
hive on spark原理
是把hive查询从mapreduce 的mr (Hadoop计算引擎)操作替换为spark rdd(spark 执行引擎)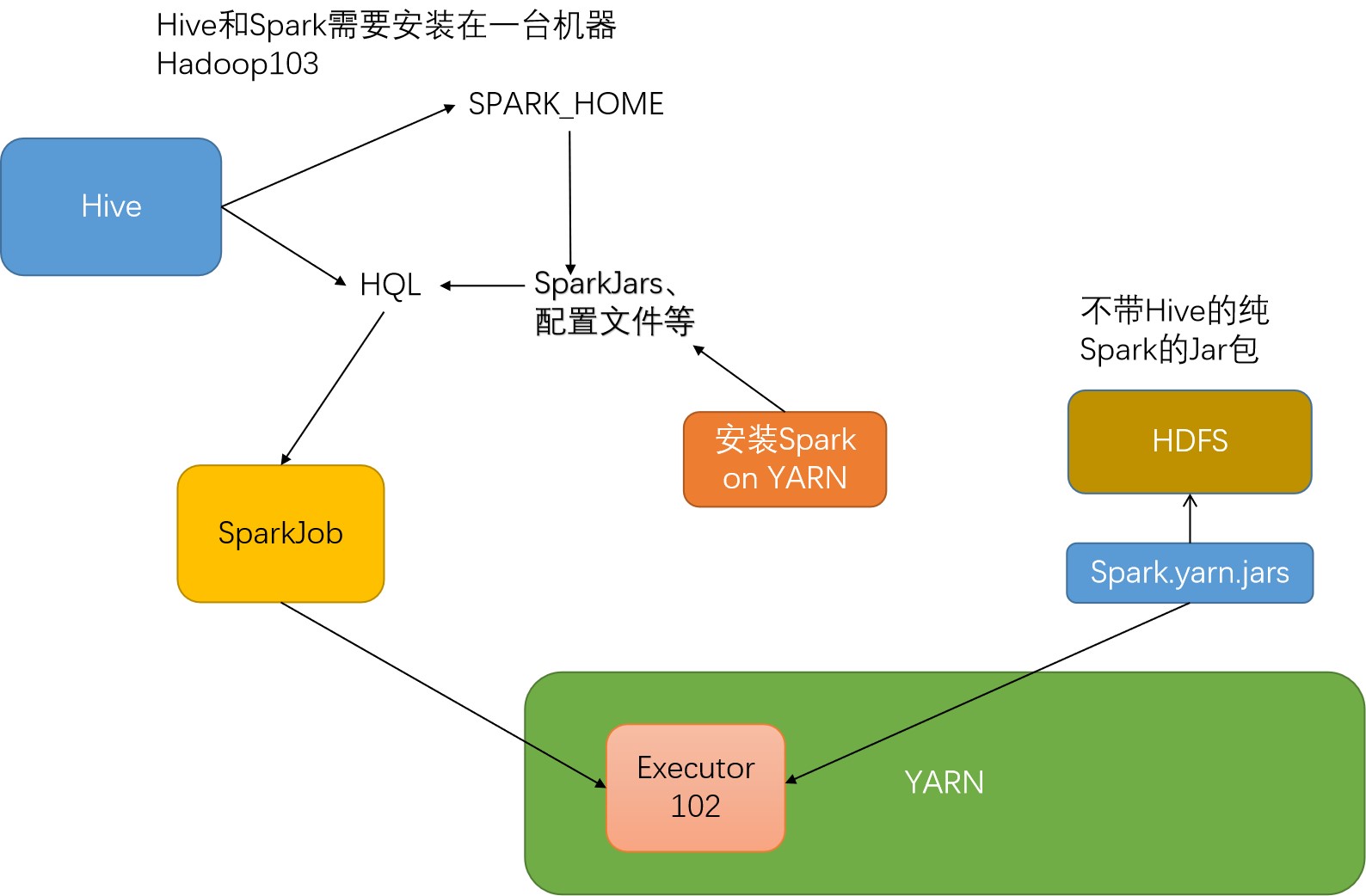
hive与spark的安装问题
HIVE写SparkJob也需要 new SparkContext,也就是说hive也需要spark依赖
所以hive和spark需要安装在同一台机器上,获取spark的jar包
这时hive需要读取一个SPARK_HOME的环境变量来找到spark的jar以及相关配置文件
executor的加载问题
同时YARN模式的Spark是分布式的,需要获得相关jar包来加载不同节点上的Executor
所以需要配置一个Spark.yarn.jars变量,来上传加载excutor所需的jar包
如果不指明则会自动将找到SPARK_HOME,将SPARK_HOME上所有jar包上传至hdfs上
这时候因为spark自带了hive,就会上传hive2.3.x的jar包,而我们现在使用的是hive3.x的版本,有可能会产生冲突
所以我们需要安装一个纯净不带hive的spark,将其jar上传到hdfs 上面去
配置
总配置hive-site.xml
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--用utf8方式连接mysql --><configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop162:3306/metastore?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>aaaaaa</value></property><property><name>hive.metastore.schema.verification</name><value>false</value></property><!--Spark依赖位置--><property><name>spark.yarn.jars</name><value>hdfs://hadoop162:9820/sparkjars/*</value></property><!--Hive执行引擎(默认是mr)--><property><name>hive.execution.engine</name><value>spark</value></property><property><name>mapreduce.job.queuename</name><value>hive</value></property><!--配置hive专门运行的队列--><property><name>mapreduce.job.queuename</name><value>hive</value></property></configuration>
配置hive连接mysql
客户端读写需要支持中文:
由以下配置确定,以下配置已经在上面
<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8</value></property>
在元数据表中的收到中文影响的表:
表的注释:
TABLE_PARAMS表可以看到mysql的字符集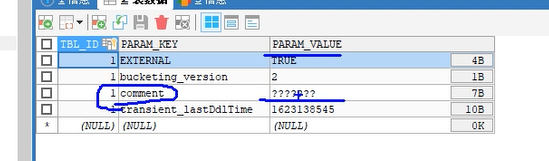
列的注释:
COLUMNS_V2表可以看到列的编码情况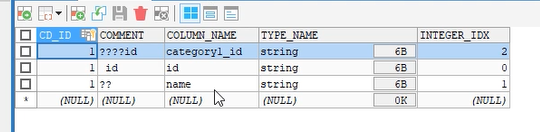
通过语句改变相关表编码:
在Hive元数据存储的Mysql数据库中,执行以下SQL:
#修改字段注释字符集alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;#修改表注释字符集alter table TABLE_PARAMS modify column PARAM_VALUE varchar(20000) character set utf8;#修改分区参数,支持分区建用中文表示alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(20000) character set utf8;alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(20000) character set utf8;#修改索引名注释,支持中文表示alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;#修改视图,支持视图中文ALTER TABLE TBLS modify COLUMN VIEW_EXPANDED_TEXT mediumtext CHARACTER SET utf8;ALTER TABLE TBLS modify COLUMN VIEW_ORIGINAL_TEXT mediumtext CHARACTER SET utf8;
配置容量调度器为多队列
编辑$HADOOP_HOME/etc/hadoop/capacity-schdualer.xml
此参数可配置:
多个队列
每个队列所占初始比例(容量调度器队列容量能相互借用)
每个AM最多能调用的资源比例
当前队列中启动的MR AppMaster进程,所占用的资源可以达到队列总资源的多少,
通过这个参数可以限制队列中提交的Job数量
