

详情打开idea的:
FlinkDemoTcode工程
C:\Users\ldc\IdeaProjects\FlinkDemoTcode
Environment
Source
File
Collection 集合
Kafka 从kafka获取数据,重点!
Custom 自定义
Transform
Map
Map_Rich
涉及到外界连接(即状态)的需要用到richMap函数
节省频繁连接带来的开销
FlatMap
有map和filter的功能 ,用collect.out方法写出
Filter
KeyBy
根据键分组
同一个分组的数据,会进入同一个分区
同一个分区内可以有多个分组
两次hash:
第一次 key本身的hashcode方法 hash1
第二次 murmur (hash1) hash2
这样设计的原因是为了适应并行度比分组数小的情况
例如并行度为1的时候有两组,这样不得不将两组的数据都放到一个并行度中
Shuffle
Connect
connect普通流:
两个流 只能合并,不能融合,类似于join
两个连在一起之后, 使用算子处理的时候, 内部还是各自处理各自的
这个两个的数据类型可以不一致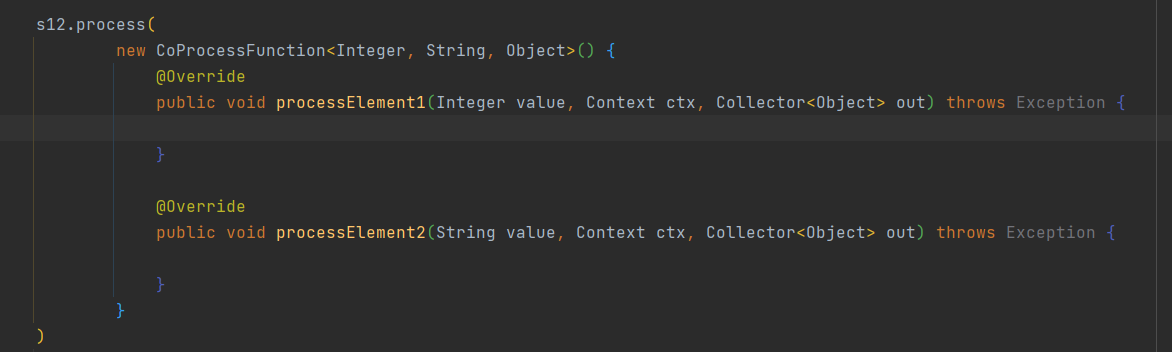
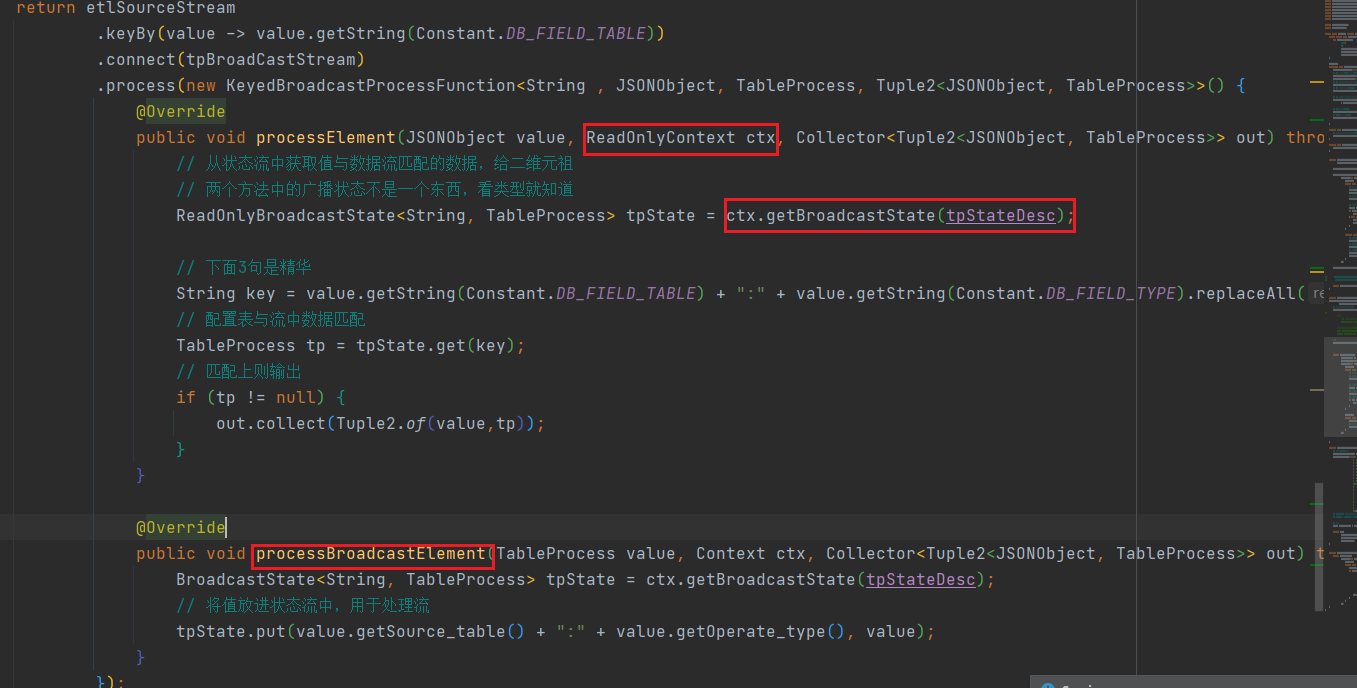
connect广播流:
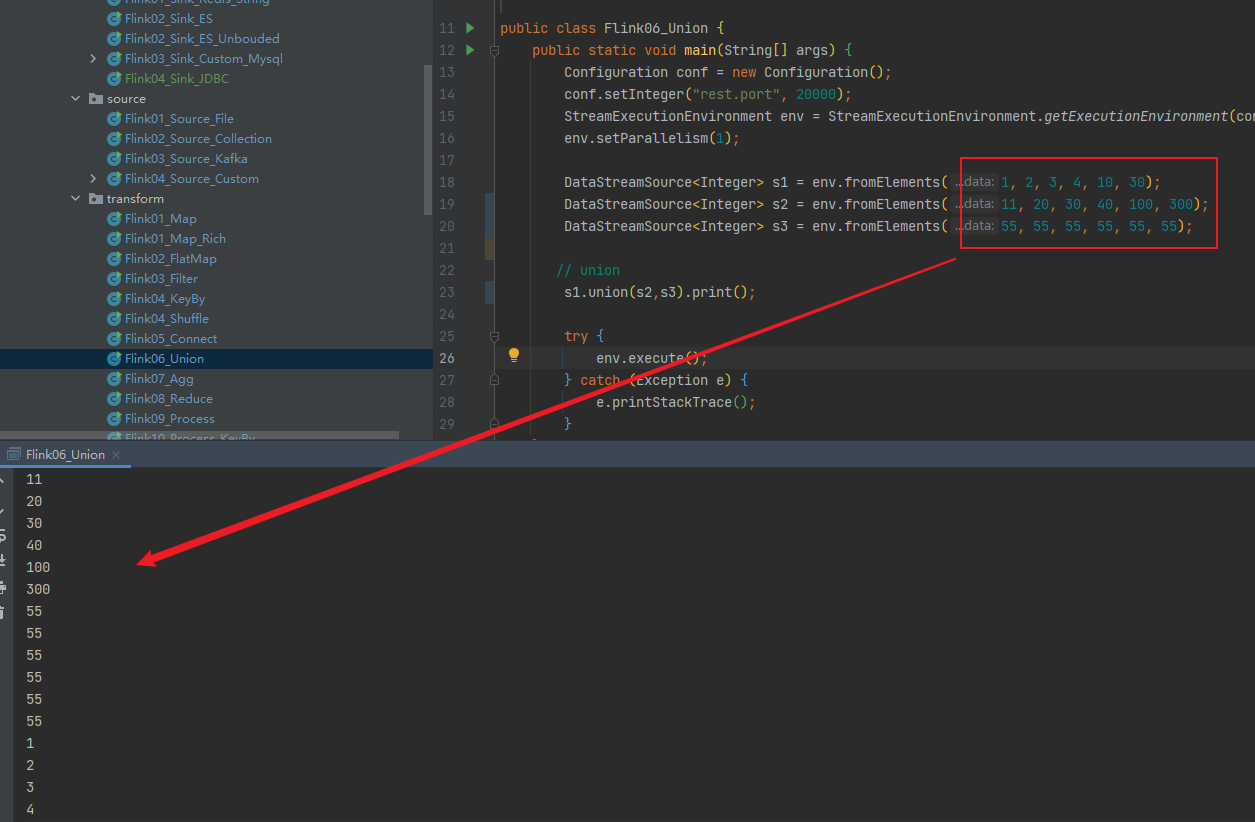
Union
一个流 可以融合,数据类型必须一致,类似于union
Agg
