Standalone模式
Standalone模式是Spark自带的资源调动引擎,构建一个由Master + Slave构成的Spark集群,Spark运行在集群中。
这个要和Hadoop中的Standalone区别开来。这里的Standalone是指只用Spark来搭建一个集群,不需要借助Hadoop的Yarn和Mesos等其他框架。
安装使用
1)集群规划
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| Spark | Master Worker |
Worker | Worker |
2)再解压一份Spark安装包,并修改解压后的文件夹名称为spark-standalone
[atguigu@hadoop102 sorfware]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/[atguigu@hadoop102 module]$ mv spark-3.0.0-bin-hadoop3.2 spark-standalone
3)进入Spark的配置目录/opt/module/spark-standalone/conf
[atguigu@hadoop102 spark-standalone]$ cd conf
4)修改slave文件,添加work节点:
[atguigu@hadoop102 conf]$ mv slaves.template slaves[atguigu@hadoop102 conf]$ vim slaves
hadoop102
hadoop103
hadoop104
5)修改spark-env.sh文件,添加master节点
[atguigu@hadoop102 conf]$ mv spark-env.sh.template spark-env.sh[atguigu@hadoop102 conf]$ vim spark-env.sh
SPARK_MASTER_HOST=hadoop102
SPARK_MASTER_PORT=7077
6)分发spark-standalone包
[atguigu@hadoop102 module]$ xsync spark-standalone/
7)启动spark集群
[atguigu@hadoop102 spark-standalone]$ sbin/start-all.sh
查看三台服务器运行进程(xcall.sh是以前数仓项目里面讲的脚本)
[atguigu@hadoop102 spark-standalone]$ xcall.sh jps
================atguigu@hadoop102================
3330 Jps
3238 Worker
3163 Master
================atguigu@hadoop103================
2966 Jps
2908 Worker
================atguigu@hadoop104================
2978 Worker
3036 Jps
注意:如果遇到 “JAVA_HOME not set” 异常,可以在sbin目录下的spark-config.sh 文件中加入如下配置:
export JAVA_HOME=XXXX
8)网页查看:hadoop102:8080(master web的端口,相当于hadoop的8088端口)
目前还看不到任何任务的执行信息。
9)官方求PI案例
[atguigu@hadoop102 spark-standalone]$ bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://hadoop102:7077 \./examples/jars/spark-examples_2.12-3.0.0.jar \10
参数:—master spark://hadoop102:7077指定要连接的集群的master
10)页面查看http://hadoop102:8080/,发现执行本次任务,默认采用三台服务器节点的总核数24核,每个节点内存1024M。
8080:master的webUI
4040:application的webUI的端口号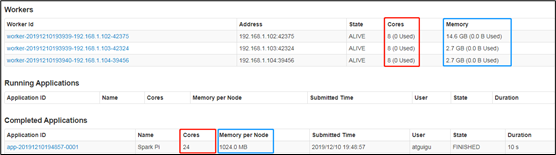
参数说明
1)配置Executor可用内存为2G,使用CPU核数为2个
[atguigu@hadoop102 spark-standalone]$ bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://hadoop102:7077 \--executor-memory 2G \--total-executor-cores 2 \./examples/jars/spark-examples_2.12-3.0.0.jar \10
2)页面查看http://hadoop102:8080/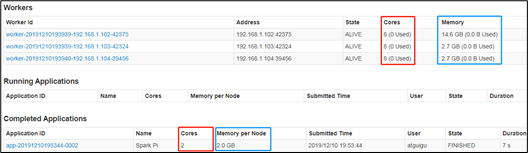
3)基本语法
bin/spark-submit \--class <main-class>--master <master-url> \... # other options<application-jar> \[application-arguments]
/
4)参数说明
| 参数 | 解释 | 可选值举例 |
|---|---|---|
| —class | Spark程序中包含主函数的类 | |
| —master | Spark程序运行的模式 | 本地模式:local[*]、spark://hadoop102:7077、 Yarn |
| —executor-memory 1G | 指定每个executor可用内存为1G | 符合集群内存配置即可,具体情况具体分析。 |
| —total-executor-cores 2 | 指定所有executor使用的cpu核数为2个 | |
| application-jar | 打包好的应用jar,包含依赖。这个URL在集群中全局可见。 比如hdfs:// 共享存储系统,如果是file:// path,那么所有的节点的path都包含同样的jar | |
| application-arguments | 传给main()方法的参数 |
配置历史服务
