map
/*
map(func: RDD元素类型=> B ): 映射
map一般用于数据转换[类型的转换、值的转换]
map里面的函数是针对RDD每个元素进行操作,后续会将RDD每个元素传递函数的参数,RDD中元素有多少个,函数就会调用多少次
val rdd2 = rdd1.map(…) 此时rdd2元素的个数 = rdd1元素个数
map的应用场景: 一对一
*/
@Testdef map(): Unit ={val rdd = sc.parallelize(List(10,2,6,3,7,9))val rdd2 = rdd.map( x => {println(s"${Thread.currentThread().getName}")x * x})
mapPartitions
/*
mapPartitions(func: 迭代器[RDD元素类型]=>迭代器[B])
mapPartitions里面的函数是针对一整个分区进行处理,后续会将一个分区所有数据用迭代器封装之后传递给函数的参数
rdd有多少分区,mapPartitions里面的函数就会调用多少次
处理大量数据的时候,mapPartitions因为是对每个分区中的所有数据进行处理,不用频繁开启资源、关闭资源,效率会快很多
(map的缺陷:针对每个元素进行操作,假如map方法体中用jdbc连接数据库,那么每个元素的获取值的时候需要启动和关闭jdbc)
map与mapPartitions的区别:
1、函数针对的对象不一样:
map中的函数针对的是RDD每个元素
mapPartitions里面的函数针对的是RDD每个分区
2、返回类型不一样:
map要求返回一个元素,对于类型没有要求,map生成的新RDD元素个数等于原来RDD元素个数.
mapPartitions要求返回一个迭代器,mapPartitions生成的新RDD元素个数可能不等于原来RDD元素个数.
3、元素内存释放的时机不一样
map里面的函数是针对单个元素处理,元素处理完成之后就可以回收元素内存
mapPartitions里面的函数针对的是RDD一个分区的所有数据的迭代器,需要等到一个分区所有数据全部处理完成之后才能回收内存。mapPartitions又能出现内存溢出,出现内存溢出之后可以用map代替【完成比完美要重要】
*/
@Testdef mapPartitions(): Unit ={//useridval rdd = sc.parallelize(List(10,2,6,3,7,9))//获取用户的信息[姓名、年龄、地址、id],用户的信息在mysql表中rdd.map(id=>{var name:String = nullvar address:String = nullvar age:Int = -1var connection:Connection = nullvar statement:PreparedStatement = nulltry{connection = DriverManager.getConnection("jdbc:mysql://hadoop102:3306/test")statement = connection.prepareStatement("select * from person where id=?")statement.setInt(1,id)val set = statement.executeQuery()while (set.next()){name = set.getString("name")address = set.getString("address")age = set.getInt("age")}(id,name,age,address)}catch {case e:Exception => (id,name,age,address)}finally {if(statement!=null)statement.close()if(connection!=null)connection.close()}id}).collect()val rdd3 = rdd.mapPartitions(it=>{println("mapPartitions-"+Thread.currentThread().getName)it.filter(_%2==0)/*var connection:Connection = nullvar statement:PreparedStatement = nullvar list = List[(String,Int,String,Int)]()try{connection = DriverManager.getConnection("jdbc:mysql://hadoop102:3306/test")statement = connection.prepareStatement("select * from person where id=?")var name:String = nullvar address:String = nullvar age:Int = -1it.foreach(id=>{statement.setInt(1,id)val set = statement.executeQuery()while (set.next()){name = set.getString("name")address = set.getString("address")age = set.getInt("age")}list = (name,age,address,id) :: list})}catch {case e:Exception => list}finally {if(statement!=null)statement.close()if(connection!=null)connection.close()}list.iterator*/})println(rdd3.collect().toList)}
