副本机制
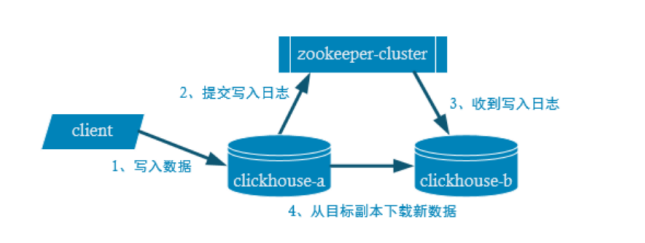
通过zookeeper监控数据,获取副本
副本是表级别的,不是整个服务器级的。所以,服务器里可以同时有复本表和非复本表。
对于 INSERT 和ALTER 语句操作数据会在压缩的情况下被复制
而CREATE,DROP,ATTACH,DETACH 和 RENAME 语句只会在单个服务器上执行,不会被复制
所以建表的时候, 需要在2个节点上分别手动建表,除非在配置文件中使用宏
副本的建表语句说明
在hadoop102建表create table rep_t_order_mt2020 (id UInt32,sku_id String,total_amount Decimal(16,2),create_time Datetime) engine =ReplicatedMergeTree('/clickhouse/tables/01/rep_t_order_mt2020','rep_hadoop102')partition by toYYYYMMDD(create_time)primary key (id)order by (id,sku_id);在hadoop103上建表create table rep_t_order_mt2020 (id UInt32,sku_id String,total_amount Decimal(16,2),create_time Datetime) engine =ReplicatedMergeTree('/clickhouse/tables/01/rep_t_order_mt2020','rep_hadoop103')partition by toYYYYMMDD(create_time)primary key (id)order by (id,sku_id);
说明:ReplicatedMergeTree('/clickhouse/tables/01/rep_t_order_mt2020','rep_hadoop103')
参数1: 该表在zookeeper中的路径.
/clickhouse/tables/{shard}/{table_name} 通常写法,
shard表示表的分片编号, 一般用01,02,03…表示
table_name 一般和表明保持一致就行
参数2: 在zookeeper中的复本名. 相同的表, 复本名不能相同
分片集群(类似hdfs进行切片)
复本虽然能够提高数据的可用性,降低丢失风险,但是对数据的横向扩容没有解决。每台机子实际上必须容纳全量数据。
要解决数据水平切分的问题,需要引入分片的概念。
通过分片把一份完整的数据进行切分,不同的分片分布到不同的节点上。
在通过Distributed表引擎把数据拼接起来一同使用。
Distributed表引擎本身不存储数据,有点类似于MyCat之于MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据。
写
3个切片:S1,S2,S3
3个副本:R1,R2,R3
distribute表使用hash的方法计算切片后对切片进行分配,存完切片后再做副本
不要通过本地表去写如,如果这样写入再使用distribute表查是查不到的!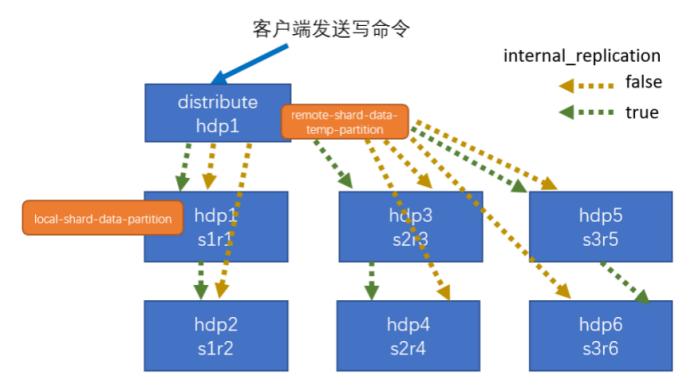
读
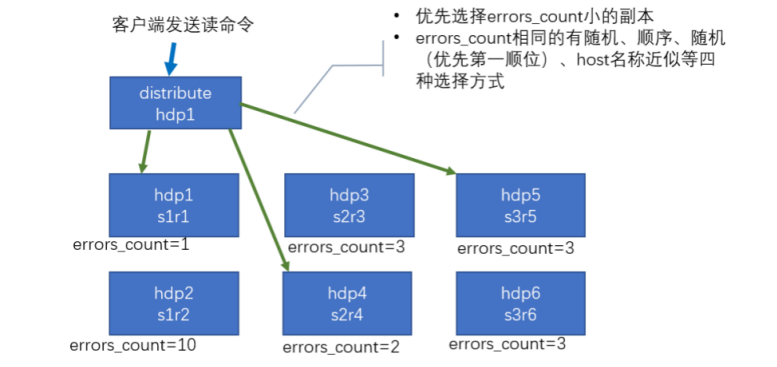
配置集群分片案例
每台机器的宏配置需要分别进行修改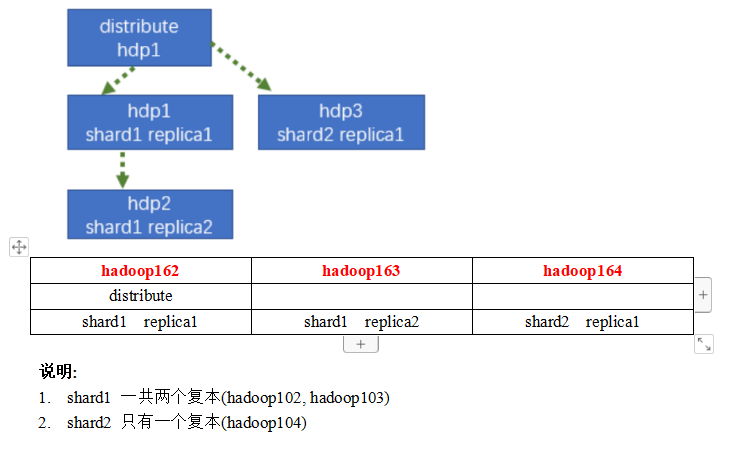

若有收获,就点个赞吧
0 人点赞