由于spark-shell停止掉后,hadoop102:4040页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况。
1)修改spark-default.conf.template名称
[atguigu@hadoop102 conf]$ mv spark-defaults.conf.template spark-defaults.conf
2)修改spark-default.conf文件,配置日志存储路径(写),并分发
[atguigu@hadoop102 conf]$ vi spark-defaults.confspark.eventLog.enabled truespark.eventLog.dir hdfs://hadoop102:8020/directory[atguigu@hadoop102 conf]$ xsync spark-defaults.conf
注意:需要启动Hadoop集群,HDFS上的目录需要提前存在。
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /directory
3)修改spark-env.sh文件,添加如下配置:
[atguigu@hadoop102 conf]$ vi spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory-Dspark.history.retainedApplications=30"
参数1含义:WEBUI访问的端口号为18080
# 参数2含义:指定历史服务器日志存储路径(读)
# 参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
4)分发配置文件
[atguigu@hadoop102 conf]$ xsync spark-env.sh
5)启动历史服务
[atguigu@hadoop102 spark-standalone]$sbin/start-history-server.sh
6)再次执行任务
[atguigu@hadoop102 spark-standalone]$ bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://hadoop102:7077 \--executor-memory 1G \--total-executor-cores 2 \./examples/jars/spark-examples_2.12-3.0.0.jar \10
7)查看Spark历史服务地址:hadoop102:18080
配置高可用(HA)
1)高可用原理:
hadoop103一直监控着在zookeeper中注册的hadoop102的临时目录,hadoop102宕机,临时目录中的hadoop102信息消失,hadoop103更变为active状态。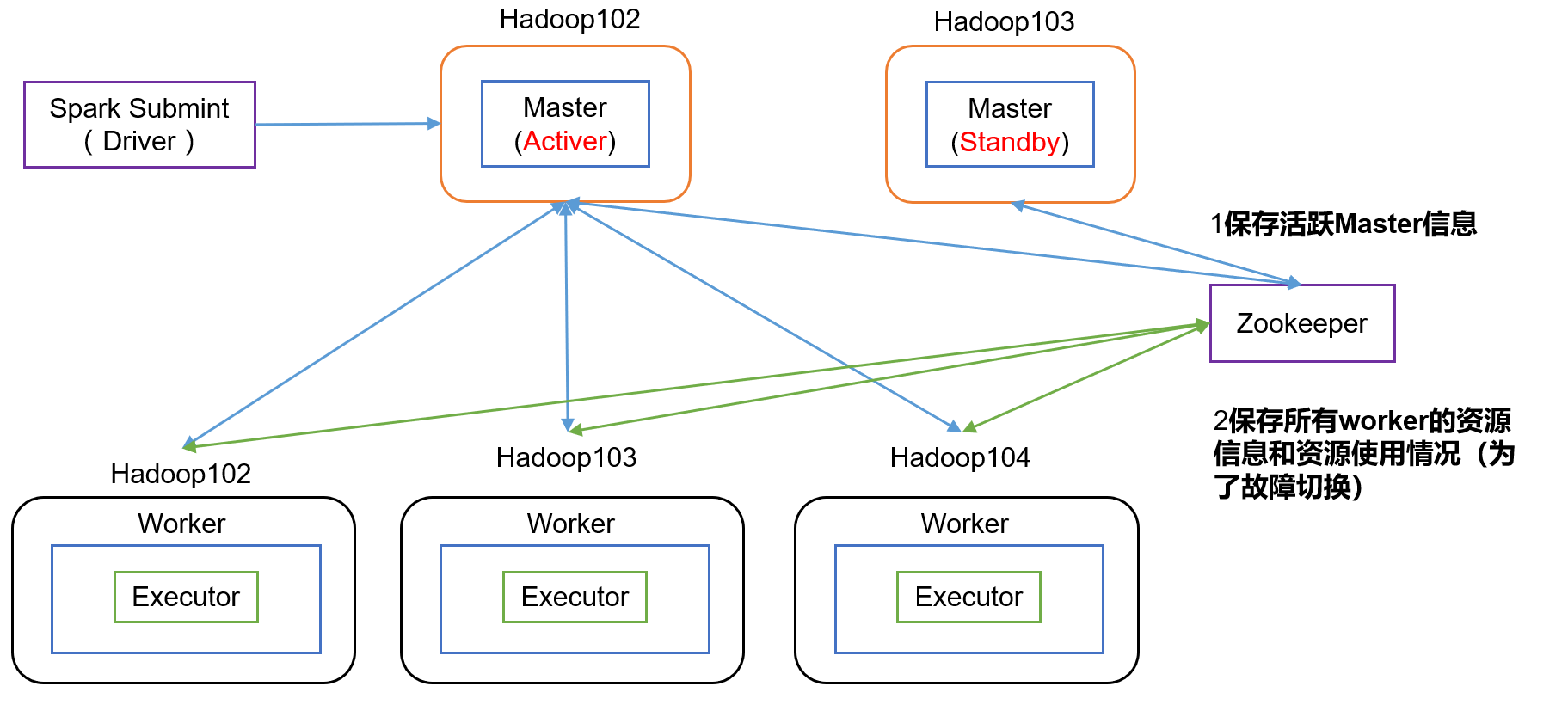
2)配置高可用
(0)停止集群
[atguigu@hadoop102 spark-standalone]$ sbin/stop-all.sh
(1)Zookeeper正常安装并启动(基于以前讲的数仓项目脚本)