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.--><configuration><!-- 容量调度器最多可以容纳多少个job--><property><name>yarn.scheduler.capacity.maximum-applications</name><value>10000</value><description>Maximum number of applications that can be pending and running.</description></property><!-- 当前队列中启动的MR AppMaster进程,所占用的资源可以达到队列总资源的多少通过这个参数可以限制队列中提交的Job数量--><property><name>yarn.scheduler.capacity.maximum-am-resource-percent</name><value>0.5</value><description>Maximum percent of resources in the cluster which can be used to runapplication masters i.e. controls number of concurrent runningapplications.</description></property><!-- 为Job分配资源时,使用什么策略进行计算--><property><name>yarn.scheduler.capacity.resource-calculator</name><value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value><description>The ResourceCalculator implementation to be used to compareResources in the scheduler.The default i.e. DefaultResourceCalculator only uses Memory whileDominantResourceCalculator uses dominant-resource to comparemulti-dimensional resources such as Memory, CPU etc.</description></property><!-- root队列中有哪些子队列--><property><name>yarn.scheduler.capacity.root.queues</name><value>default,hive</value><description>The queues at the this level (root is the root queue).</description></property><!-- root队列中default队列占用的容量百分比30%所有子队列的容量相加必须等于100--><property><name>yarn.scheduler.capacity.root.default.capacity</name><value>30</value><description>Default queue target capacity.</description></property><!-- root队列中hive队列占用的容量百分比70%所有子队列的容量相加必须等于100--><property><name>yarn.scheduler.capacity.root.hive.capacity</name><value>70</value><description>Default queue target capacity.</description></property><!-- 队列中用户能使用此队列资源的极限百分比--><property><name>yarn.scheduler.capacity.root.default.user-limit-factor</name><value>1</value><description>Default queue user limit a percentage from 0.0 to 1.0.</description></property><property><name>yarn.scheduler.capacity.root.hive.user-limit-factor</name><value>1</value><description>Default queue user limit a percentage from 0.0 to 1.0.</description></property><!-- root队列中default队列占用的容量百分比的最大值--><property><name>yarn.scheduler.capacity.root.default.maximum-capacity</name><value>100</value><description>The maximum capacity of the default queue.</description></property><property><name>yarn.scheduler.capacity.root.hive.maximum-capacity</name><value>100</value><description>The maximum capacity of the default queue.</description></property><!-- root队列中每个队列的状态--><property><name>yarn.scheduler.capacity.root.default.state</name><value>RUNNING</value><description>The state of the default queue. State can be one of RUNNING or STOPPED.</description></property><property><name>yarn.scheduler.capacity.root.hive.state</name><value>RUNNING</value><description>The state of the default queue. State can be one of RUNNING or STOPPED.</description></property><!