mapPartitionsWithIndex
/*
mapPartitionsWithIndex(func: (Int,迭代器[RDD元素类型]) =>迭代器[B])
mapPartitionsWithIndex与mapPartitions的区别:
mapPartitionsWithIndex里面的函数比mapPartitions里面的函数多了一个索引号
mapPartitionsWith里面的函数是针对一整个分区进行处理,后续会将一个分区所有数据用迭代器封装之后传递给函数的第二个参数
rdd有多少分区,mapPartitionsWithIndex里面的函数就会调用多少次
*/
@Testdef mapPartitionsWithIndex(): Unit ={val rdd = sc.parallelize(List(10,3,6,4,2,9))val result = rdd.mapPartitionsWithIndex( (index,it) => {println(s"index=${index} data=${it.toList}")it} ).collect()println(result.toList)}
flatmap
/*
flatMap = map + flatten
flatMap(func: RDD元素类型 => 集合[B] )
flatMap里面的函数也是针对RDD每个元素操作,元素有多少个函数就调用多少次
*/
@Testdef flatMap(): Unit ={val rdd = sc.parallelize(List( List(1,2),List(2,3) ))val rdd2 = rdd.flatMap( x=> x )println(rdd2.collect().toList)}
glom
/*
glom: 将一个分区所有数据用数组封装
glom生成的RDD元素个数 = 分区数
/
@Testdef glom(): Unit ={val rdd = sc.parallelize(List(1,2,3,4,5,6,6,8,8,9,0))rdd.mapPartitionsWithIndex((index,it)=>{println(s"index:${index} data:${it.toList}")it}).collect()val rdd2 = rdd.glom()val result = rdd2.collect()result.foreach(x=>println(x.toList))}
groupBy
/*
groupBy(func: RDD元素类型=>K): 根据指定字段分组
groupBy后续是根据函数的返回值进行分组
groupBy针对的也是RDD每个元素操作,元素有多少个,函数调用多少次
MR 整个过程: file -> inputformat -> map -> 缓冲区 -> 缓冲区分区排序 -> 溢写 -> combiner -> 磁盘 -> reduce拉取数据 -> 归并排序 -> reduce -> 磁盘
shuffle过程: 缓冲区 -> 缓冲区分区排序 -> 溢写 -> combiner -> 磁盘 ->归并-> reduc e拉取数据 -> 归并排序
Spark shuffle过程: 缓冲区 -> 缓冲区分区[排序] -> 溢写 -> combiner -> 磁盘 -> rdd分区拉取数据
/
@Testdef groupBy(): Unit ={val rdd = sc.parallelize(List("hello","spark","spark","java"))val rdd2 = rdd.groupBy(x=>x)println(rdd2.collect().toList)}
filter
/*
filter(func: RDD元素类型=>Boolean ): 过滤
filter保留的是函数返回值为true的数据
filter中的函数是针对RDD每个元素操作,元素有多少个,函数就调用多少次
*/
@Testdef filter(): Unit ={val rdd = sc.parallelize(List(10,2,5,7,9,3,20,4))val rdd2 = rdd.filter(x=> x%2==0)println(rdd2.collect().toList)}
sample
/*
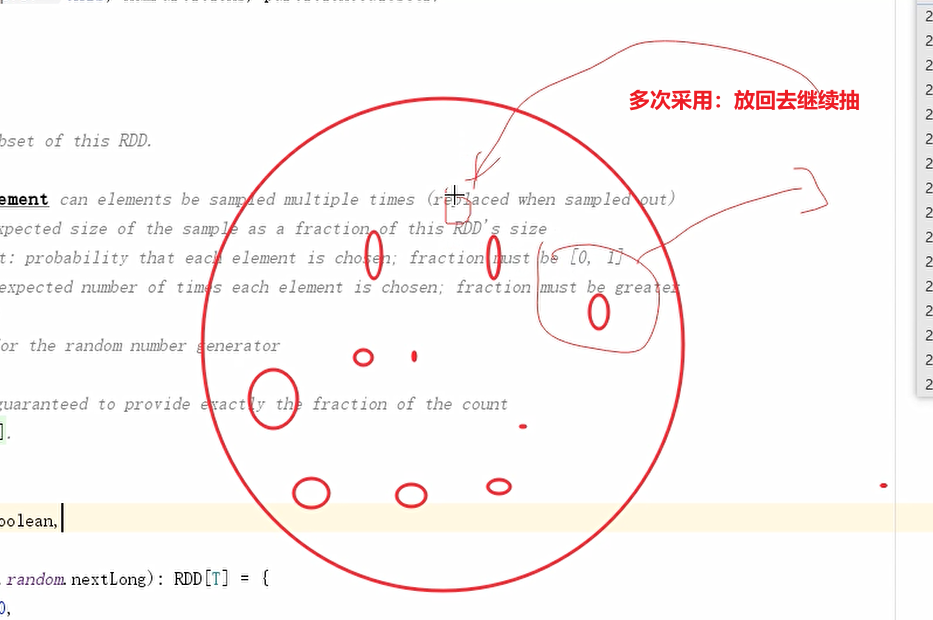
sample: 采样 【一般用于数据倾斜场景】
withReplacement: 同一个数据是否可以多次采样 [true代表同一个数据可能被采样多次, false代表同一个数据最多被采样一次] 【工作中一般设置为false,设置为ture判断不了是否产生数据倾斜】
fraction:
withReplacement=true, 此时fraction代表元素期望被采样的次数[>=0]
withReplacement=false,此时fraction每个元素被采样的概率[0,1] 【工作中一般设置为0.1/0.2】
