概述
基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
Hive本质:将HQL转化成MapReduce程序
(1)Hive处理的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce
(3)执行程序运行在Yarn上
数据类型
结构化数据(就是表)
非结构化数据(例如网址那些)
能处理的数据类型
mapreduce可以处理任何数据。
HIVE只能处理结构化数据(封装了mapreduce的操作表的代码),给结构化数据添加元数据(用mysql存储)。
优点
开发效率高
处理数据量大
缺点
1)Hive的HQL表达能力有限
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化,处理的数据只能是可以写sql的结构化数据
(2)数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现。
2)Hive的效率比较低
(1)因为基于MapReduce,所以Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
(2)Hive调优比较困难,粒度较粗
(3)没有索引需要扫描整张表来寻找数据
3)Hive不支持实时查询和行级别更新
(1)hive分析的数据是存储在hdfs上,hdfs不支持随机写,只支持追加写,所以在hive中不能delete和update,只能select和insert
框架原理:
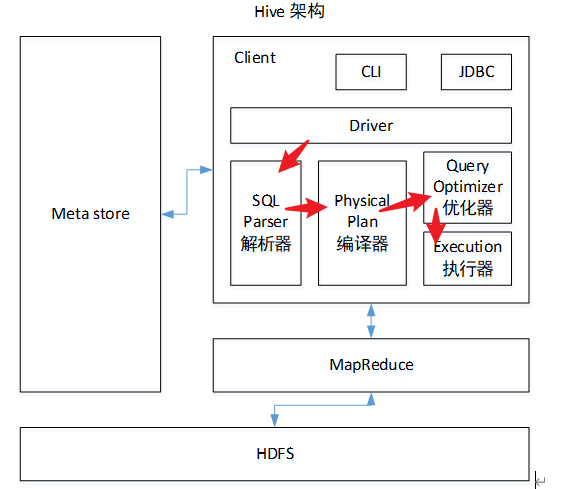
Driver 組件:
將sql解析為java代碼,之後通過編譯器編譯,然後傳遞給優化器優化,最後通過執行器生成執行計劃傳遞給mapreduce運行。
1、metastore 元数据,存储在mysql中
元数据相关内容:
https://cloud.tencent.com/developer/article/1701068
metastore 作用:
映射表的结构,表的操作sql等操作都是基于元数据库的
metastore 连接模式
远程模式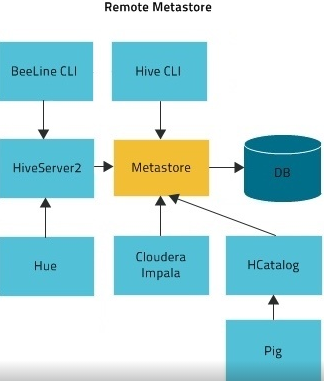
本地模式
2、CLI\JDBC都是接口用于连接客户端

若有收获,就点个赞吧
0 人点赞
