介绍
Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
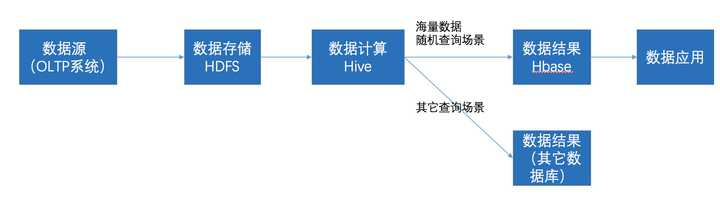
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
- 数据应用从HBase查询数据;
总结:
Hbase相当于hadoop的mysql数据库,用于实时查询(即席查询),不适合做join,表关系复杂的运算
而hive则相反适用于做复杂的逻辑计算(mr、spark、tez),可以选择把计算结果交给hbase去展示
同时,mr、spark、tez等引擎都是计算引擎,
mr纯落盘(有shuffler的计算),适用于年指标的
spark 基于内存,内存不足落盘,适用于月指标的计算,计算量大其实和mr没差多少
tez同理
概述
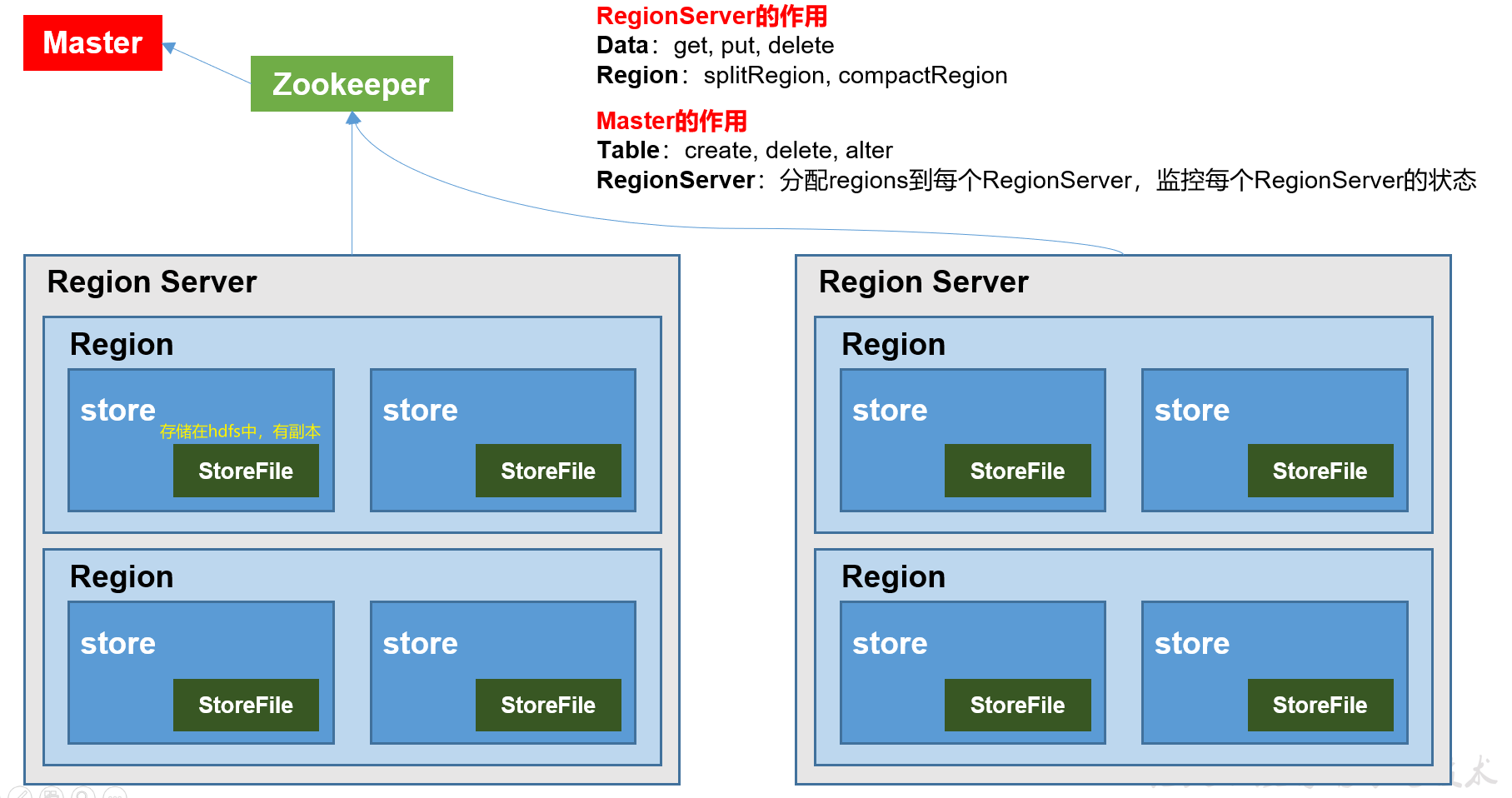
逻辑存储结构
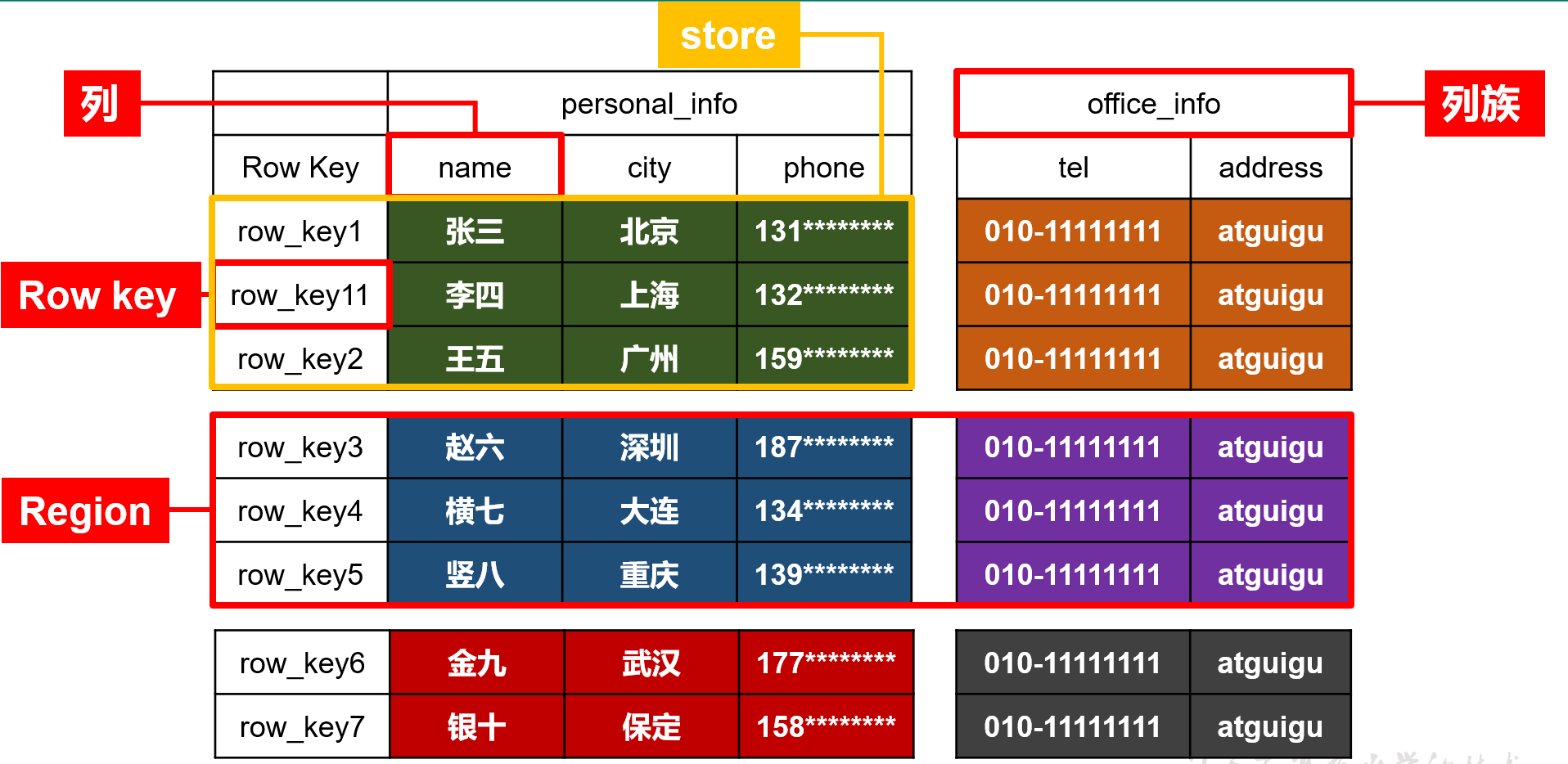