sum、max、min等聚合算子,需要紧跟keyby后面
sum, max, min(这里面使用了状态)
非聚合和分组字段默认选的是碰到的第一个值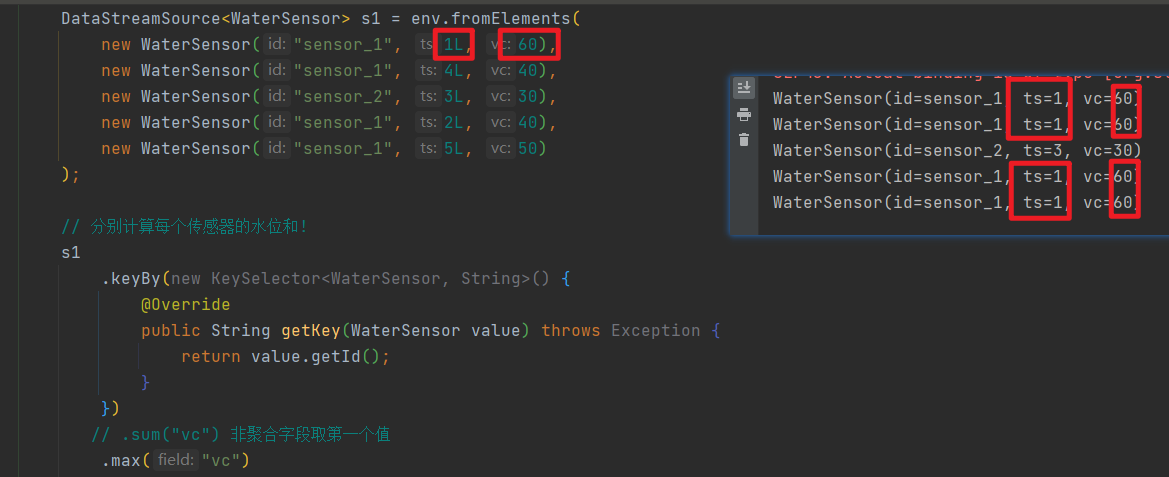
maxBy, minBy
非聚合和分组字段 是最终最大值或最小值
默认情况: 如果最大值相等, 其他字段取第一个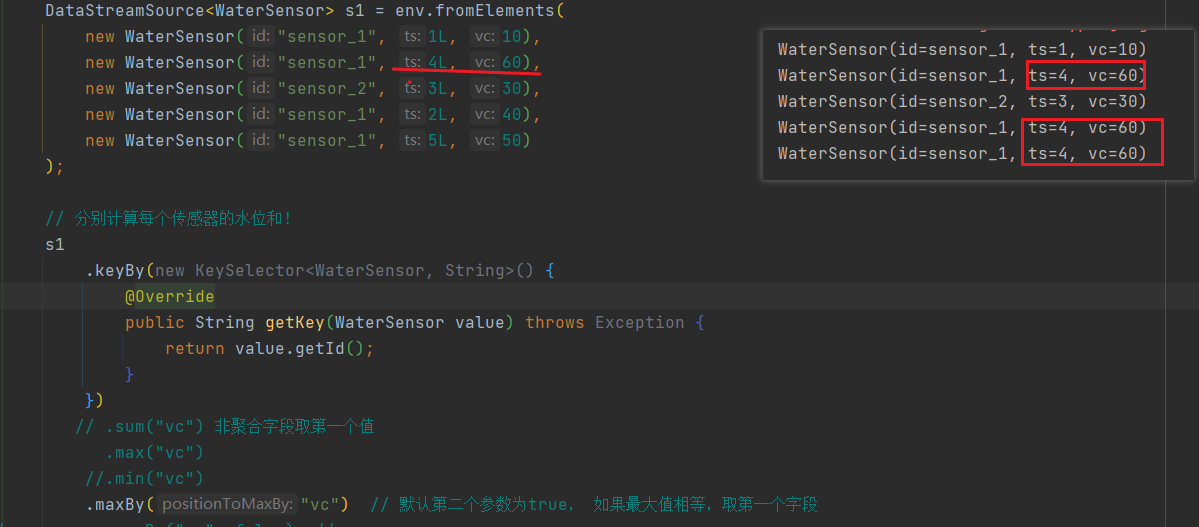
Reduce
可以代替agg,比agg更灵活
1. 聚合结果的类型与输入类型保持一致
2. 如果某个key的第一个元素来的时候, 不会触发reduce函数
Process
new:注意!算子中重写的方法会因为多条数据而被调用多次,但是,算子中的匿名内部类的成员变量只会执行一次!!所有算子都是!!
