
具体请移步官网
https://azkaban.readthedocs.io/en/latest/createFlows.html
基础案例
Creating Flows
This section covers how to create your Azkaban flows using Azkaban Flow 2.0. Flow 1.0 will be deprecated in the future.
Flow 2.0 Basics
Step 1:
Create a simple file called flow20.project. Add azkaban-flow-version to indicate this is a Flow 2.0 Azkaban project:
azkaban-flow-version: 2.0Step 2:
Create another file called basic.flow. Add a section called nodes, which will contain all the jobs you want to run. You need to specify name and type for all the jobs. Most jobs will require the config section as well. We will talk more about it later. Below is a simple example of a command job.
nodes:
- name: jobA
type: command
config:
command: echo “This is an echoed text.”Step 3:
Select the two files you’ve already created and right click to compress them into a zip file calledArchive.zip. You can also create a new directory with these two files and thencdinto the new directory and compress:zip -r Archive.zip .Please do not zip the new directory directly.
Make sure you have already created a project on Azkaban ( See Create Projects ). You can then upload Archive.zip to your project through Web UI ( See Upload Projects ).
Now you can clickExecute Flowto test your first Flow 2.0 Azkaban project!Job Dependencies
Jobs can have dependencies on each other. You can usedependsOnsection to list all the parent jobs. In the below example, after jobA and jobB run successfully, jobC will start to run. nodes: name: jobC type: noop
jobC depends on jobA and jobB
dependsOn:
- jobA
- jobB
name: jobA type: command config: command: echo “This is an echoed text.”
name: jobB type: command config: command: pwdYou can zip the new
basic.flowandflow20.projectagain and then upload it to Azkaban. Try to execute the flow and see the difference.Job Config
Azkaban supports many job types. You just need to specify it in
type, and other job-related info goes toconfigsection in the format ofkey: valuepairs. Here is an example of a Pig job: nodes:- name: pigJob
type: pig
config:
pig.script: sql/pig/script.pigYou need to write your own pig script and put it in your project zip and then specify the path for the pig.script in the config section.
Flow Config