[atguigu@hadoop102 zookeeper-3.4.10]$ zk.sh start
(2)修改spark-env.sh文件添加如下配置:
[atguigu@hadoop102 conf]$ vi spark-env.sh
#注释掉如下内容:
#SPARK_MASTER_HOST=hadoop102#SPARK_MASTER_PORT=7077
#添加上如下内容。配置由Zookeeper管理Master,在Zookeeper节点中自动创建/spark目录,用于管理:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER-Dspark.deploy.zookeeper.url=hadoop102,hadoop103,hadoop104-Dspark.deploy.zookeeper.dir=/spark"
#添加如下代码‘
#Zookeeper3.5的AdminServer默认端口是8080,和Spark的WebUI冲突
export SPARK_MASTER_WEBUI_PORT=8989
(3)分发配置文件
[atguigu@hadoop102 conf]$ xsync spark-env.sh
(4)在hadoop102上启动全部节点
[atguigu@hadoop102 spark-standalone]$ sbin/start-all.sh
(5)在hadoop103上单独启动master节点
[atguigu@hadoop103 spark-standalone]$ sbin/start-master.sh
(6)在启动一个hadoop102窗口,将/opt/module/spark-local/input数据上传到hadoop集群的/input目录
[atguigu@hadoop102 spark-standalone]$ hadoop fs -put /opt/module/spark-local/input/ /input
(7)Spark HA集群访问
[atguigu@hadoop102 spark-standalone]$bin/spark-shell \--master spark://hadoop102:7077,hadoop103:7077 \--executor-memory 2g \--total-executor-cores 2
参数:—master spark://hadoop102:7077指定要连接的集群的master
(8)执行WordCount程序
scala>sc.textFile("hdfs://hadoop102:9820/input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collectres0: Array[(String, Int)] = Array((hadoop,6), (oozie,3), (spark,3), (hive,3), (atguigu,3), (hbase,6))
3)高可用测试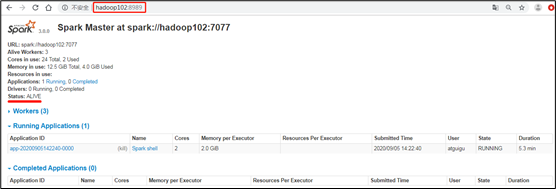
(1)查看hadoop102的master进程