| rowkey(r) | ·每行的唯一标识,类似于主键 | |
|---|---|---|
| region | rowkey字典序之后,hbase会切分为多个region,每个region都会有startkey,endkey,按region分文件,加快查询效率: 如:一个分区有:startkey=1,endkey=4,那么rowkey=32,就在这个region中 |
region思想: mysql中: 分库:减轻库压力 分表:加快表查询速率 横向切分 纵向切分 hbase中:通过region进行分表,加快查询速度 hive:类似于分区,也是一个region一个文件夹 |
| store | store=column_family,按列簇再次分文件,加快查询效率 | 类似于hive 在region文件夹下有多个store文件夹(文件夹名是列簇名,store文件夹下有多个溢写文件) 与hive不同的是hive一个region分区文件夹下直接是文件组成不同的桶,而region则是一个文件夹下有个store,里面再有不同的桶 |
| column(c=f:q) | HBase中的每个列都由Column Family(列族)和Column Qualifier(列限定符)进行限定,例如info:name、info:age。这里info是列族,name和age是列限定符。 建表时,只需指明列族,而列限定符无需预先定义,格式:f1:q1 |
|
| row | 逻辑结构的一行等于物理结构的多行 | |
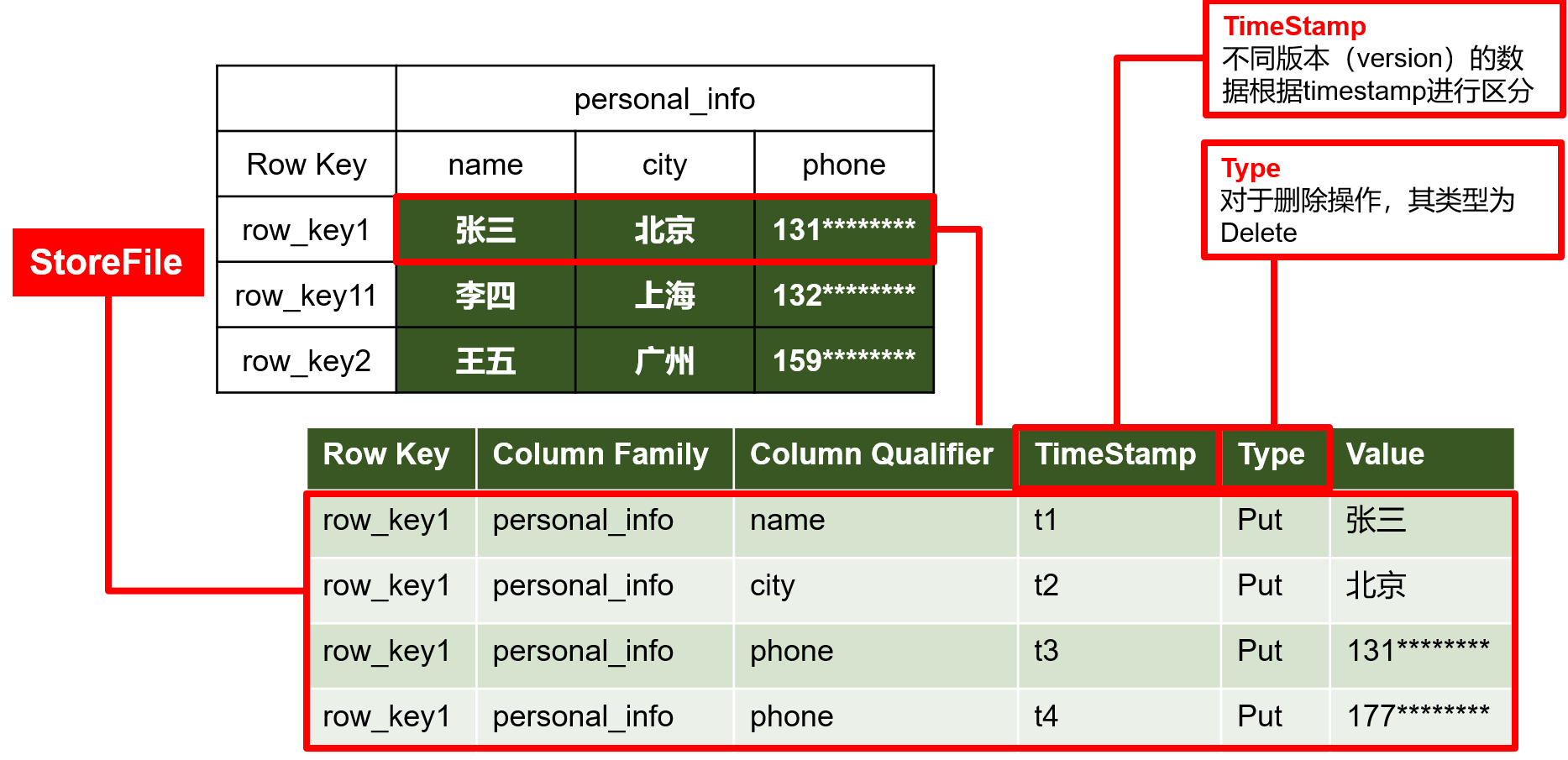
| Time Stamp | 用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入HBase的时间 | |
| Cell | 由{rowkey,column Family:column Qualifier, time Stamp} 唯一确定的单元。 cell中的数据是没有类型的,全部是字节码形式存储。 |
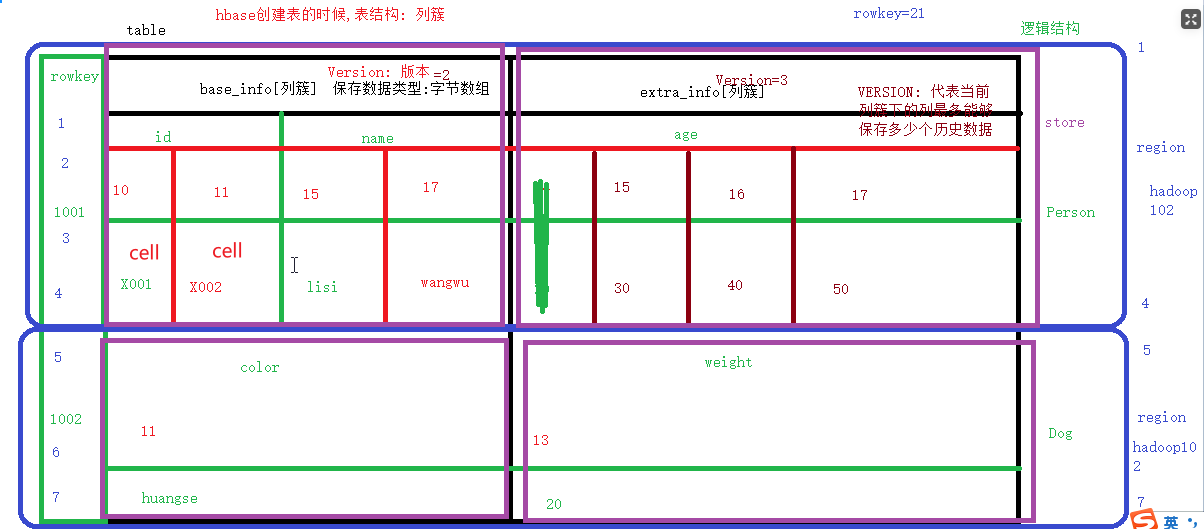
物力存储结构
Hbase分布式结构(不完整版)
HFile
https://www.cnblogs.com/yangjiming/p/9429169.html
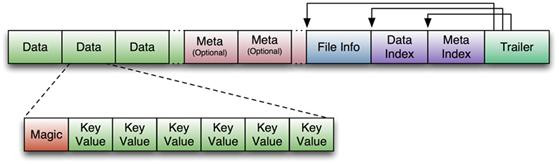
HFile
HBase中KeyValue数据的存储格式,是hadoop的二进制格式文件。
首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。Trailer中又指针指向其他数据块的起始点,FileInfo记录了文件的一些meta信息。
Data Block是hbase io的基本单元,为了提高效率,HRegionServer中又基于LRU的block cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定(默认块大小64KB),大号的Block有利于顺序Scan,小号的Block利于随机查询。每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成,Magic内容就是一些随机数字,目的是烦着数据损坏,结构如下。

HFile结构图如下:

若有收获,就点个赞吧
0 人点赞