/
@Testdef sample(): Unit ={val rdd = sc.parallelize(List(10,2,5,7,9,3,20,4,11,55,22,33,88,66))val rdd2 = rdd.sample(true,5)//println(rdd2.collect().toList)val rdd3 = rdd.sample(false,0.6)println(rdd3.collect().toList)}
distinct去重
/*
distinct: 去重
distinct有shuffle操作
*/
@Testdef distinct(): Unit ={val rdd = sc.parallelize(List(10,2,5,7,9,3,2,6,3,2))val rdd2 = rdd.distinct()println(rdd2.collect().toList)val rdd3 = mydistinct(rdd)println(rdd3.collect().toList)Thread.sleep(100000)}def mydistinct(rdd:RDD[Int]):RDD[Int] = {val rdd2 = rdd.groupBy(x=>x)rdd2.map(_._1)}
coalesce合并分区
/*
coalesce: 合并分区
coalesce默认情况下只能减少分区
coalesce如果想要增大分区,需要将shuffle参数设置为true
shuffle设置为true代表会产生shuffle操作
工作中一般搭配filter使用。
*/
减少分区不涉及shuffle操作,增大分区设计shuffle操作
原因 :shuffle定义:一个父RDD将数据传输给多个子RDD,而减少分区算法中只能是一个子RDD接收多个父RDD:
@Testdef coalesce(): Unit ={val rdd = sc.parallelize(List(10,2,5,7,9,3,2,6,3,2),5)println(new Random(hashing.byteswap32(0)).nextInt(5))rdd.mapPartitionsWithIndex((index,it)=>{println(s"rdd index:${index} datas:${it.toList}")it}).collect()println(rdd.partitions.length)val rdd2 = rdd.coalesce(3)rdd2.mapPartitionsWithIndex((index,it)=>{println(s"rdd2 index:${index} datas:${it.toList}")it}).collect()val rdd3 = rdd.coalesce(8,true)rdd3.mapPartitionsWithIndex((index,it)=>{println(s"rdd3 index:${index} datas:${it.toList}")it}).collect()println(rdd2.partitions.length)}
repartition重分区
/*
repartition: 重分区
repartition既可以增大分区也可以减少分区,都会产生shuffle
coleasce与repartition的区别:
coleasce默认只能减少分区,coaleasce的shuffle如果没有设置为true,是没有shuffle操作的
repartition既可以增大分区也可以减少分区,都会产生shuffle,底层就是使用的coaleasce
如果减少分区推荐使用coleasce,coleasce一般搭配filter使用
如果增大分区推荐使用repartition,因为简单
*/
@Testdef repartition(): Unit ={val rdd = sc.parallelize(List(10,2,5,7,9,3,2,6,3,2),5)val rdd2 = rdd.repartition(3)println(rdd2.partitions.length)}
sortBy
/*
sortBy(func: RDD元素类型=>K,ascding=ture ): 根据指定字段排序
sortBy后续是根据函数的返回值进行排序
sortBy里面的函数是针对集合每个元素进行操作
sortBy有shuffle操作
/
@Testdef sortBy(): Unit ={val rdd = sc.parallelize(List(10,2,5,7,9,3,2,6,3,2),5)val rdd2 = rdd.sortBy(x=>x,false)rdd2.mapPartitionsWithIndex((index,it)=>{println(s"index:${index} data:${it.toList}")it}).collect()println(rdd2.collect().toList)}
pipe
/*
pipe: 调用指定的脚本
pipe生成的新RDD的元素是由脚本中通过echo返回的
pipe在调用脚本的时候是每个分区调用一次
*/
@Testdef pipe(): Unit ={val rdd = sc.parallelize(List(10,2,5,7,9,3,2,6,3,2),5)}

若有收获,就点个赞吧
0 人点赞
