 注意: 1) Interval Join只支持event-time 2) 必须是keyBy之后的流才可以interval join |
|---|
原理
interval join: <br /> ① 判断是否迟到,迟到就不处理<br /> ② 每条流,各自存了 Map类型的状态 ,来一条数据,就会存进去<br /> key=时间戳,value=数据的集合<br /> ③ 不管哪条流的数据来了,它都会去 对方的 Map状态里遍历 查看是否能匹配上<br /> ④ 超过区间时(水印),会清理Map对应的数据
| public class Flink01Join_Interval **{
public static void main(String[] args) {
**StreamExecutionEnvironment env = StreamExecutionEnvironment._createLocalEnvironmentWithWebUI_(_new Configuration());
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> s1 = env<br /> .socketTextStream**_(_"hadoop162"**, 8888**_) _**_// 在socket终端只输入毫秒级别的时间戳<br /> _.map**_(_**value -> **_{<br />__ _**String**_[] _**datas = value.split**_(_","_)_**;<br /> **return new **WaterSensor**_(_**datas**_[_**0**_]_**, Long._valueOf_**_(_**datas**_[_**1**_])_**, Integer._valueOf_**_(_**datas**_[_**2**_]))_**;**_})<br />__ _**.assignTimestampsAndWatermarks**_(<br />__ _**WatermarkStrategy<br /> .<WaterSensor>_forMonotonousTimestamps_**_()<br />__ _**.withTimestampAssigner**_(_new **SerializableTimestampAssigner<WaterSensor>**_() {<br />__ _**@Override<br /> **public long **extractTimestamp**_(_**WaterSensor element, **long **recordTimestamp**_) {<br />__ _return **element.getTs**_() _*** 1000;<br /> **_}<br />__ })<br />__ )_**;SingleOutputStreamOperator<WaterSensor> s2 = env<br /> .socketTextStream**_(_"hadoop162"**, 9999**_) _**_// 在socket终端只输入毫秒级别的时间戳<br /> _.map**_(_**value -> **_{<br />__ _**String**_[] _**datas = value.split**_(_","_)_**;<br /> **return new **WaterSensor**_(_**datas**_[_**0**_]_**, Long._valueOf_**_(_**datas**_[_**1**_])_**, Integer._valueOf_**_(_**datas**_[_**2**_]))_**;<br /> **_})<br />__ _**.assignTimestampsAndWatermarks**_(<br />__ _**WatermarkStrategy<br /> .<WaterSensor>_forMonotonousTimestamps_**_()<br />__ _**.withTimestampAssigner**_(_new **SerializableTimestampAssigner<WaterSensor>**_() {<br />__ _**@Override<br /> **public long **extractTimestamp**_(_**WaterSensor element, **long **recordTimestamp**_) {<br />__ _return **element.getTs**_() _*** 1000;<br /> **_}<br />__ })<br />__ )_**;s1<br /> .keyBy**_(_**WaterSensor::getId**_)<br />__ _**_ _.intervalJoin_(_s2.keyBy_(_WaterSensor::getId_))_****_ _**_// 指定上下界<br /> _.between**_(_**Time._seconds_**_(_**-2**_)_**, Time._seconds_**_(_**3**_))<br />__ _**.process**_(_new **ProcessJoinFunction<WaterSensor, WaterSensor, String>**_() {<br />__ _**@Override<br /> **public void **processElement**_(_**WaterSensor left, WaterSensor right, Context ctx, Collector<String> out**_) _throws **Exception **_{<br />__ _**out.collect**_(_**left + **"," **+ right**_)_**;<br /> **_}<br />__ })<br />__ _**.print**_()_**;**try _{<br />__ _**env.execute**_()_**;<br /> **_} _catch _(_**Exception e**_) {<br />__ _**e.printStackTrace**_()_**;<br /> **_}<br />__ }<br />__}_** |
| —- |
_

若有收获,就点个赞吧
0 人点赞
