Group Windows
Table API
滚动窗口
每2s统计最近10s每个传感器的水位和
| public class Flink08TableApi_Window_1 **{
public static void main(String[] args) throws Exception {
**StreamExecutionEnvironment env = StreamExecutionEnvironment._getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator
.fromElements_(_new WaterSensor(“sensor_1”, 1000L, 10),
new WaterSensor(“sensor_1”, 2000L, 20),
new WaterSensor(“sensor_2”, 3000L, 30),
new WaterSensor(“sensor_1”, 4000L, 40),
new WaterSensor(“sensor_1”, 5000L, 50),
new WaterSensor(“sensor_2”, 6000L, 60))
__ .assignTimestampsAndWatermarks(
__ WatermarkStrategy
.
__ .withTimestampAssigner((element, recordTimestamp) -> element.getTs())
__ );
StreamTableEnvironment tableEnv = StreamTableEnvironment._create_**_(_**env**_)_**;Table table = tableEnv<br /> .fromDataStream**_(_**waterSensorStream, _$_**_(_"id"_)_**, _$_**_(_"ts"_)_**.rowtime**_()_**, _$_**_(_"vc"_))_**;table<br /> .window**_(_**Tumble._over_**_(_**_lit_**_(_**10**_)_**.second**_())_**.on**_(_**_$_**_(_"ts"_))_**.as**_(_"w"_)) __// 定义滚动窗口并给窗口起一个别名<br />_**_ _.groupBy**_(_**_$_**_(_"id"_)_**, _$_**_(_"w"_)) __// 窗口必须出现的分组字段中_**_ _**.select**_(_**_$_**_(_"id"_)_**, _$_**_(_"w"_)_**.start**_()_**, _$_**_(_"w"_)_**.end**_()_**, _$_**_(_"vc"_)_**.sum**_())<br />__ _**.execute**_()<br />__ _**.print**_()_**;<br /> env.execute**_()_**;<br /> **_}<br />__}_** |
| —- |
滑动窗口
| .window(Slide.over(lit(10).second()).every(lit(5).second()).on($(“ts”)).as(“w”)) |
|---|
会话窗口
| .window(Session.withGap(lit(6).second()).on($(“ts”)).as(“w”)) |
|---|
SQL API
SQL 查询的分组窗口是通过 GROUP BY 子句定义的。类似于使用常规 GROUP BY 语句的查询,窗口分组语句的 GROUP BY 子句中带有一个窗口函数为每个分组计算出一个结果。以下是批处理表和流处理表支持的分组窗口函数:
| 分组窗口函数 | 描述 |
|---|---|
| TUMBLE(time_attr, interval) | 定义一个滚动窗口。滚动窗口把行分配到有固定持续时间( interval )的不重叠的连续窗口。比如,5 分钟的滚动窗口以 5 分钟为间隔对行进行分组。滚动窗口可以定义在事件时间(批处理、流处理)或处理时间(流处理)上。 |
| HOP(time_attr, interval, interval) | 定义一个跳跃的时间窗口(在 Table API 中称为滑动窗口)。滑动窗口有一个固定的持续时间( 第二个 interval 参数 )以及一个滑动的间隔(第一个 interval 参数 )。若滑动间隔小于窗口的持续时间,滑动窗口则会出现重叠;因此,行将会被分配到多个窗口中。比如,一个大小为 15 分组的滑动窗口,其滑动间隔为 5 分钟,将会把每一行数据分配到 3 个 15 分钟的窗口中。滑动窗口可以定义在事件时间(批处理、流处理)或处理时间(流处理)上。 |
| SESSION(time_attr, interval) | 定义一个会话时间窗口。会话时间窗口没有一个固定的持续时间,但是它们的边界会根据 interval 所定义的不活跃时间所确定;即一个会话时间窗口在定义的间隔时间内没有时间出现,该窗口会被关闭。例如时间窗口的间隔时间是 30 分钟,当其不活跃的时间达到30分钟后,若观测到新的记录,则会启动一个新的会话时间窗口(否则该行数据会被添加到当前的窗口),且若在 30 分钟内没有观测到新纪录,这个窗口将会被关闭。会话时间窗口可以使用事件时间(批处理、流处理)或处理时间(流处理)。 |

| StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 作为事件时间的字段必须是 timestamp 类型, 所以根据 long 类型的 ts 计算出来一个 t
_tEnv.executeSql**(“create table sensor(“ +
“id string,” +
“ts bigint,” +
“vc int, “ +
“t as to_timestamp(from_unixtime(ts/1000,’yyyy-MM-dd HH:mm:ss’)),” +
“watermark for t as t - interval ‘5’ second)” +
“with(“
+ “‘connector’ = ‘filesystem’,”
+ “‘path’ = ‘input/sensor.txt’,”
+ “‘format’ = ‘csv’”
+ “)”)_**;
tEnv
.sqlQuery(
__ “SELECT id, “ +
“ TUMBLE_START(t, INTERVAL ‘1’ minute) as wStart, “ +
“ TUMBLE_END(t, INTERVAL ‘1’ minute) as wEnd, “ +
“ SUM(vc) sum_vc “ +
“FROM sensor “ +
“GROUP BY TUMBLE(t, INTERVAL ‘1’ minute), id”
)
__ .execute()
__ .print();
tEnv
.sqlQuery(
“SELECT id, “ +
“ hopstart(t, INTERVAL ‘1’ minute, INTERVAL ‘1’ hour) as wStart, “ +
“ hop_end(t, INTERVAL ‘1’ minute, INTERVAL ‘1’ hour) as wEnd, “ +
“ SUM(vc) sum_vc “ +
“FROM sensor “ +
“GROUP BY hop(t, INTERVAL ‘1’ minute, INTERVAL ‘1’ hour), id”
)
.execute()
.print()_; |
| —- |
Over Windows
概述
目前只支持sum、min、max等窗口的开窗,rank等暂时不能
无界的over window是使用常量指定的。
也就是说,时间间隔要指定UNBOUNDED_RANGE,或者行计数间隔要指定UNBOUNDED_ROW。
