读数据流程

第一个块读完,再读第二个块
读数据流程:1.创建文件对象
2.利用文件对象创建输入流
3.关闭资源
public class HDFSClient {FileSystem fs = null;@Beforepublic void before() throws URISyntaxException, IOException, InterruptedException {//创建连接对象Configuration configuration = new Configuration();configuration.set("dfs.replication","2");fs = FileSystem.get(new URI("hdfs://hadoop102:9820"),configuration,"atguigu");}@Afterpublic void after() throws IOException {//关闭资源if (fs != null) {fs.close();}}// io流方式://读入@Testpublic void downloadIO() throws IOException {FileOutputStream fos = new FileOutputStream("C:\\ldc_zoom\\ShangBigDatas\\03-BigData\\04-hadoop\\04-hadoop\\4.视频\\尚硅谷大数据技术之Hadoop(入门)V3.0.docx");FSDataInputStream fis = fs.open(new Path("\\nothappy\\尚硅谷大数据技术之Hadoop(入门)V3.0.docx"));IOUtils.copyBytes(fis,fos,1024,true);}
写数据流程
写入流程
记忆:
写要对接nm和dn都要应答,读则都不需要
写因为可以一股脑写,所以简历传输通道即可,读则因为要找到每个节点,分别读入,所以不能建立通道。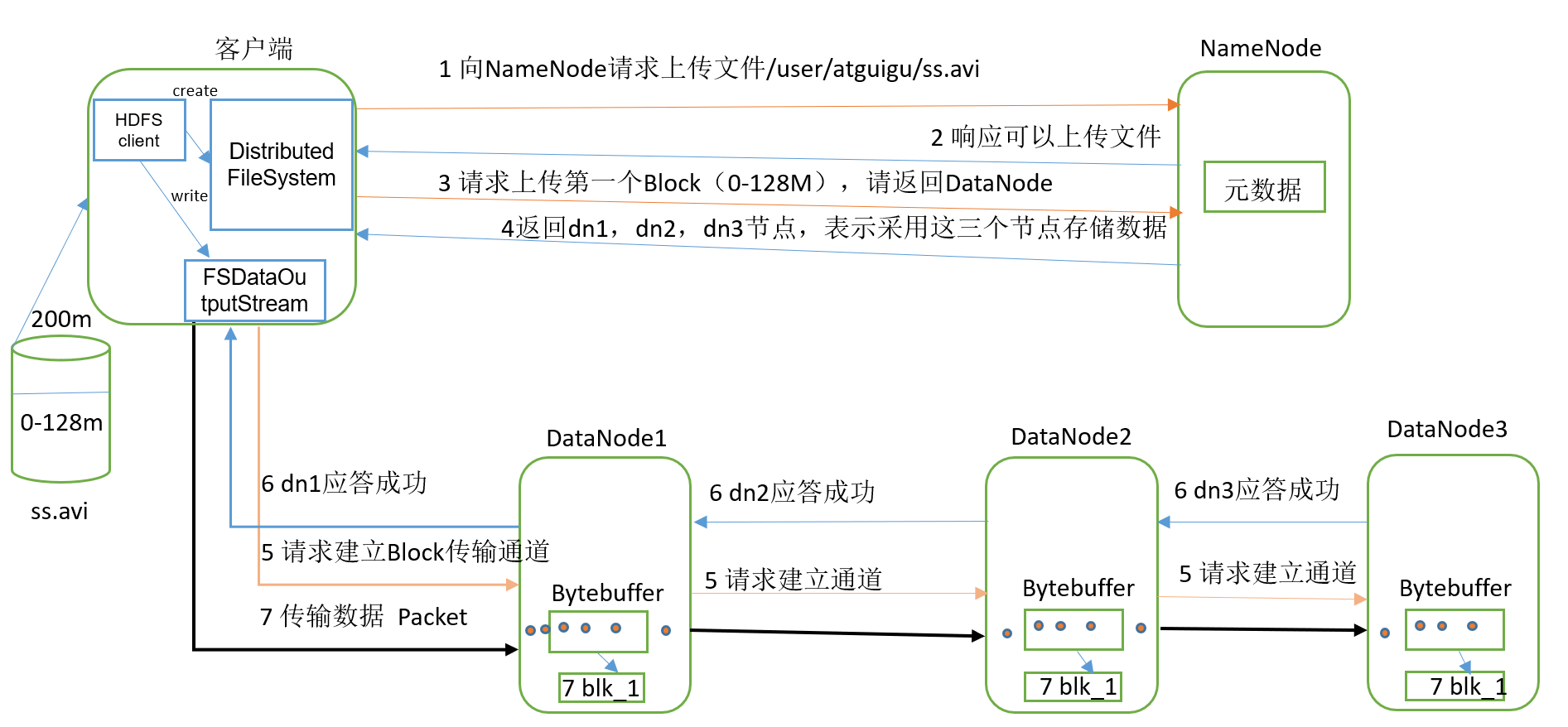
(1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(2)NameNode返回是否可以上传。
(3)客户端请求第一个Block上传到哪几个DataNode服务器上。
(4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
(5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3逐级应答客户端。
(7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。(三个副本)
(8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
@Testpublic void uploadIO() throws IOException {//创建数据输入流,请求读入数据FileInputStream fis = new FileInputStream("C:\\Users\\ldc\\AppData\\Roaming\\feiq\\Recv Files\\尚硅谷大数据技术之Hadoop(入门)V3.0.docx");//create方法创建生成并返回一个文件系统数据输出流FSDataOutputStream