Not only can you configure individual jobs, but you can also config the flow parameters for the entire flow. Simply add aconfigsection at the beginning of thebasic.flowfile. For example:
config: user.to.proxy: foo failure.emails: noreply@foo.com
nodes:
- name: jobA
type: command
config:
command: echo “This is an echoed text.”When you execute the flow, the
user.to.proxyandfailure.emailsflow parameters will apply to all jobs inside the flow.Embedded Flows
Flows can have subflows inside the flow just like job nodes. To create embedded flows, specify the type of the node asflow. For example: nodes: name: embedded_flow type: flow config: prop: value nodes:
- basicFlow20Project.zip
- embeddedFlow20Project.zip
JavaProcess案例
JavaProcess类型可以运行一个自定义主类方法,type类型为javaprocess,可用的配置为:
Xms:最小堆
Xmx:最大堆
java.class:要运行的Java对象,其中必须包含Main方法
案例:
1)新建一个azkaban的maven工程
2)创建包名:com.atguigu
3)创建AzTest类
/
package com.atguigu;public class AzTest {public static void main(String[] args) {System.out.println("This is for testing!");}}
4)打包成jar包azkaban-1.0-SNAPSHOT.jar
5)新建testJava.flow,内容如下
| nodes: - name: test_java type: javaprocess config: Xms: 96M Xmx: 200M java.class: com.atguigu.AzTest |
|---|