-- 限制向default队列提交的用户--><property><name>yarn.scheduler.capacity.root.default.acl_submit_applications</name><value>*</value><description>The ACL of who can submit jobs to the default queue.</description></property><property><name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name><value>*</value><description>The ACL of who can submit jobs to the default queue.</description></property><property><name>yarn.scheduler.capacity.root.default.acl_administer_queue</name><value>*</value><description>The ACL of who can administer jobs on the default queue.</description></property><property><name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name><value>*</value><description>The ACL of who can administer jobs on the default queue.</description></property><property><name>yarn.scheduler.capacity.node-locality-delay</name><value>40</value><description>Number of missed scheduling opportunities after which the CapacitySchedulerattempts to schedule rack-local containers.Typically this should be set to number of nodes in the cluster, By default is settingapproximately number of nodes in one rack which is 40.</description></property><property><name>yarn.scheduler.capacity.queue-mappings</name><value></value><description>A list of mappings that will be used to assign jobs to queuesThe syntax for this list is [u|g]:[name]:[queue_name][,next mapping]*Typically this list will be used to map users to queues,for example, u:%user:%user maps all users to queues with the same nameas the user.</description></property><property><name>yarn.scheduler.capacity.queue-mappings-override.enable</name><value>false</value><description>If a queue mapping is present, will it override the value specifiedby the user? This can be used by administrators to place jobs in queuesthat are different than the one specified by the user.The default is false.</description></property></configuration>
分发到集群,重启YARN!因为每个nodemanage都需要知能启动多少资源
在hive-site.xml中添加:
<property><name>mapreduce.job.queuename</name><value>hive</value></property>
官方保证不冲突的hive与spark版本
- The User and Hive SQL documentation shows how to program Hive
Version Compatibility
Hive on Spark is only tested with a specific version of Spark, so a given version of Hive is only guaranteed to work with a specific version of Spark. Other versions of Spark may work with a given version of Hive, but that is not guaranteed. Below is a list of Hive versions and their corresponding compatible Spark versions.
| Hive Version | Spark Version |
|---|---|
| master | 2.3.0 |
| 3.0.x | 2.3.0 |
| 2.3.x | 2.0.0 |
| 2.2.x | 1.6.0 |
| 2.1.x | 1.6.0 |
| 2.0.x | 1.5.0 |
| 1.2.x | 1.3.1 |
| 1.1.x | 1.2.0 |

若有收获,就点个赞吧
0 人点赞