而有界的over window是用间隔的大小指定的。
如果不是做topN,则over中的orderby只能是时间字段的升序
FLINK只支持preceding不支持following,因为数据是实时数据,没有办法统计当前行以下的数据
Windows范围 ,只有 preceding
基于行
①UNBOUNDEDROW _,不存在想同行,所有没有数据同在一个窗口的说法。.window(Over.partitionBy($("id")).orderBy($("ts")).preceding(UNBOUNDED_ROW).as("w"))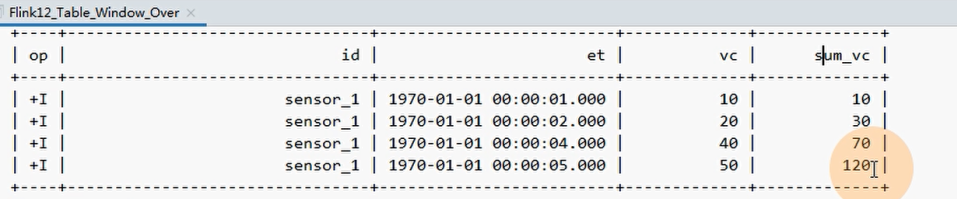
②preceding(rowInterval(1L))__ 往前1行.window(Over.partitionBy($("id")).orderBy($("et")).preceding(rowInterval(1L)).as("w"))
基于时间
①UNBOUNDEDRANGE_,相同时间位于同一窗口.window(Over.partitionBy($("id")).orderBy($("et")).preceding(UNBOUNDED_RANGE).as("w"))
说明:
当前时间窗口current range:20+30=50,
上无边界时间窗口UNBOUNDEDRANGE是:10,
所以最终结果是10+50=60
**②preceding(lit(1).second()) **往前1秒
`.window(Over._partitionBy($(“id”)).orderBy($(“et”)).preceding(lit(_1).second()).as(“w”))_`
Table API
具体分类看上面
①UNBOUNDEDROW _,不存在想同行,所有没有数据同在一个窗口的说法。.window(Over.partitionBy($("id")).orderBy($("ts")).preceding(UNBOUNDED_ROW).as("w"))
②preceding(rowInterval(1L))__ 往前1行.window(Over.partitionBy($("id")).orderBy($("et")).preceding(rowInterval(1L)).as("w"))
①UNBOUNDEDRANGE_,相同时间位于同一窗口.window(Over.partitionBy($("id")).orderBy($("et")).preceding(UNBOUNDED_RANGE).as("w"))
②preceding(lit(1).second()) 往前1秒.window_(_Over._partitionBy($(_"id"_))_.orderBy_($(_"et"_))_.preceding_(lit(_1_)_.second_())_.as_(_"w"_))_
public class Flink09_TableApi_OverWindow_1 {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> waterSensorStream = env.fromElements(new WaterSensor("sensor_1", 1000L, 10),new WaterSensor("sensor_1", 4000L, 40),new WaterSensor("sensor_1", 2000L, 20),new WaterSensor("sensor_2", 3000L, 30),new WaterSensor("sensor_1", 5000L, 50),new WaterSensor("sensor_2", 6000L, 60)).assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(1)).withTimestampAssigner((element, recordTimestamp) -> element.getTs()));StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);Table table = tableEnv.fromDataStream(waterSensorStream, $("id"), $("ts").rowtime(), $("vc"));table// 使用UNBOUNDED_ROW (基于行),不存在想同行,所有没有数据同在一个窗口的说法。// 往前1行:preceding(rowInterval(1L)).window(Over.partitionBy($("id")).orderBy($("ts")).preceding(UNBOUNDED_ROW).as("w")).select($("id"), $("ts"), $("vc").sum().over($("w")).as("sum_vc")).execute().print();env.execute();}}
SQL API
如果不指定over windows 范围 ,则默认是range:sum(vc) over(partition by id order by t)
row:
与hive一样
range:range between unbounded preceding and current rowrange between interval '1' second preceding and current row
tenv.sqlQuery("select" +" id," +" et," +" vc," +// flink不能一次写多个窗口范围不同的窗口,下面的例子只是demo" sum(vc) over(partition by id order by et rows between unbounded preceding and current row) vc_sum, " +" max(vc) over(partition by id order by et rows between unbounded preceding and current row) vc_max, " +" min(vc) over(partition by id order by et rows between unbounded preceding and current row) vc_min " +" sum(vc) over(partition by id order by et rows between 1 preceding and current row) vc_sum2 " +" sum(vc) over(partition by id order by et range between unbounded preceding and current row) vc_sum2 " +" sum(vc) over(partition by id order by et range between interval '1' second preceding and current row) vc_sum2 " +"from sensor ").execute().print();
多个聚合函数的情况,可以将窗口部分提出来使用
tenv.sqlQuery("select" +" id," +" et," +" vc," +" sum(vc) over w sum_vc, " +" max(vc) over w vc_max, " +" min(vc) over w vc_min " +"from default_catalog.default_database.sensor " +"window w as (partition by id order by et rows between unbounded preceding and current row)").execute().print();

若有收获,就点个赞吧
0 人点赞