6)将Jar包、flow文件和project文件打包成javatest.zip
7)创建项目=》上传javatest.zip =》执行作业=》观察结果
执行脚本案例
azkaban调度脚本时:
①执行权限
②executor Server找到脚步
配置到PATH ,直接调用脚本
或
绝对路径
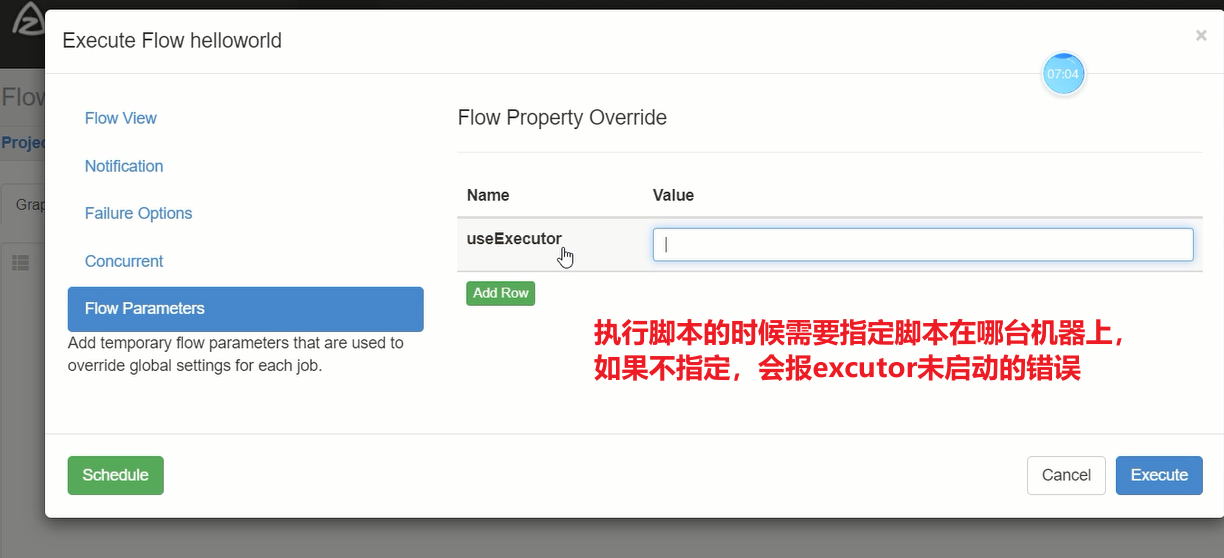
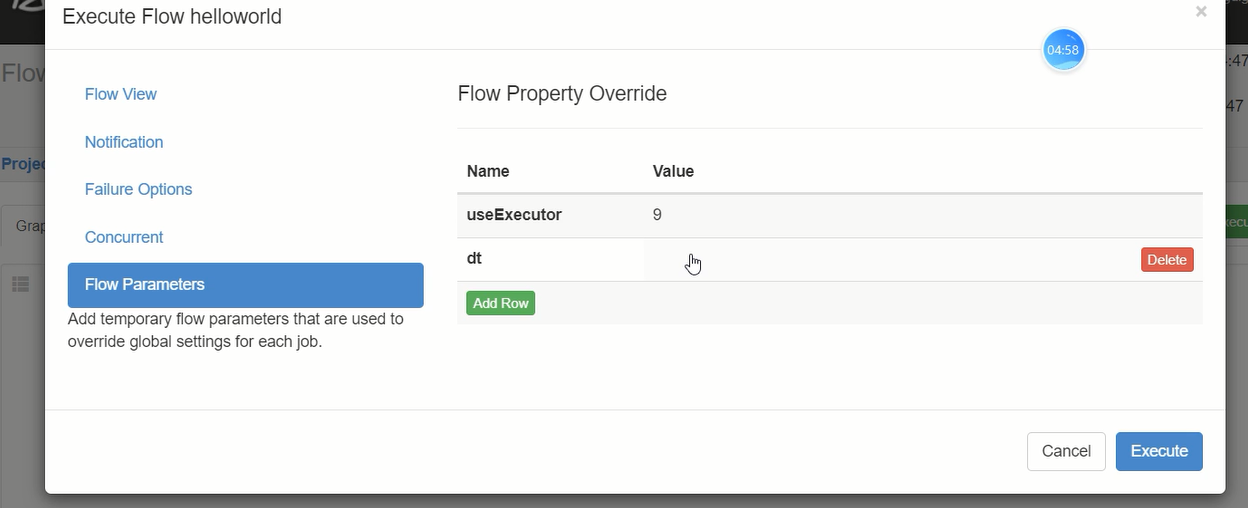
③如果脚步在特定的机器,需要指定特定机器的executor,使用 useExecutor=executorID
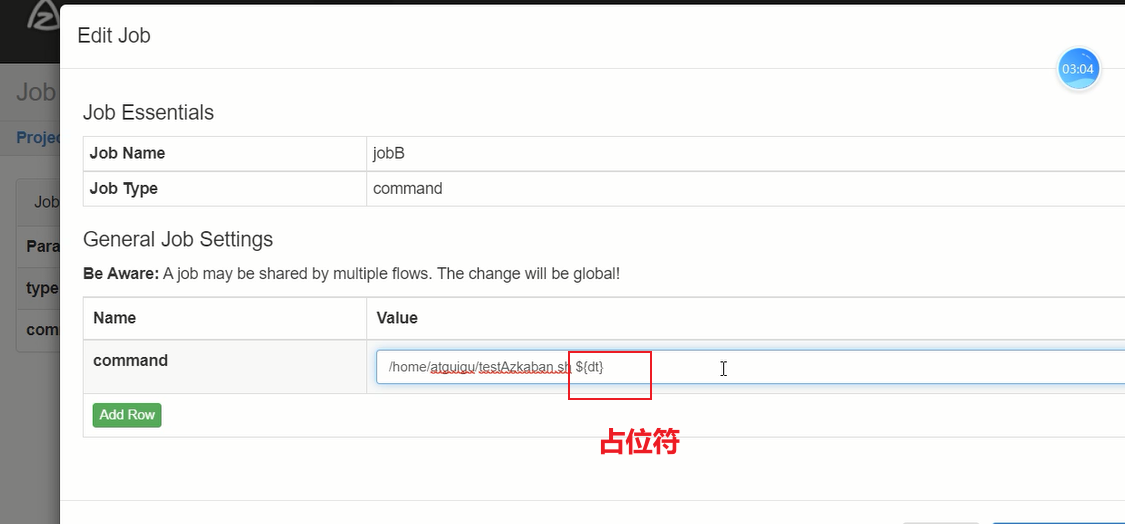
④在执行脚本时,如果希望传入参数,可以在命令后,使用${参数名},设置占位符,如果设置了占位符,必须需要传入参数,如果无需传参,只能使用传入空参数的方式。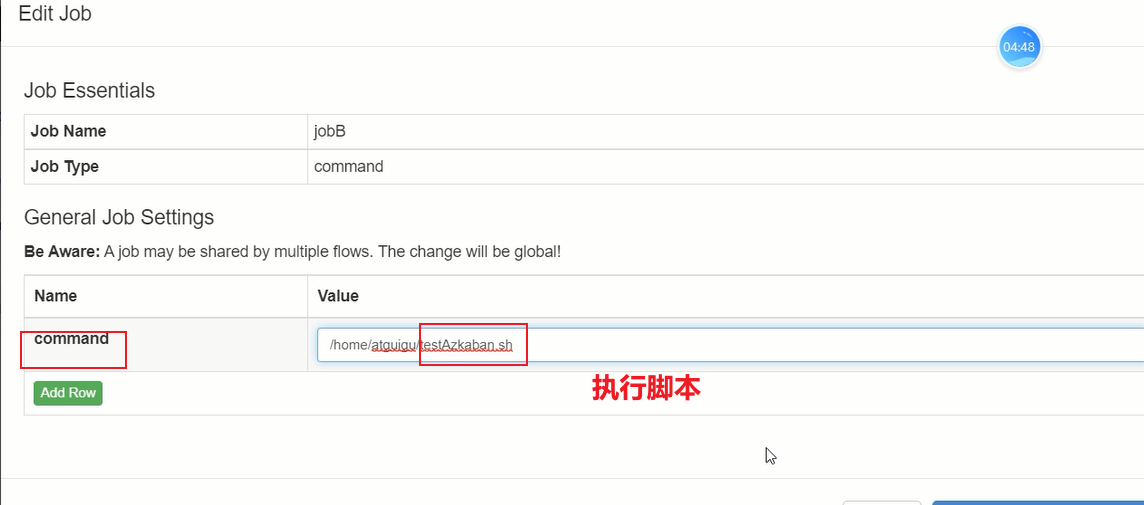
制作脚本时:
①如果使用了SFTP工具,注意字符集,选择UTF-8无BOM
②将sql中 ` 全部删除
③将 str_to_map, split等函数中,分隔符为 \ \ 的,转换为 \ \ \
不指定可能会报错:
process has not yet started
两种可能:
1、执行的脚本不在指定机器
2、资源不足
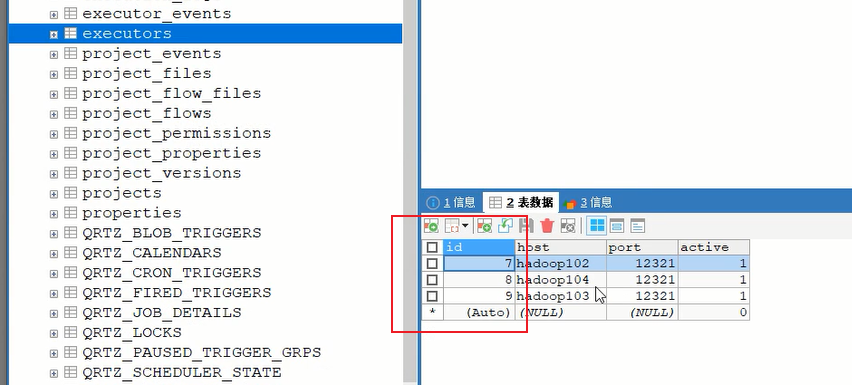
mysql 查机器id
脚本传参

自动失败重试案例
需求:如果执行任务失败,需要重试3次,重试的时间间隔10000ms
具体步骤:
1)编译配置流
| nodes: - name: JobA type: command config: command: touch /etc/a(不能在etc常见文件,会报错) retries: 3 retry.backoff: 10000 |
|---|
参数说明:
retries:重试次数
retry.backoff:重试的时间间隔
2)执行并观察到一次失败+三次重试
3)也可以点击上图中的Log,在任务日志中看到,总共执行了4次。
4)也可以在Flow全局配置中添加任务失败重试配置,此时重试配置会应用到所有Job。
案例如下:
| config: retries: 3 retry.backoff: 10000 nodes: - name: JobA type: command config: command: sh /not_exists.sh |
|---|
定时执行案例
需求:JobA每间隔1分钟执行一次;
具体步骤:
1)Azkaban可以定时执行工作流。在执行工作流时候,选择左下角Schedule