process可以替换除了keyby以外的所有算子
process算子效率低,吃内存,不用为好
Process_KeyBy
new:注意!算子中重写的方法会因为多条数据而被调用多次,但是,算子中的匿名内部类的成员变量只会执行一次!!所有算子都是!!
使用map来处理并行度不一致问题
通过map的去重功能来管理sum的状态,
到map中寻找key,如果key存在则返回对应值,如果key不存在,则返回0,
然后将map中获取的值与传进来的值相加,相加后再put进去,以保证数据的隔离性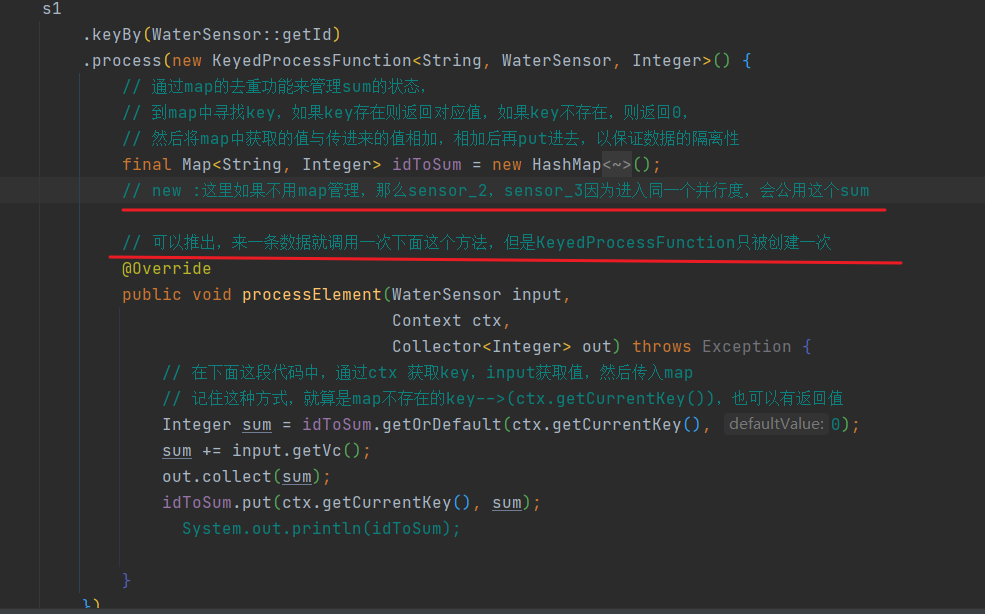
Rebalance,rescale
以轮询的方式平均分配分区,用以处理数据倾斜
rebalance可能跨节点,而rescale不会夸节点没有产生网络传输效率更高,但不是真正意义上的均分
每次结果一致
Sink
Kafka
Kafka_1
Redis_Hash
Redis_list
Redis_Set
Redis_String
ES
ES_Unbouded
Custom_Mysql
MysqlSink
JDBC
mode
Flink02_Stream_Bounded_WC
项目
Flink01_Project_PV
Flink01_Project_PV_2
Flink02_Project_UV
Flink03_Project_AppStats
MarketSource
Flink04_Project_Order
processFunction API
7.6.1 ProcessFunction

7.6.2 KeyedProcessFunction
7.6.3 CoProcessFunction(connect)
7.6.4 ProcessJoinFunction

7.6.5 BroadcastProcessFunction
7.6.6 KeyedBroadcastProcessFunction
7.6.7 ProcessWindowFunction
7.6.8 ProcessAllWindowFunction
全窗口函数之后使用

若有收获,就点个赞吧
0 人点赞