[atguigu@hadoop102 ~]$ jps5506 Worker5394 Master5731 SparkSubmit4869 QuorumPeerMain5991 Jps5831 CoarseGrainedExecutorBackend
(2)Kill掉hadoop102的master进程,页面中观察http://hadoop103:8080/的状态是否切换为active。
[atguigu@hadoop102 ~]$ kill -9 5394
(3)再启动hadoop102的master进程
[atguigu@hadoop102 spark-standalone]$ sbin/start-master.sh
运行流程
Spark有standalone-client和standalone-cluster两种模式,主要区别在于:Driver程序的运行节点。
1)客户端模式
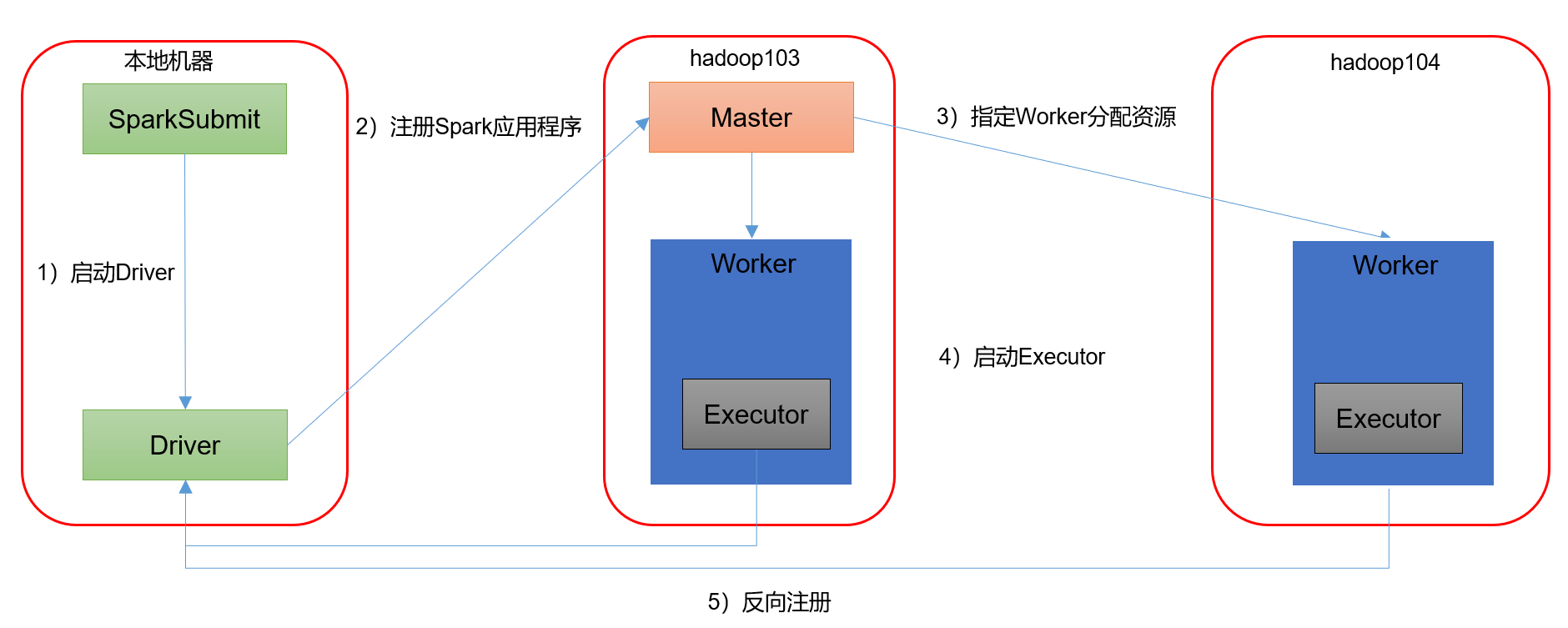
[atguigu@hadoop102 spark-standalone]$ bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://hadoop102:7077,hadoop103:7077 \--executor-memory 2G \--total-executor-cores 2 \--deploy-mode client \./examples/jars/spark-examples_2.12-3.0.0.jar \10
—deploy-mode client,表示Driver程序运行在本地客户端
2)集群模式模式
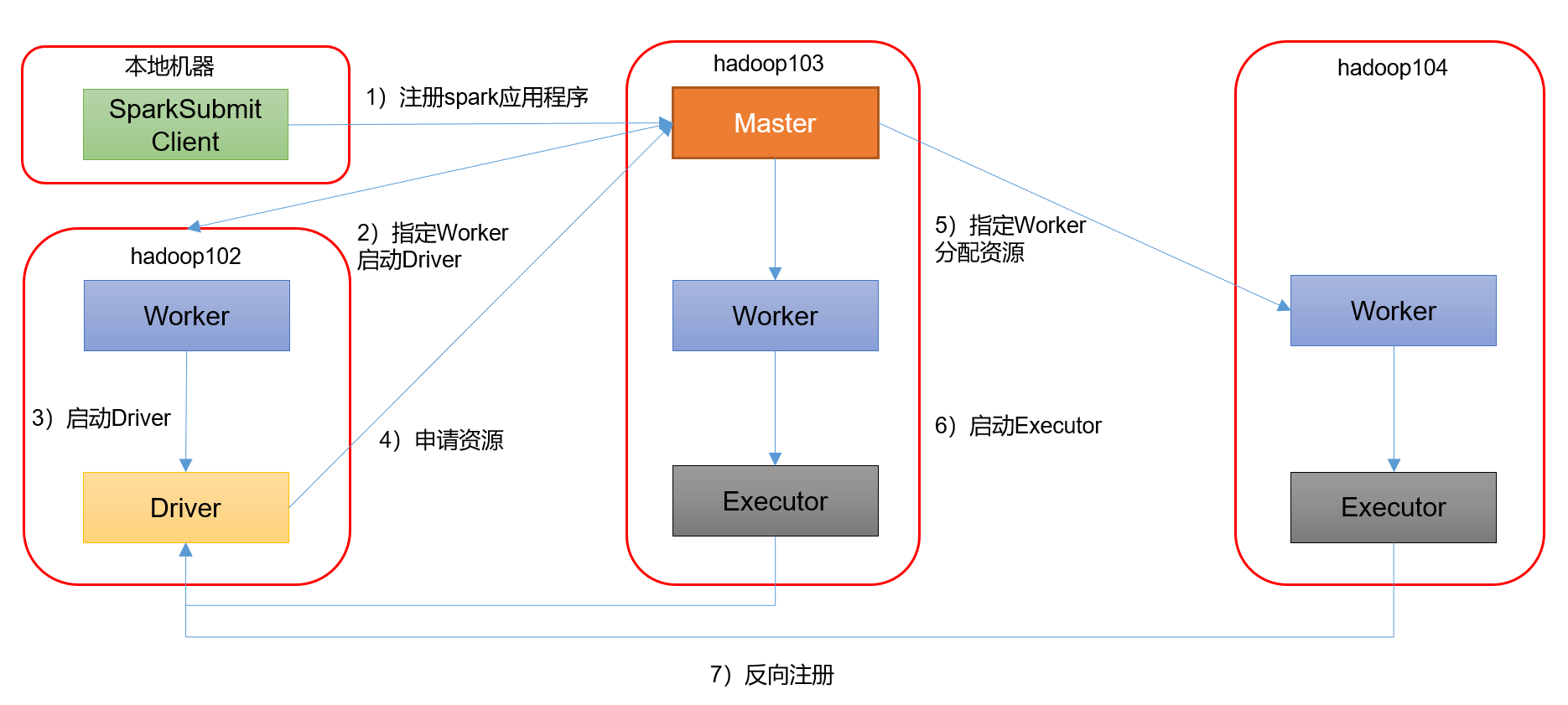
[atguigu@hadoop102 spark-standalone]$ bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://hadoop102:7077,hadoop103:7077 \--executor-memory 2G \--total-executor-cores 2 \--deploy-mode cluster \./examples/jars/spark-examples_2.12-3.0.0.jar \10
—deploy-mode cluster,表示Driver程序运行在集群
(1)查看[http://hadoop102:8989/](http://hadoop102:8989/)页面,点击Completed Drivers里面的Worker<br /><br />(2)跳转到Spark Worker页面,点击Finished Drivers中Logs下面的stdout<br /><br />(3)最终打印结果如下<br />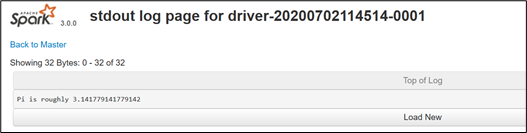<br />注意:在测试Standalone模式,cluster运行流程的时候,阿里云用户访问不到Worker,因为Worker是从Master内部跳转的,这是正常的,实际工作中我们不可能通过客户端访问的,这些端口对外都会禁用,需要的时候会通过授权到Master访问Worker

若有收获,就点个赞吧
0 人点赞