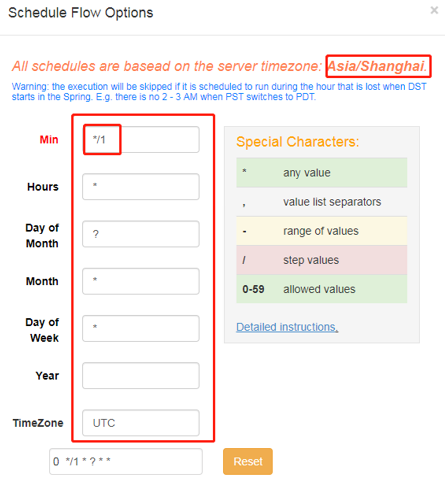
2)右上角注意时区是上海,然后在左面填写具体执行事件,填写的方法和crontab配置定时任务规则一致。

3)观察结果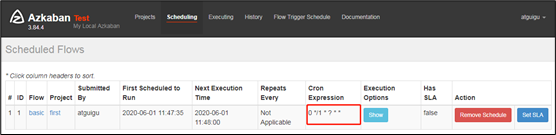
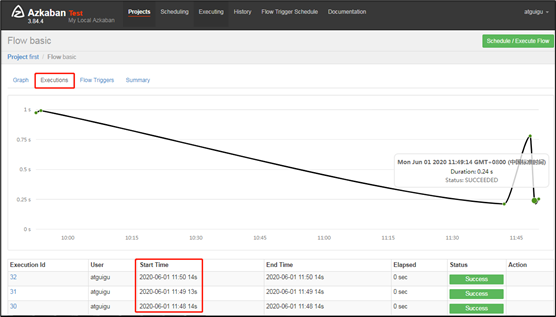
4)删除定时调度
点击remove Schedule即可删除当前任务的调度规则。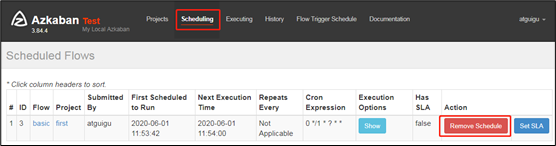
邮件报警案例
注册邮箱
3)开启SMTP服务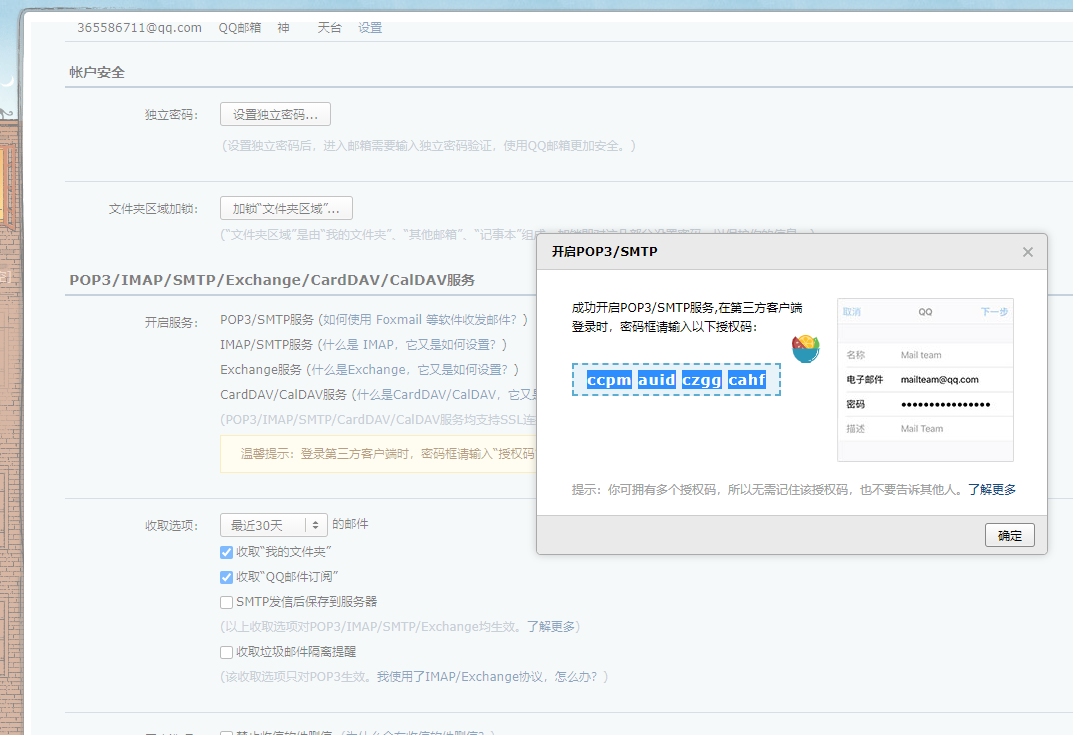
4)一定要记住授权码**ccpm**``**auid**``**czgg**``**cahf**
默认邮件报警案例
Azkaban默认支持通过邮件对失败的任务进行报警,配置方法如下:
1)在azkaban-web节点hadoop102上,编辑/opt/module/azkaban/azkaban-web/conf/azkaban.properties,修改如下内容:
[atguigu@hadoop102 azkaban-web]$ vim /opt/module/azkaban/azkaban-web/conf/azkaban.properties
添加如下内容:
#这里设置邮件发送服务器,需要 申请邮箱,且开通stmp服务,以下只是例子
| mail.sender=atguigu@126.com mail.host=smtp.126.com mail.user=atguigu@126.com mail.password=用邮箱的授权码 |
|---|
2)保存并重启web-server。
/
[atguigu@hadoop102 azkaban-web]$ bin/shutdown-web.sh[atguigu@hadoop102 azkaban-web]$ bin/start-web.sh
3)发送方法: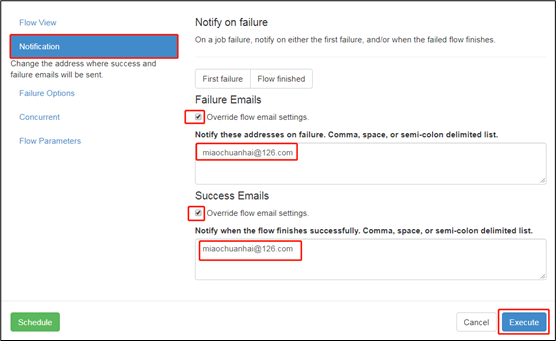
也可以:
| config: failure.emails: atguigutest@163.com success.emails: atguigutest@163.com nodes: - name: jobA type: command config: command: mkdir /etc/A |
|---|
6)观察邮箱,发现执行成功或者失败的邮件

若有收获,就点个赞吧
0 人点赞