fos = fs.create(new Path("\\nothappy\\尚硅谷大数据技术之Hadoop(入门)V3.0.docx"));//引入io流工具类IOUtils.copyBytes(fis,fos,1024,true);}
BLOCK的大小
前提
寻址时间太长
处理快时间太长
都不好,二者之间比例为1%最好
说明:
- 寻址一个文件所花费的时间一般10ms是比较适合
- 而寻址时间是存储时间的1%的时候是比较好的
- 由上面两点可以计算出存储时间是1s时是最好的
- 又因为现在磁盘的读入速度是100M/s
- 因而我们取100m左右的大小作为block的阈值
—>
最后官方是取了128M来作为默认block的阈值
—>
如果磁盘读入速度升级到200M/s,那么我们也可以在配置文件中配置256M的block阈值
datanode的选择
在HDFS写数据的过程中,NameNode会选择距离待上传数据(客户端)最近距离的DataNode接收数据。
配合副本选择机制进行选择
最小距离计算: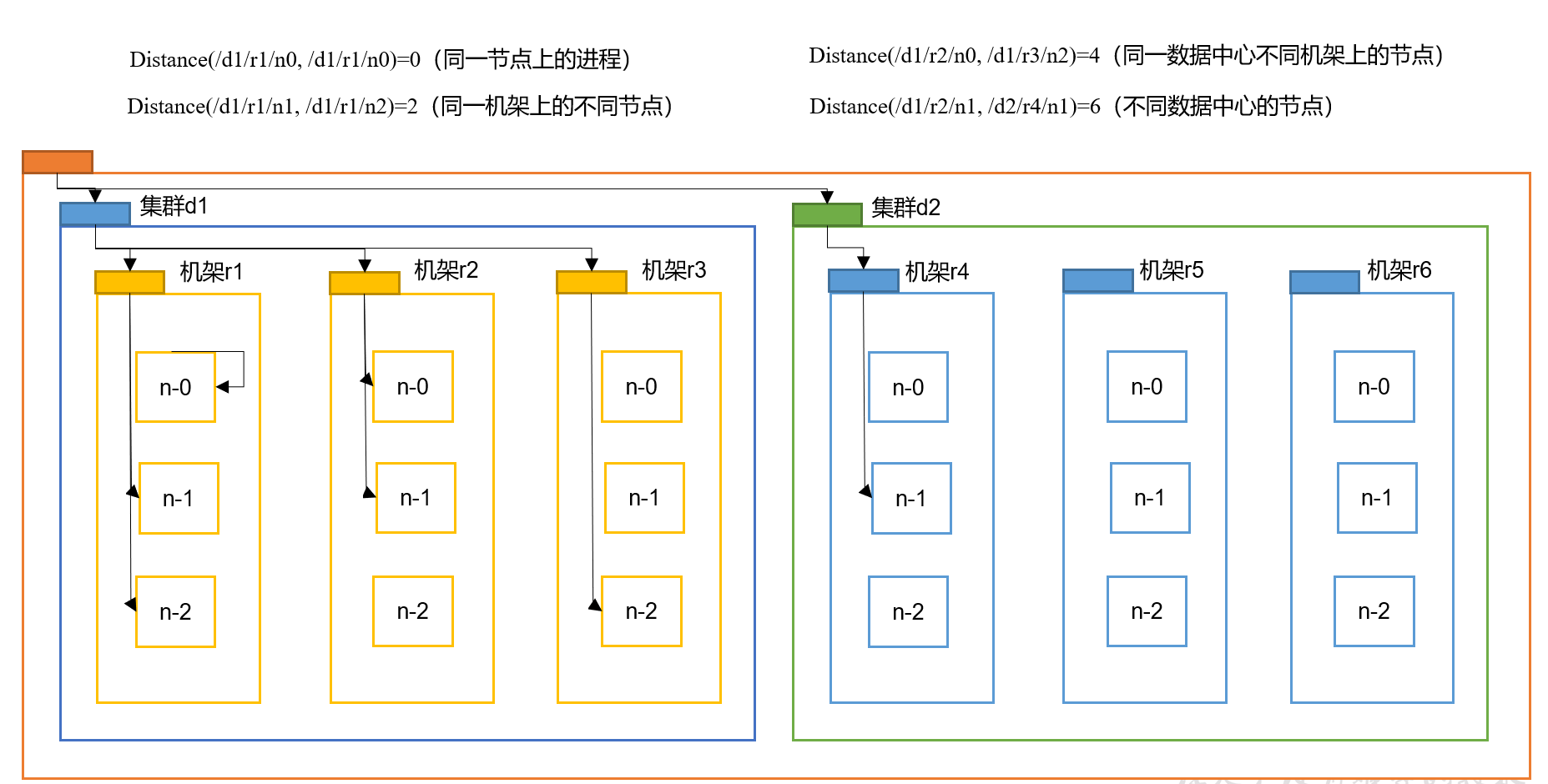
副本节点选择
(副本的选择是在不同机器上才有意义,以下是有机架的情况:)
说明:
第一个副本:
如果client在节点上那么第一个副本在此节点上
如果client在集群外,那么第一个副本随机选择
第二个副本:
选择在第一个副本以外的随机机架上,以保证安全性(2.x版本是放在同一机架上)
第三个副本:
选择在第二个副本所在的机架上,以保证效率
第四个副本以后:
随机选择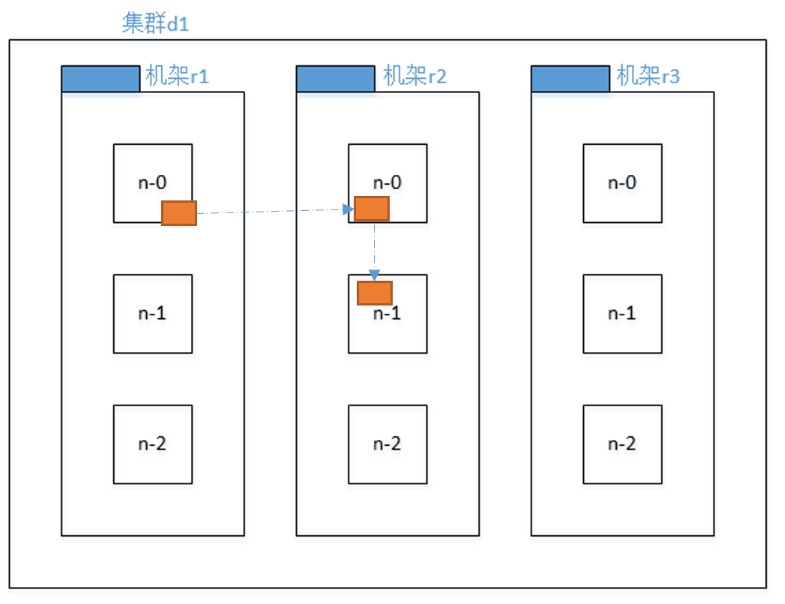

若有收获,就点个赞吧
0 人点赞
